Blog
[Google Cloud Platform] Cloud Dataflowでフルマネージドなデータ処理を試してみた
アドテクスタジオの佐々木です。
アドテクスタジオではデータ処理に力をいれておりOpenStack Sahara等を利用して共通基盤を構築しています。
今回はGoogle Cloud Platform が提供しているデータ処理のサービスのひとつである Cloud Dataflow についてみていきたいと思います。
Cloud Dataflow とは
Cloud Dataflow の説明は「ビッグデータのバッチおよびストリーミング処理を実現するフルマネージドのクラウドサービス。」となっています。
Google Cloud Platform にはCloud Dataflowとは別にSpark と Hadoop のマネージドサービスである Cloud Dataproc というサービスもあるのですが、これらはどのように違うのでしょうか?
Cloud DataflowをCloud Dataprocと比較してみると、以下の2点がCloud Dataflowの特長と言えるのではないかと思います。
フルマネージド
Cloud Dataproc ではSpark・Hadoop のクラスタを作成し、そのクラスタ上でジョブを実行します。ジョブが多くの処理能力を必要とする場合、ジョブが必要とする処理能力に見合う大きなクラスタを作成しておく必要があります。
一方、Cloud Dataflow ではクラスタやインスタンスを作成・管理する必要はなく、ジョブを実行すると必要なインスタンスが自動的に作成され不要になれば削除されます。
さらに、オートスケーリング機能を有効にしておけば、ジョブの実行中にインスタンス数を自動的に調整してくれるので必要なリソースを予測・用意しておく必要がありません。
GCPの他サービスとの連携
Cloud DataflowはCloud Pub/SubやBigQueryとの連携が非常に簡単です。Cloud Dataprocでも連携はできるのですが、Cloud Dataflowではより簡単でファイルの読み書きとほとんど同じ感覚でデータのやりとりをすることができます。
Cloud Dataflow を使ってみる
Java/Python SDKとscio
Cloud Dataflow には Java と Python の SDK があります。現在、Python SDK ではオートスケール、ストリーム処理等の機能が使えません。
また、Spotify が開発しているscioというツールを使ってScalaでCloud Dataflowのプログラムを書くこともできます。scioで作成したプログラムではJava SDKと同じ機能が使用可能です。
Cloud Pub/Sub & Cloud DataflowでWordCountする
今回は例としてCloud Storageからテキストデータを読み込み単語の出現数をカウントしてBigQueryに結果を保存するジョブを作ってみます。
(実際に動かす場合、インストールや必要な設定等はscioの Wiki を参照してください。)
具体的には、Cloud Storageからテキストを読み込みPub/Subに送信するInjectorとPub/Subからデータを読み込み単語の出現数をカウントしてBigQueryに結果を保存するWordCounterを作ります。全体の流れは下図のようになります。

WordCounterにストリーム処理をさせるためプログラムはscioで作成しました。
Injector.scala
- Cloud Storage からテキストを読み込む
- テキストを1行毎に分割して Cloud Pub/Sub に送信
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import com.google.cloud.dataflow.sdk.io.PubsubIO import com.google.cloud.dataflow.sdk.io.TextIO import com.google.cloud.dataflow.sdk.options.PipelineOptions import com.spotify.scio._ import com.spotify.scio.values.SCollection object Injector { def main(cmdlineArgs: Array[String]): Unit = { val (opts, args) = ScioContext.parseArguments[PipelineOptions](cmdlineArgs) val sc = ScioContext(opts) // 負荷を増やしたい場合はparallelを指定し同じジョブをいくつか同時に実行する for (i <- 1 to args.getOrElse("parallel", "1").toInt) { val input = SCollection.unionAll( // すぐ終わってしまう場合、repeatを指定して同じファイルを何度も読み込み入力量を増やす (1 to args.getOrElse("repeat", "1").toInt).flatMap( // inputで指定したファイルを読み込む _ => List(sc.applyTransform(TextIO.Read.from(args("input")))) ).toSeq ) input .filter(_.nonEmpty) .applyOutputTransform( // 行ごとにPub/Subに書き出す PubsubIO.Write.named("WriteToPubsub") .topic(args("topic")) ) } sc.close() } } |
WordCounter.scala
- Cloud Pub/Sub からデータを読み込み
- 行を単語に分割しタイムウィンドウごとの出現頻度をカウント
- BigQuery に結果を書き出す
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
import com.google.api.services.bigquery.model.{TableFieldSchema, TableSchema} import com.google.cloud.dataflow.sdk.io.BigQueryIO import com.google.cloud.dataflow.sdk.options.PipelineOptions import com.spotify.scio._ import com.spotify.scio.bigquery._ import org.joda.time.Duration import scala.collection.JavaConverters._ object WordCounter { def main(cmdlineArgs: Array[String]): Unit = { val (opts, args) = ScioContext.parseArguments[PipelineOptions](cmdlineArgs) val sc = ScioContext(opts) // BigQueryにデータを書き込むためのスキーマ val tableSchema = new TableSchema().setFields( List( new TableFieldSchema().setName("word").setType("STRING"), new TableFieldSchema().setName("count").setType("INTEGER"), new TableFieldSchema().setName("window_timestamp").setType("TIMESTAMP") ).asJava ) // Pub/Subからデータを取得 sc.pubsubTopic(args("topic")) // 1分のウィンドウで計測 .withFixedWindows(Duration.standardMinutes(1)) // 行を単語で分割 .flatMap(_.split("[^a-zA-Z']+").filter(_.nonEmpty)) // 単語の数を数える .countByValue .toWindowed .map { wv => wv.copy(value = TableRow( "word" -> wv.value._1, "count" -> wv.value._2, "window_timestamp" -> Timestamp(wv.timestamp))) } .toSCollection // 結果をBigQueryに追記 .applyOutputTransform( BigQueryIO.Write.named("WriteToBigQuery") .to(args("bqTable")) .withSchema(tableSchema) .withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED) ) sc.close() } } |
WordCounterを実行する
実行前の事前準備として、データ送受信用のPub/Subのトピックと結果を格納するBigQueryのデータセットを作成しておきます。
WordCounterは以下のコマンドで起動できます。
ストリーミングのジョブではデフォルトでオートスケールが無効になるためautoscalingAlgorithmを指定して有効にしています。
オートスケールを有効にする場合はmaxNumWorkersでのワーカーの数の上限設定も必須です。オートスケールによってインスタンス数は調整されますが、永続ディスクはジョブの開始時にmaxNumWorkersで指定した数だけ作成されるので注意してください。
|
1 2 3 4 5 6 7 8 9 |
$ sbt "run-main WordCounter --streaming=true ¥ --runner=BlockingDataflowPipelineRunner ¥ --autoscalingAlgorithm=THROUGHPUT_BASED ¥ --maxNumWorkers=<ワーカーの数の上限> ¥ --project=<プロジェクト> ¥ --stagingLocation=<実行に必要なファイルが置かれるCloudStorageのバケット gs://〜> ¥ --topic=<Pub/Subのトピック> ¥ --bqTable=<出力先のテーブルを「プロジェクト:データセット.テーブル」で指定> ¥ --zone=<ゾーン>" |
コマンドの実行結果に「Workers have started successfully.」というメッセージが出てくれば成功です。
Cloud Dataflowのジョブは下図のようになっています。

また、Cloud Dataflowが作成したインスタンスやディスクはGCEの管理画面からを確認できます。
作成されるインスタンスにはジョブ名が付いています。
次のようにPub/Subにメッセージを送信して、
|
1 |
$ gcloud beta pubsub topics publish <トピック> "Cloud Dataflow Test" |
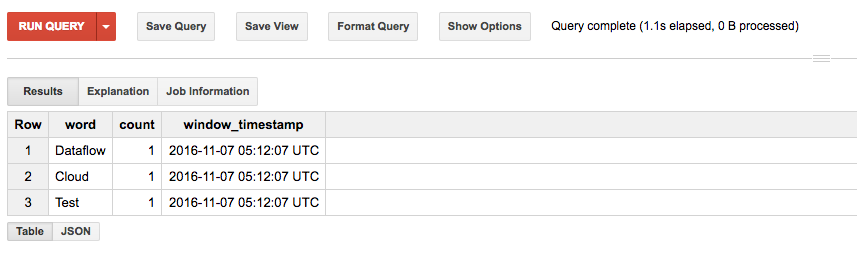
しばらくするとBigQueryにテーブルが作成されます。
中身をみると、期待通り単語で分割されてカウントされています。
Injectorの実行とWordCounterのオートスケール
WordCounerが正しく動いていることを確認できたので、Injectorを使ってより多くの行を送信してみましょう。
Injectorは以下のコマンドで起動できます。
|
1 2 3 4 5 6 7 8 9 |
$ sbt "run-main Injector --runner=BlockingDataflowPipelineRunner ¥ --input=gs://dataflow-samples/shakespeare/*.txt ¥ --repeat=10 ¥ --numWorkers=10 ¥ --parallel=10 ¥ --project=<プロジェクト> ¥ --stagingLocation=<実行に必要なファイルが置かれるCloudStorageのバケット gs://〜> ¥ --topic=<Pub/Subのトピック> ¥ --zone=<ゾーン>" |
実行するとCloudStorage上にあるシェークスピアのテキストを読み込みPub/Subへ送信していきます。
各テキストを1回送信するだけだとすぐに終了してしまうので、各テキストを10(repeat)*10(parallel)=100回送信しています。
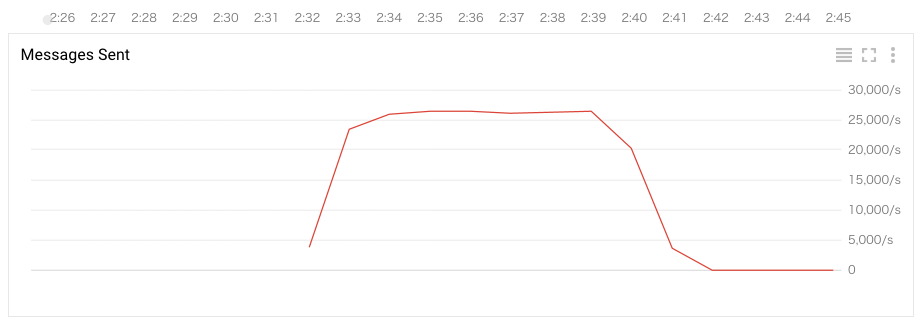
このとき、StackDriverで送信されたメッセージ数の推移をみると、2:32〜2:42の約10分間、最大で約26,000/sでメッセージが送信されていることがわかります。
これらのメッセージはWordCounterによってどのように処理されたのでしょうか?
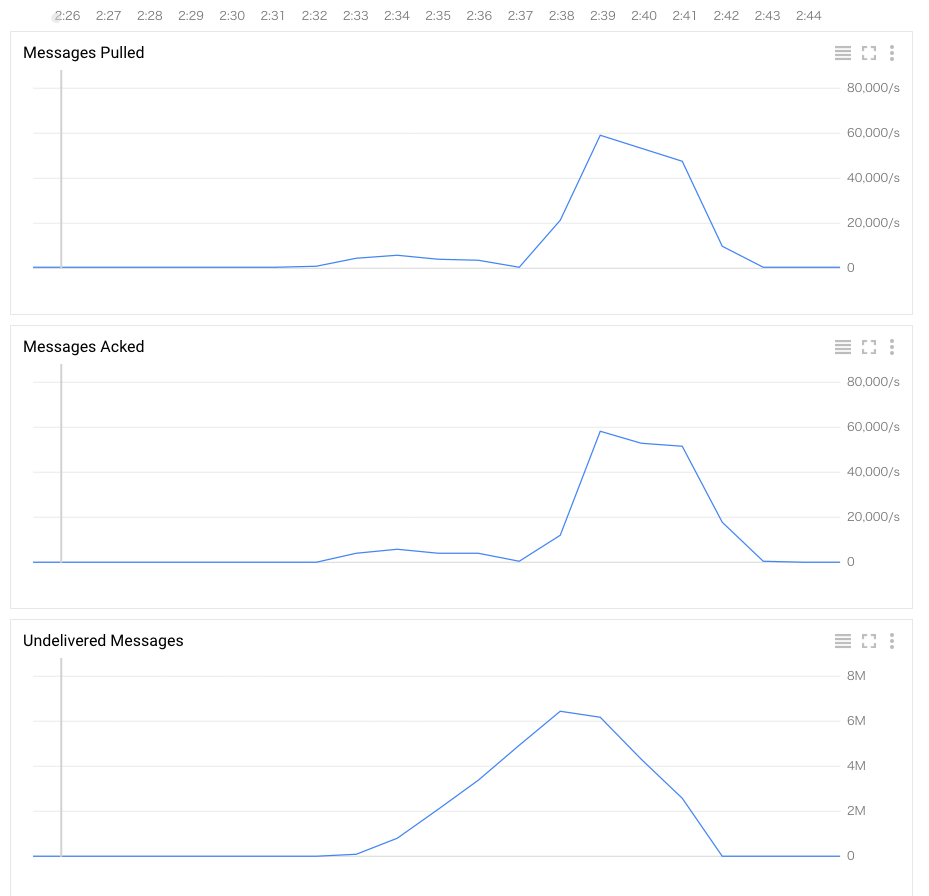
Messages Pulledの推移をみると2:37ごろまでは最大で6,000/s程度でしか処理できておらずUndelivered Messagesが増加しています。
2:37以降はMessages Pulledの値が急激に上昇し最大で60,000/s程度捌けており、4分ほどでUndelivered Messagesも0になっています。
StackDriverでWordCounterのインスタンスのCPU使用率をみると、オートスケールにより処理能力が向上した様子がよくわかります。
2:35あたりまではグラフの線が一本でインスタンス1台で処理していました。この時間帯はちょうど6,000/s程度でメッセージをさばいていた時間帯です。
2:35あたりで線の数が増え、2:37あたりからCPU使用率が増加しています。このタイミングでインスタンスが1台から10台に増やされています。インスタンスが10台に増えると1台の時の10倍である約60,000/sで処理できるようになっています。
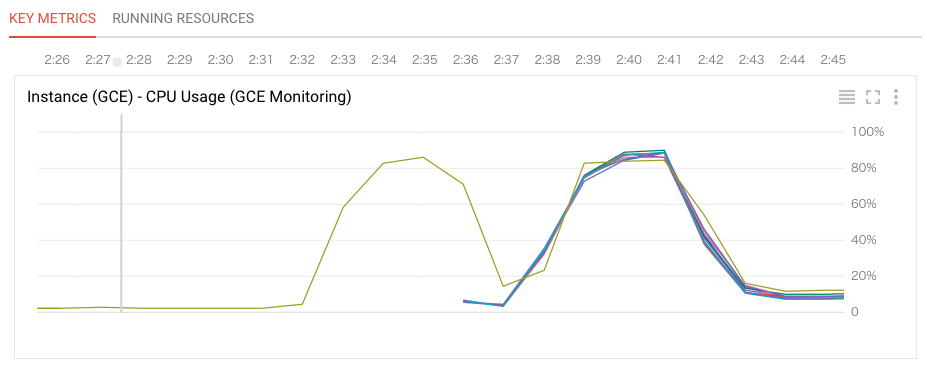
また、インスタンスを増やすだけでなく、負荷が低くなれば自動的にインスタンスを減らしてくれます。
Injectorの実行が終了してから放置しておくと、徐々にインスタンス数が減っていき約40分で再び1台になりました。
BigQueryのデータ確認
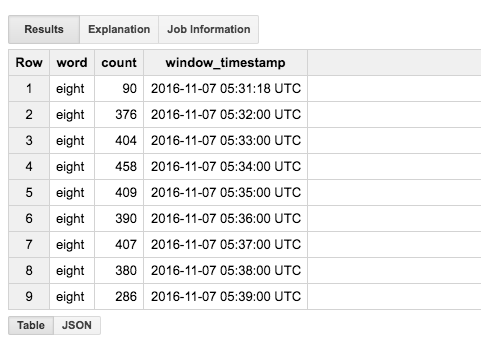
BigQueryで適当な単語の出現数を調べると下図のように複数行の結果が得られます。
window_timestampの値が1分ごとになっており、1分のウィンドウ毎に出現数がカウントされていることがわかります。
コストについて
Cloud Dataflowの料金はワーカーが使用しているvCPU、メモリ、ストレージに1分毎に課金されます。
https://cloud.google.com/dataflow/pricing-model
ジョブによってはワーカーのスペックやディスクサイズを調整することでコストを下げることができるかもしれません。
カスタムマシンタイプの料金と比べるとvCPUが高く、メモリが安いようです。永続ディスクの料金はほぼ同じようです。
最後に
ここまでみてきたように、Cloud Dataflowを使うことでインスタンスやクラスタの管理を意識することなくバッチ・ストリーム処理を実行することができます。
特に、GCPのサービス間でデータを加工・移動して連携するのには便利だと思います。
また、Cloud Dataflow のプログラミングモデルは Apache Beam プロジェクトとしてオープンソースになっています。Apache Beam で作成したプログラムは Google Cloud Dataflow だけでなく、Apache Flink や Apache Spark をバックエンドとして実行できます。まだ、開発途上ではあるようですが興味のあるかたはあわせてチェックしてはいかがでしょうか?
Author