Blog
DruidをBigQueryの代わりに使えないか試してみた
こんにちは。アドテクスタジオの和田です。
現在私の所属しているチームではBigQueryでアクセスログ分析を行っているのですが、コスト問題、アドホックなクエリを実行したい、大量join時の待ち時間など運用上の課題を幾つか抱えていました。
そこで代替手段を探していたのですが、Druidというデータストアがあることを知ったので課題をDruidで解決できないか検証してみました。
Druidとは
OLAP向けのデータストアです。データソースとしてS3, GCSのようなFileベースのデータに加えてkafkaなどのstreamingデータも扱うことができます。
Druidのアーキテクチャ
Druidは以下のコンポーネントで構成されます。
- Coordinator Node
- セグメント管理ノード
- セグメントはHistoricalノード上で管理されているが、古いセグメントの削除や負荷分散などの管理を行う
- Historical Node
- セグメントを実際に持ち、ロードなどを行う
- Indexing Service
- セグメント生成ノード。以下コンポーネントをまとめて Indexing Service と呼ぶ
- Overlord:データ取り込みのリクエストを受け付けるエンドポイント
- MiddleManager:Peonを管理する
- Peon:taskを実行する。taskとはデータロードしてセグメント生成する一連の処理
- セグメント生成ノード。以下コンポーネントをまとめて Indexing Service と呼ぶ
- Broker Node
- queryを受け付け、読み込み対象となるセグメントを持つノードへルーティングを行う
- Realtime Node
- リアルタイムインデックスを提供する
- セグメントを生成してHistoricalノードに保存する
- Zookeeper
- セグメント情報などの管理用
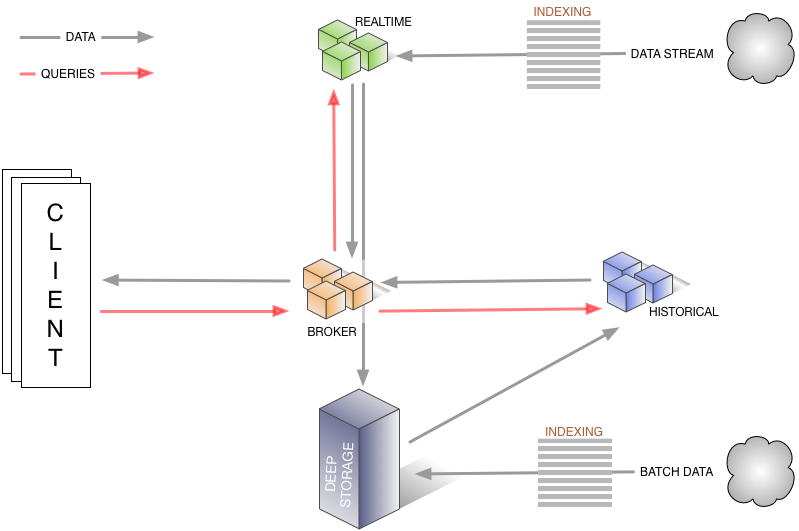
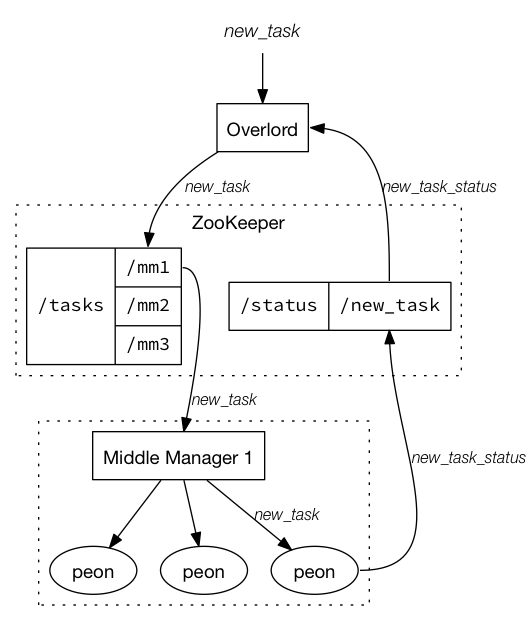
※引用: http://druid.io/docs/0.11.0/design/indexing-service.html より
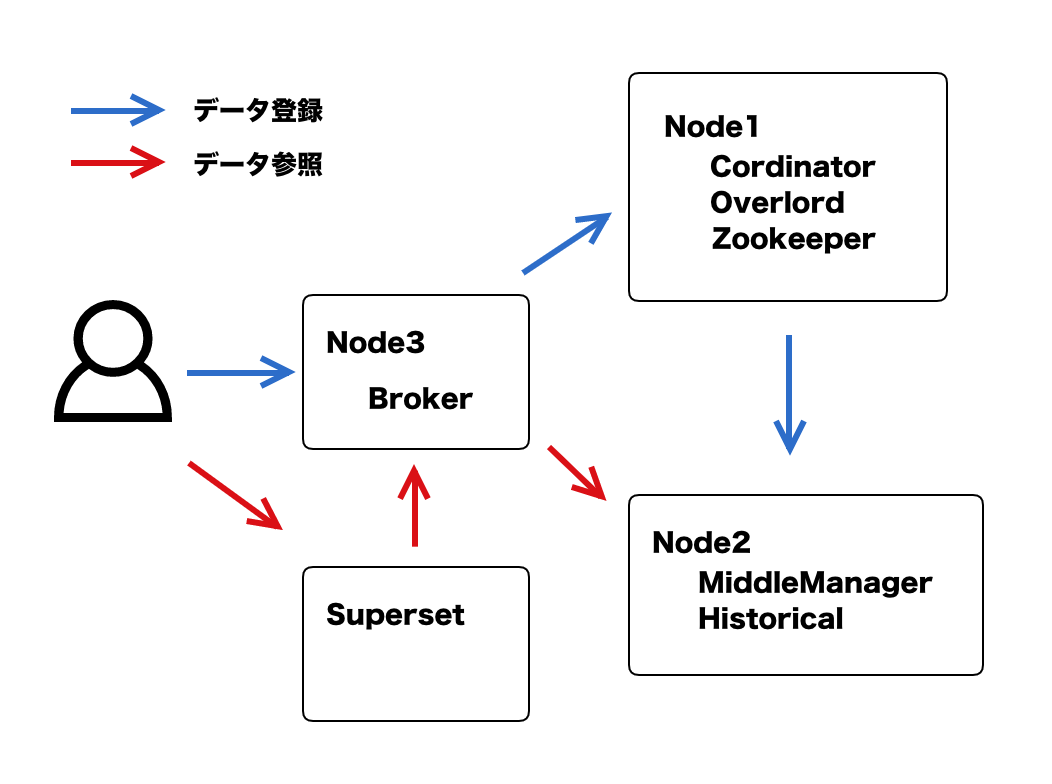
検証構成
以下のインスタンスを用意し、quickstartを参考に各コンポーネントを起動します。
- Node1 2vCPU / 8GBmem
- Coodinator
- Overlord
- Zookeeper
- Node2 8vCPU / 48GBmem
- MiddleManager
- Historical
- Node3 2vCPU / 8GBmem
- Broker
- 可視化用
- superset Node
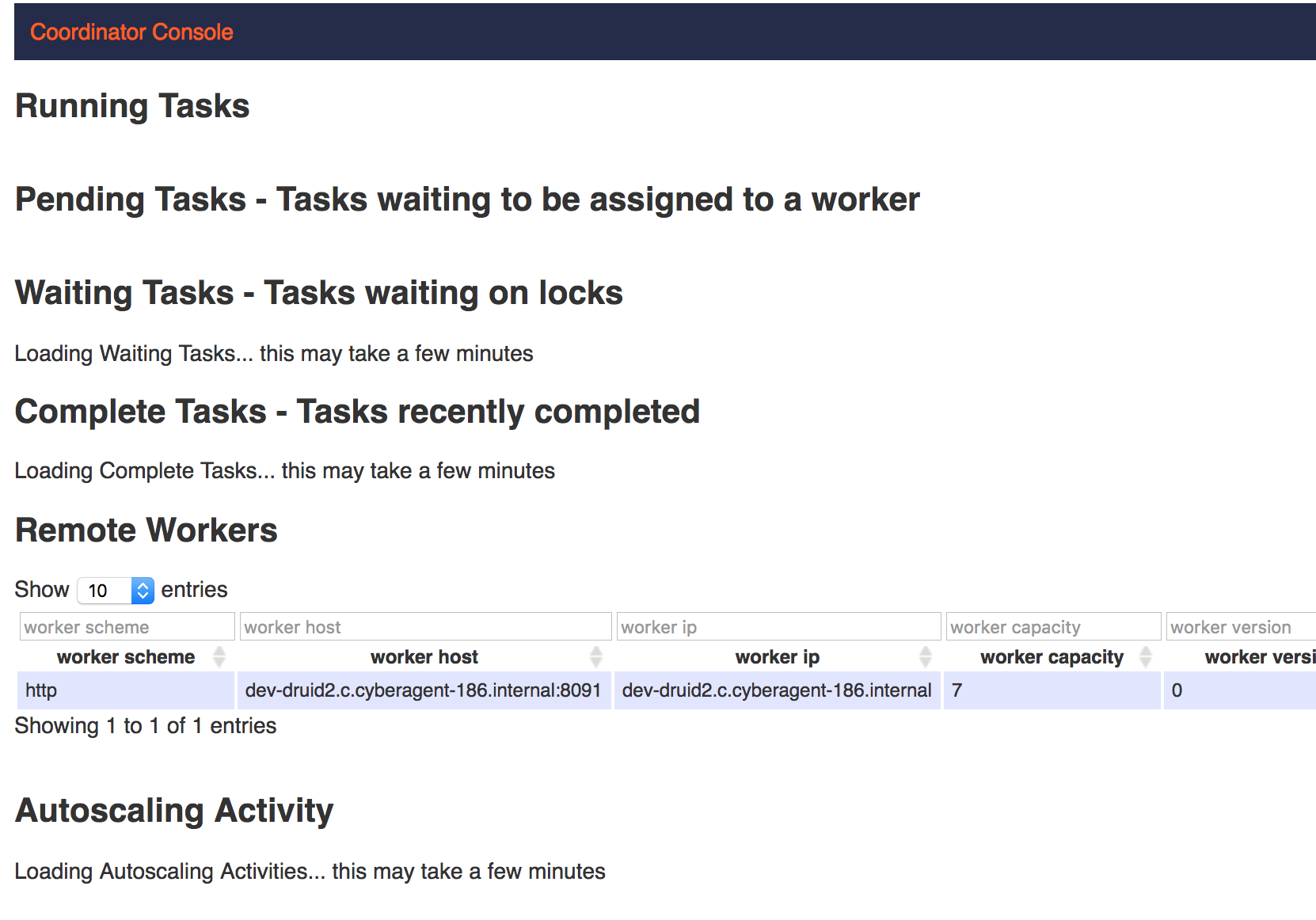
Coodinatorプロセスが8090ポートをLISTENしているのでブラウザからアクセスするとタスク状況が確認できます。
http://Node1:8090/console.html
データロード
データロードは上記にもあったtaskという単位で管理します。
定義ファイルをjsonで記述してOverlordプロセスへHTTP POSTすることでtaskを登録できます。
taskのtypeは以下のようになります。
- index
- 小さなデータセット向けの取り込みタスク。大きいものはindex_hadoopを使う
- firehoseというデータロード向けのコンポーネントを利用する
- ローカルファイルやhttp、既存セグメントのcombineタスクなどが定義できる
- 外部extension(jar)を使うことでS3 / GCSデータロードを実現する
- Hadoop
- 大きいデータセット向けの取り込みタスク
- 取り込み元ファイルの拡張が難しい?(firehoseのようなextensionはありませんでした)
- ローカルファイル / S3はロードすることができる。
- http://druid.io/docs/latest/ingestion/batch-ingestion.html
- 以下のようなタスクもある
- append / merge / same_interval_merge / kill / noop
データロード検証
index (GCS firehose)
druid-google-extensionsをインストールし、GCS firehoseでGCSからデータロードするindexタスクを定義します。
以下のjson定義をOverloadプロセスにPOSTで登録することでgzip圧縮済みのアクセスログを1日分ロードしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
{ "type": "index", "spec": { "ioConfig" : { "type" : "index", "firehose" : { "type" : "static-google-blobstore", "blobs": [ {"bucket": "test-druid-store", "path": "test/deployment.2018-01-29_00.log.gz"}, {"bucket": "test-druid-store", "path": "test/deployment.2018-01-29_01.log.gz"}, ...ロードファイル数分記述... ] } }, "dataSchema" : { "dataSource" : "test", "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "day", "queryGranularity" : "none" }, "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "id", "time", "reqid", "uid", "os_version", "processing_time" ] }, "timestampSpec" : { "format" : "auto", "column" : "time" } } }, "metricsSpec" : [ { "name" : "count", "type" : "count" } ] }, "tuningConfig" : { "type" : "index", "maxRowsInMemory": 750, "targetPartitionSize": 100000 } } } |
task完了まで7時間程度かかりました。。データサイズは 750MB程度でした。
|
1 2 |
root@Node2:~/druid-0.11.0# du -sh var/druid/segments/test/ 755M var/druid/segments/test/ |
index_hadoop
次に index_hadoop type でのデータロードで高速化できないか試してみます。
firehoseは利用できなかったので、node2サーバにgsutil cpでgzファイルをコピーしておいてstatic typeでロードしました。こっちはワイルドカード使えて良いですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "type": "index_hadoop", "spec": { "ioConfig" : { "type" : "hadoop", "inputSpec": { "type": "static", "paths": "file:/mnt/disks/druid/gcs/*/*.log.gz" } }, "dataSchema" : { "dataSource" : "all-hadoop", "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "day", "queryGranularity" : "none", "intervals": ["2018-01-29/2018-02-03"] }, "parser" : { "type" : "hadoopyString", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "id", "reqid", "ip", "os" ] }, "timestampSpec" : { "format" : "auto", "column" : "time" } } }, "metricsSpec" : [ { "name" : "count", "type" : "count" } ] }, "tuningConfig" : { "type" : "hadoop", "numBackgroundPersistThreads": 1 } } } |
動作を見ていたところLocalTaskRunnerのようなプロセスが1つだけ起動され、1ファイルずつMapReduceが走っていたため高速化は期待できなさそうです。
ちゃんとHadoopクラスタを用意して、DeepStorageもLocalではなくHDFSにすることでスケールできそうです。
課題
データロードが遅い
ロード検証の通り、通常のindex typeでは遅すぎると感じました。
index_hadoop typeでGCSからロードしてHDFSをDeepStorageとすればよさそうですが、GCSからのロードは作り込みが必要そうです。(S3はいけそう)
また、Druidクラスタ + 別途Hadoopクラスタを用意するとなるとかなり大掛かりになってしまいます。
1 peon : 1 taskの処理しか行わないようなので、1taskの処理をスケールさせようと思うとMapReduceを利用するのが良さそうです。
DeepStorageのロケーション
デフォルトのLocalだと、MiddleManagerホストのディスクにセグメントと呼ばれるデータロード済みのデータが保存されます。
複数台ある場合だとtaskを担当するpeonが動いているノードにのみ保存され、分散されません。
GCS, HDFSをDeepStorageとしないとスケーラビリティがありません。
joinができない
残念ながらテーブル間のjoinはサポートされていません。
全結合したデータを1テーブルにロードするような形で実現するのが良さそうですが、データロード時にjoinすることはできませんでした。
updateはDruidでサポートされていますが、特定のkeyのjsonを作ってPOSTする形なので、既存テーブルに対して今回ロードするgzファイルの特定キーを元にupdate(merge)する、というのは実現できなさそうでした。
1つのテーブルに複数ログの全カラムを用意して全データをロードしてみましたが、マージ処理はできないため全レコードがロードされます。
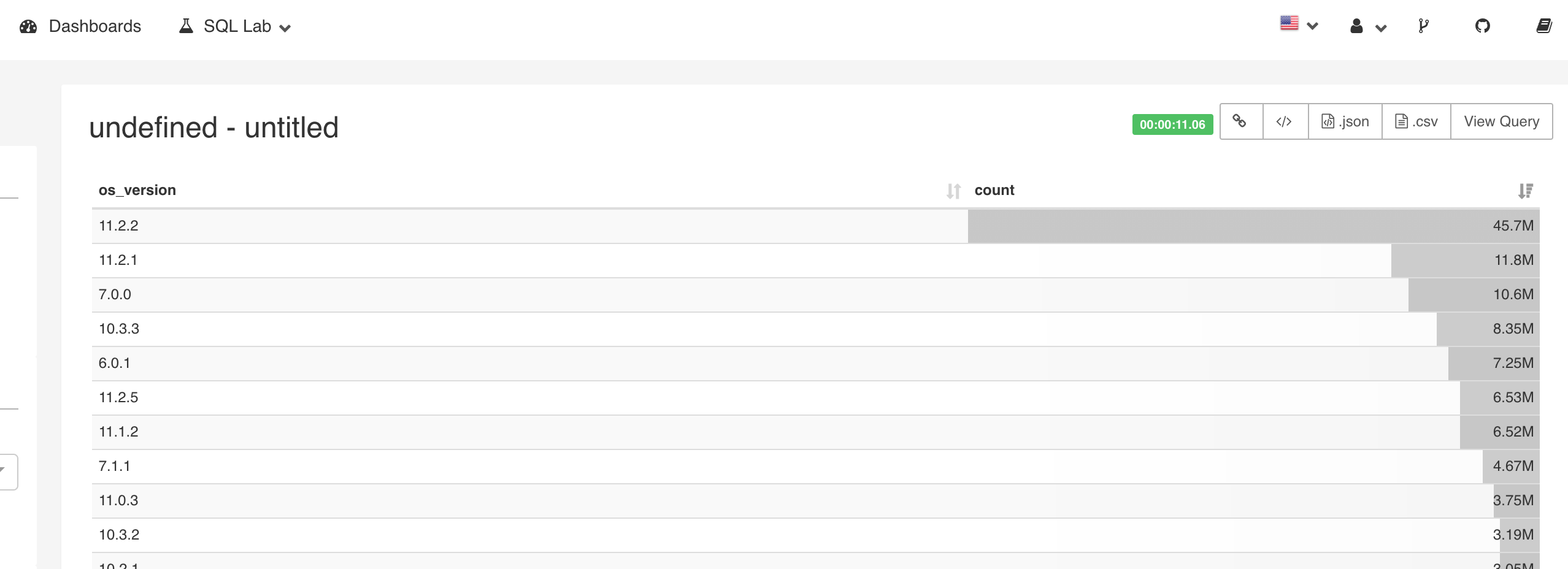
可視化
Druidに対応しているSupersetで可視化しました。SupersetにBrokerノードのインターフェースをセットすると、Superset側でDruidメタデータからスキーマ定義など読み込むことができます。
クエリは書けないため、Dimensionでのgroup byができるくらいです。
値を使った演算が必要なものはログに含める or task定義のメトリクスとして記述する必要があり、supersetのGUIからはできませんでした。
まとめ
というわけで、BigQueryによる分析の代替手段としてDruidを検証してみましたが750MB程度のデータロードに7時間程度かかってしまい、Druidクラスタ単体での運用は厳しいと判断せざるを得ませんでした。また、joinもできないため事前にデータ整形が必要となり、今のアーキテクチャでは運用コストが高そうです。
次回はDruidクラスタ + Hadoopクラスタで本格的な大規模データ処理も試してみたいと思っています。
Author