Blog
[CVPR Workshop] Automatic Understanding of Visual Advertisementsコンペティション解説
6月にアメリカ、ソルトレイクシティでコンピュータービジョンの主要な国際会議であるCVPRに参加してきました.3日間の本会議では6,000人を超える参加者が集まり、最新の成果について900件以上の研究発表がありました.CVPRでは本会議に加え、多数のワークショップも開催されています.今回はCVPR併設ワークショップのTowards Automatic Understanding of Visual Advertisements (ADS)に参加しました.広告画像の研究に関するワークショップで、広告画像の意味内容理解や広告製作支援技術に関する研究発表や講演があり、コンピュータビジョンに限らず広範な分野の研究者が集まり、議論を交わしました.サイバーエージェントAI Labからはポスター発表一件のほか、コンペティションで1位を獲得し、winner talkでの登壇がありました(発表資料).本記事ではコンペと開発した手法の技術詳細について解説します.
Automatic Understanding of Visual Advertisementsタスク概要
今回のコンペの課題は与えられた広告画像に対して、正しい説明文を選択するmultiple choice問題です.15個の説明文候補があり、そのうち3個だけが正しい文です.各画像について1つ説明文を選び、正答率で評価します.

問題例.正解説明文は緑で強調しています.
データセットでは以下のような画像が提供されています.

基本的にデザイナーが作成した画像です.イラストなども多数含まれています.また視覚的な比喩を使ってメッセージを表現している広告も多く、画像からの意味内容理解としては大変難しいデータセットです.
OCRを用いた広告画像説明文の関連度推定
アイディア
今回私たちのチームは画像に加え、文字認識技術(OCR)を使ってこの問題に挑戦しました.広告画像はテキストを含むことが多く、さらにテキストには重要な情報が明示的に記述されています.例えば、ブランド名や商品の具体的なアピールポイントなどはこのタスクを解く上で強力なヒントになります.
モデル概要
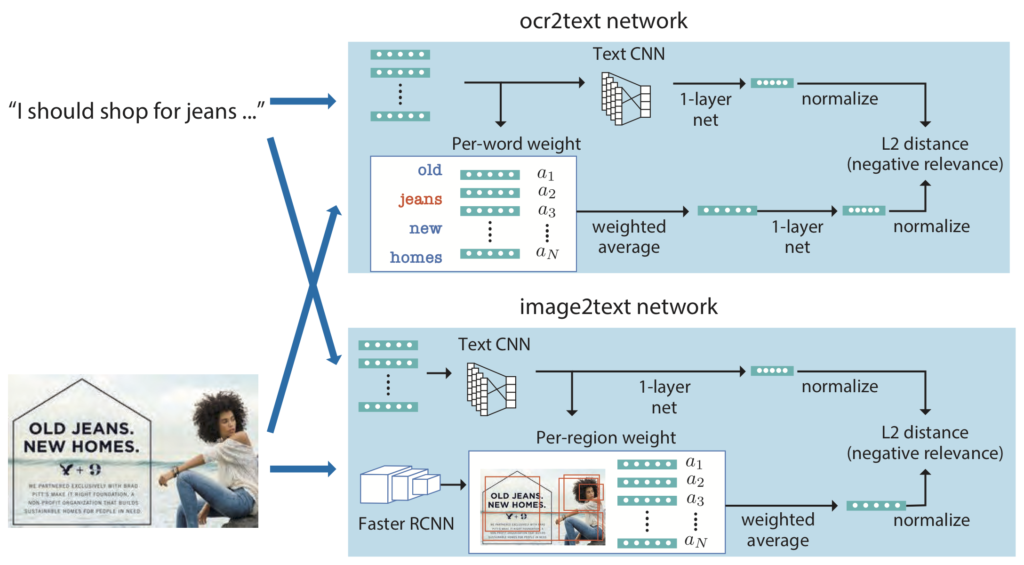
ここからは具体的に開発したモデルについて説明します.このモデルでは入力広告画像と説明文の関連度を推定します.関連度に基づき15個の説明文を順位付けし、最も関連度が高かったものを回答とします.このモデルは主に2つのコンポーネントで構成されています.1つ目は説明文とOCRで検出した単語の関連度を推定するtext2ocrモジュールです.ニューラルネットワークを用いて説明文とOCRで検出した単語群をそれぞれ特徴ベクトルに変換し、その距離を計算します.距離が近いほど関連度が高いとみなします.
OCRで検出した単語の中には重要でないものも多数含まれています.そこで説明文中の単語とOCRで検出した単語の意味の近さを計算し、重要そうな単語だけを反映した特徴量を抽出します.
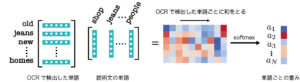
具体的には図のように各単語をword2vecを用いたベクトル表現にします.次に説明文とOCRで検出した単語ベクトルの内積を計算し、OCRで検出した単語ごとに和をとります.最後にsoftmaxをとり単語ごとの重みとします.このとき単語のベクトル表現の重み付き和をOCR結果の特徴ベクトルとしています.このOCR結果に対する特徴抽出は単純なモデルですが、今回のデータセットでは広告画像のテキストと同じ語を使った説明文が多いためこれでもそれなりに機能します.
text2imgモジュールでは説明文と広告画像の視覚的な特徴から関連度を推定します.説明文はtext2ocrモジュールと同様CNNで特徴ベクトルに変換します.画像特徴抽出にはFaster RCNNを使います.Faster RCNNで複数の画像領域から特徴ベクトルを抽出し、説明文を使って領域ごとのattentionを計算しています.今回はattentionを使った画像領域の重み付き和を広告画像の視覚的な特徴としています.
前処理
このデータセットの説明文はactionとreasonで構成されています.actionは広告を見た人が「何をすべきか」、reasonは「なぜそうすべきか」を説明する文です.例えば「I should buy Old Navy jeans Because they make you feel like a Rock star」では、「I should buy Old Navy jeans」がaction、「they make you feel like a Rock star」がreasonです.actionとreasonは広告画像の異なる側面に着目しています.actionは広告に表示されている商品に関連する記述が多くなります.reasonなら広告の雰囲気や比喩表現を解釈したより高度な意味を記述しています.そこで、今回は説明文をこのactionとreasonに分割して別々のモデルを学習します.さらに入力文が短くなることで学習が容易になることが期待できます.
結果
いくつか推定結果を載せます.広告画像の右に選択された説明文とOCRで検出された単語を表示しています.また各単語の重みは色で可視化しています.青は低い値を、赤は高い値を表しています.

国際環境NGO Greenpeaceの地球温暖化に関する啓発広告です.正しい説明文が選ばれています.画像右上のテキストのうち「greenpeace」、「miss」が強調されているのが確認できます.

ビールの広告.ビールに関する単語が相対的に強調されているのがわかります.
考察
この広告画像データセットでは、画像に含まれるテキストが説明文の選択において強力なヒントとなっています.そこでOCRの性能が最終的な正答率にどれほど影響を与えるかを調べてみました.コンペではGoogle Cloud Vision OCRを使用しましたが、ここでは比較のためTesseract OCRを使い再度モデルを学習しました.

同じ広告画像に対してTesseract OCRとGoogle Cloud Vision OCRを適用した結果です.Google Cloud Vision OCRの方がより多くの単語を正しく認識できています.
| Google Cloud Vision | Tesseract | |
| Precition@1 | 0.85 | 0.54 |
上の表はGoogle Cloud Vision OCRとTesseract OCRを使った正答率の比較です.ただしvalidation setでの評価です.これまでの結果からtest setでの評価と大きな差は無いと考えられます.Tesseract OCRを使った場合、正答率が大幅に下がっており、最終的な正答率はOCRの性能に強く依存していることがわかります.
| OCR2text (OCRのみ) | OCR2text + img2text (full model) | |
| Precision@1 | 0.83 | 0.85 |
またこのタスクにおけるOCRと画像特徴の影響を調査しました.ocr2textのみを用いた場合の正答率は0.83、画像特徴も取り入れた場合は0.85となり、わずかに改善されていますが、このタスクにおいて画像特徴はあまり有効ではないようです.OCRのみを用いた場合でも正答率は8割を上回っており、この問題の多くは画像中のテキストを読み取ることで解けるものになっているということがわかります.
まとめ
今回CVPR workshopの広告画像理解のコンペに参加し、OCRを用いた手法で正答率1位を獲得することができました.広告画像理解は、視覚的なメタファーの解釈や、画像から想起される感情の推定など、コンピュータビジョンの問題として面白いサブトピックを含んでいます.しかし、今回のコンペでは広告画像のテキストを読むことで、正解説明文を当てることができるという結果になりました.この結果から、タスク及びデータセットのデザインと本来の研究目的との隔たりが明確になったように思います.現在のデータセットでは画像中のテキストから得られる情報が強すぎるように思います.これに対しては、テキストを除去するするなどの処理で画像理解の側面を強調することができるかもしれません.以上、簡単にですが今回のコンペで開発した手法と結果を説明しました.実装をGitHubで公開しているので、詳細についてはそちらをご参照ください.
Author