Blog
AirTrack 内定者アルバイト 「広告ログ集計基盤をSnowflakeへの移行による集計プロセスの改善」
はじめに
初めまして、22卒エンジニア職内定者の松岡穂高と申します。
2021年6月1日から3ヶ月間、サイバーエージェントのAI事業本部にあるAirTrackという部署で、サーバーサイドの内定者アルバイトをさせていただきました。
今回は振り返りの意味も兼ねて、取り組んだ内容と学んだ事や知見について書き記したいと思います。
AirTrackとは

AirTrackとはAI事業本部の小売DX本部に位置し、スマートフォン端末から取得できる位置情報を活用し来店計測や広告配信を行うサービスを展開しているプロダクトです。位置情報を使って顧客属性を推測しターゲティングを行なっており、「人を動かす広告をつくる」ことを目指しています。
今回は、DSPと呼ばれる広告主向けの広告配信プラットフォームの開発に携わりました。DSP及びアドテクに関する詳しい解説はこちらの記事に書かれています。興味のある方はぜひご覧ください。
今回の目標
まず、今回AirTrackで働くにあたって成し遂げたいことは以下でした。
- 大規模なデータを扱い、パフォーマンスチューニングができるようになりたい
- 何かしらのビジネスインパクトを与えたい
学生レベルでは、どうしても事業目線で開発・運用を行う機会はないので、この内定者アルバイトではできる限り社員の方々と同じような視座を持つことを意識して取り組みました。
開発言語に関しては自分自身、特にこだわりはなく、プロダクトに適した言語を選定し利用できるのが望ましいと考えています。理由としては、サーバーサイドの言語はトレンドが激しく、現在使用している言語が必ずしも将来のデファクトスタンダードであり続けるとは限らないからです。そのため、一つの言語に固執したくない、今まで触れてこなかった技術にも触りたいと思い、Scalaでのサーバーサイドやインフラレイヤーの実装に挑戦しました。
AirTrackで行ったこと
今回私がメインとして行ったことは、既存の広告ログ集計のシステム基盤をSnowflakeに移行するというタスクでした。SnowflakeとはSnowflake社が提供するクラウド型データウェアハウスです。この移行によって、運用コストの削減、集計プロセスの安定化、より信頼性の高いモニタリングや精度の高いCTR予測が可能になり、もともと私が成し遂げたかった「大規模データを触りたい」「ビジネスインパクトを与えたい」という目標が達成できると考えました。テーブルの移行自体はクエリを書くだけで簡単でしたが、移行したテーブルが元のテーブルと同等の内容になっているか(join や where などの集計処理が等しいものになっているか)という精度の評価で苦戦し自身の成長にもつながる部分でした。この検証の部分に力を入れていたのでこのブログで紹介していきます。
精度検証と評価
まずは、試験的にSnowflakeで新しいテーブルを作成し、既存のものと同等の精度であるかを検証します。両者のテーブルから8月の1ヶ月間でデータを絞り込み、1日ごとにグループ化します。そして、既存テーブルと今回作成した新規テーブルから日ごとのidの数を算出し、抽出したcount数から両者の差分の割合を算出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
WITH new AS ( SELECT DATE_TRUNC(DAY, requested_at) AS date, COUNT(id) AS count FROM new_table_log WHERE requested_at BETWEEN '2021-08-01' AND '2021-09-01' GROUP BY 1 ORDER BY 1 ), old AS ( SELECT DATE_TRUNC(DAY, requested_at) AS date, COUNT(id) AS count FROM old_table_log WHERE requested_at BETWEEN '2021-08-01' AND '2021-09-01' GROUP BY 1 ORDER BY 1 ) SELECT old.date, old.count AS old_count, new.count AS new_count, new_count / old_count AS rate, new_count - old_count AS difference FROM new FULL OUTER JOIN old ON new.date = old.date ORDER BY 1 ; |
以下は、SnowsightというSnowflakeのデータ結果をグラフで可視化するツールを使用し、検証結果をグラフ化したものになります。この結果から、ほとんどの差分率が1.0に近い範囲に収まり、既存のデータと新しく作成したデータがほとんど一致している事が示されました。
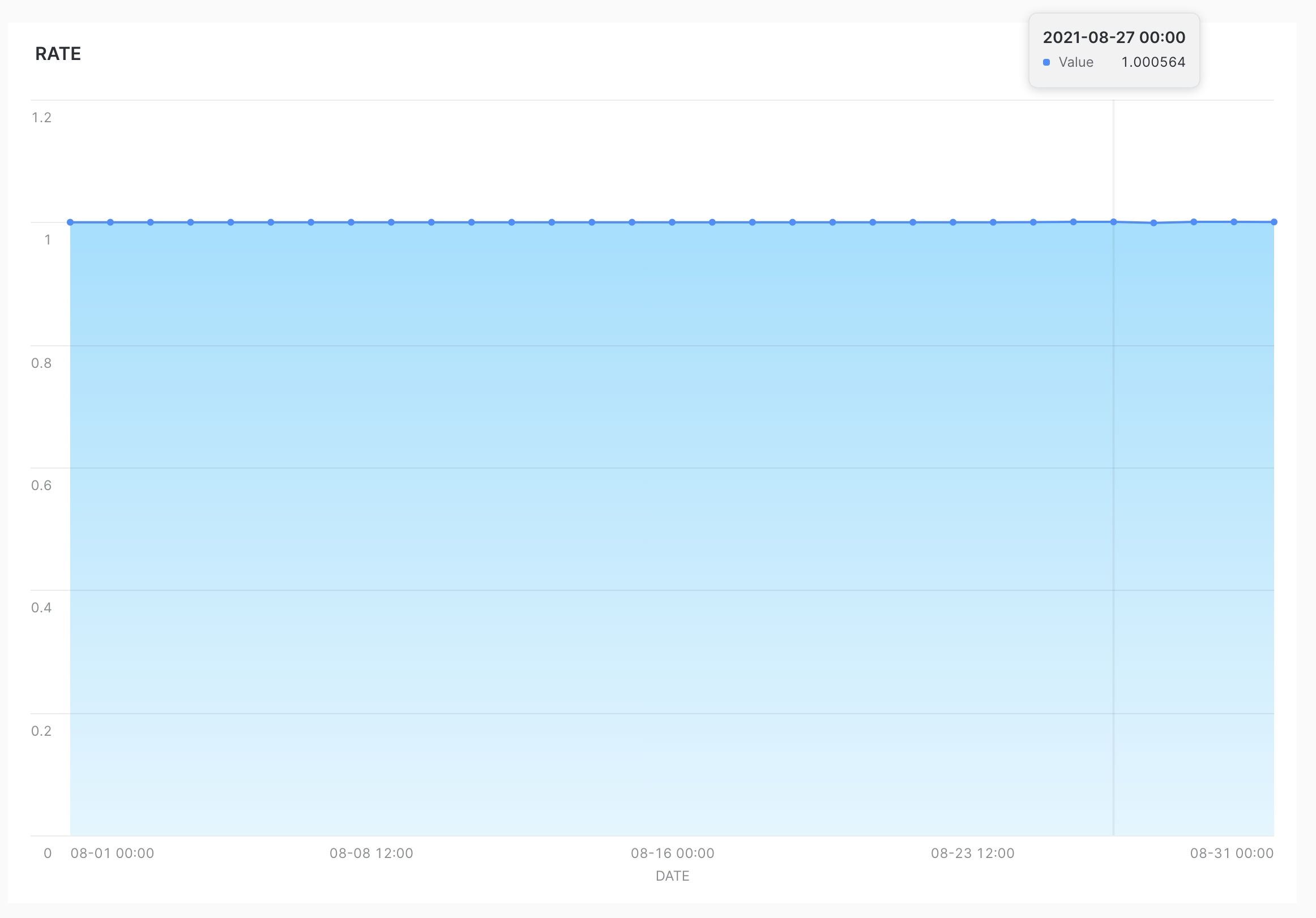
新旧のレコード数の差分率を表したグラフ(8月)
実装
検証結果を評価した後は実装に入ります。試験的に作成したクエリが先程の検証で精度的に適正であることが証明されたので、これを定常的に作動させます。今回は、CloudWatch Eventsで定刻になればECSタスクを実行するようにしました。また、インフラ構築はAWS CDKを用いてクラウドアプリケーションリソースを定義しました。
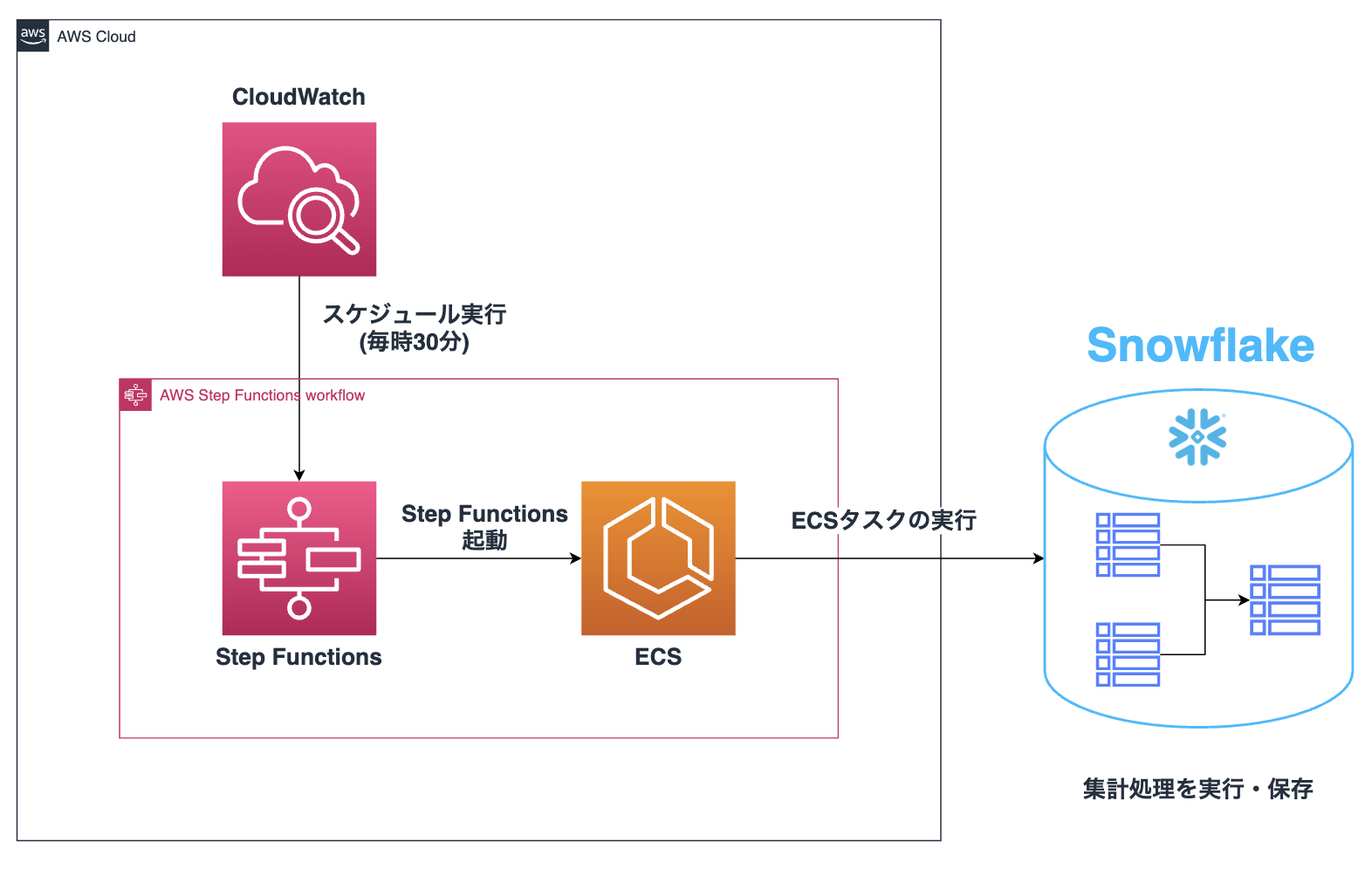
学び
技術力も含めて設計力の大切さ
まず何よりもこの内定者アルバイトで学んだことは、設計の大切さです。AirTrackに来てまず驚いたことは、要件定義・システム設計のドキュメントの多さでした。私自身、これまでシステム設計を行わずに最初から実装ということが多々あったため、設計に対するスキルは皆無でした。実際に設計のレビューを社員の方々に見てもらい、改めて認識の齟齬があったり、より効率的で効果的な実装方法を提案してくださったりしていただきました。実現したい事を達成するために、どのような技術を用いて、どのように課題解決へとアプローチするかという方法を考え、文書に落とし込むことは簡単そうに見えてとても難しかったです。
仮説検証の重要性
次に学んだことは、仮説検証の大切さです。実装したものが果たして、どのような効果をもたらし、何がボトルネックであるかを明確にする必要がありました。
今回は特にSQLを使ってデータを集計することがメインでした。既存のものと刷新したデータベーステーブルを比較し、レコード数やデータの欠損率を計測。そして仮説検証を行い原因追求の繰り返し行う。そのようにして課題解決を行なっていくという経験ができたのは、私自身にとって大きな成果だと思います。少ないデータ量であれば、数字を出さなくとも、実際目で見て比較すれば良い話ですが、億を超えるレコード数を扱うため、欲しい結果を得るためのクエリを書くことは難しかったです。大規模なデータを扱えるのはとても楽しく、広告事業ならではの醍醐味だと感じました。
さいごに
このメインのタスク以外にも、サーバーサイドの開発ではScalaに挑戦しました。関数型言語は扱ったことがなく、慣れない概念が多くて難しかったですが、エンジニアとしてのレベルをより一層高めることができたと思います。また、個人開発ではなかなか使用する機会がないAWSのサービスを扱えたのも貴重な経験だと思います。
今回は、私自身初めて内定者アルバイトをさせていただきました。参画当初はとても不安でチームの力になれるか心配でしたが、AirTrackの皆さんはとても優しく働きやすい環境でした。また、わからない質問に対しては自分の成長を考えた受け答えをしていただきとても学びになりました。しっかりアウトプットを出せたのも、自分一人の力ではなくメンターさんや先輩の社員の方々のおかげであり、とても感謝しています。そして、この3ヶ月で身につけたことや学んだことはこれからも活かして自分の成長に繋げたいと思います。短い間でしたがお世話になりました。本当にありがとうございました。
Author