Blog
[OpenStack Summit Barcelona 2016] 新卒がミタ! 運用改善編
こんにちは!
CIA でインフラエンジニアをしている青山 真也です。
新卒ではありますがインターンや配属後の業務として OpenStack に取り組んでいたことを評価していただき、
トレーナーの makocchi 先輩と一緒に晴れて夢の1つだった OpenStack Summit Barcelona 2016 に参加してきたので、
興味深かったセッションを中心にお話ししたいと思います。
CaaS (Container as a Service) 環境を検討しているということもあり、私はコンテナ周りの話と現状の構成で改善できる話を中心に聞いてきました。
今回は運用改善編です。(コンテナ技術編はこちら、先輩 OpenStackerと OpenStack コミュニティ編はこちら)
オンプレ環境では障害はつきものです。
やはり OpenStack ともなると様々なコンポーネントやミドルウェアで構成されているため、
障害時の原因切り分けや監視などは一筋縄ではいきません。
そこで、他社さんはどのようにして OpenStack の環境を運用しているのかを聞いてきました。
「OpenStack Troubleshooting: So Simple Even Your Kids Can Do It」
2016-10-27 (Thursday) 1:50pm–2:30pm
「Your Kids Can Do It」この言葉に惹かれて覗いたセッションです。
Redhat さんが発表したこのセッションでは Ansible を使って OpenStack の障害対応を簡潔にしていました。
まず、定番のやらなければいけないこととしては下記の3つがあげられます。
・死活監視(Sensu, Nagios, Zabbix, etc)
・ログ集約(EFK, ELK stack, Splunk, etc)
・パフォーマンスモニタリング(Collectd, graphite, grafana, etc)
また、一般的に障害対応というと次のようなことを行って原因の特定を行います。
1. 原因を絞り込むために、コンポーネントやミドルウェア間の関係性を把握し、影響が起こる前に行ったことを把握する。
2. openstack-status コマンドを利用して、各サーバでプロセスが動いていることを確認する。
3. /var/log/… 以下に ERROR や TRACE を含む行がないかを確認する
4. 以前に動いていた場合には、設定を変更していないかを確認する
Ansible で障害対応を自動化するとなると、高速かつすぐに解決することが期待できます。
一方で、複雑な障害対応手順を自動化するので、最初に環境を整備するのには大きなコストがかかります。
また、リリースによっても仕様が若干異なるため、注意が必要です。
No Hosts Found の障害
これはインスタンスを作成しようとした際に発生する問題です。基本的には次のような状態の時に発生します。
・AZ や Hypervisor の指定などをしている場合、対応するホストが存在しない
・ホストに十分なリソースがない場合
設定ファイルにある CoreFilter や RamFilter の設定などを確認し、オーバーコミットの状態などを考慮してリソースが十分にあるか調べたり、
nova show コマンドや/var/log/nova/*.log を調べて、AZ や Hypervisor の指定などが間違っていないことを確認する必要があります。
詳細なコマンドやフローは 18:25~ を参照してください。
Instance Connectivity の障害
OpenStack が作り出す仮想ネットワークは TUN/TAP、Linux Bridge、iptables、Open vSwitch、virtual Ethernet、Network Namespace など
様々な技術や VXLAN、GRE Tunnel などのプロトコルによって作り出されています。
まずはこのトポロジを理解し、tcpdump などを用いてパケットをトレースしていくことでどのポイントで障害が発生しているかを確認します。
ここら辺は次に書く「Troubleshooting Neutron: Physical and Virtual Networks」のセッションの方が詳しいので、そちらで詳しく話します。
Demo
34:33~ から実際に Ansible を使って問題の検知などを行っている部分があるので、気になる方は是非見てみてください。
発表者が作成した openstack-detective では Ansible を使っての障害検知に留まっているようです。
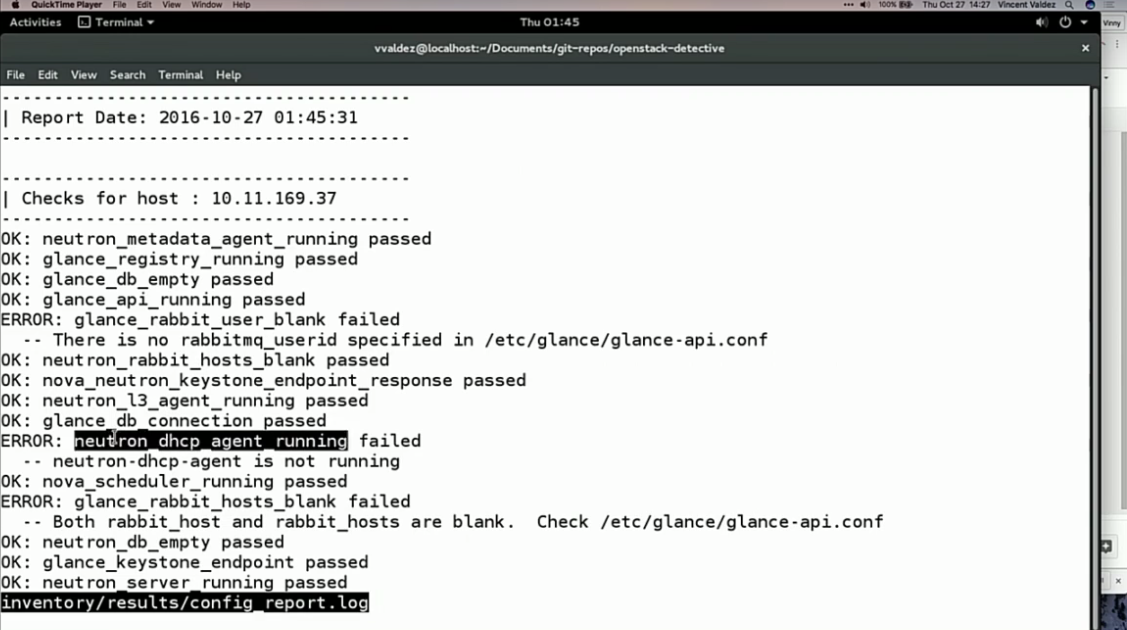
Adtech Studio での取り組みの一例
弊社のプライベートクラウド環境でも、一般的な死活監視やパフォーマンス監視などは行っています。
一方で、開発環境のOpenStack で neutron や nova のプロセス的には生きているが、
OpenStack から見ると死んでいるという状況がありました。
そのため、弊社でもこの発表にあったような OpenStack から見たノードの状態を監視する機構を
Jenkins を使って定期的に実行するバッチジョブとして取り入れています。
構成としては Jenkins が OpenStack のリリースに合わせた OpenStack python client が入ったコンテナを起動し、
障害があれば Slack に通知するような仕組みになっています。
余裕があれば python-nova などのライブラリ使った python script を書く方が綺麗にまとまります。(一部の箇所では実施済み)
「Troubleshooting Neutron: Physical and Virtual Networks」
2016-10-27 (Thursday) 2:40pm–3:20pm
2つ目の障害対応系セッションは、Dellさんが発表した Physical and Virtual Networks。もうこの響きだけで決定しました。
仮想ネットワークってなんだか夢がありますよね。
このセッションでは具体的な障害例2件とともに、仮想ネットワークがどのように組まれていて、
どこまでパケットが正しく届いているかを追っていくという流れになっていました。(合間合間に寸劇を挟みながら)
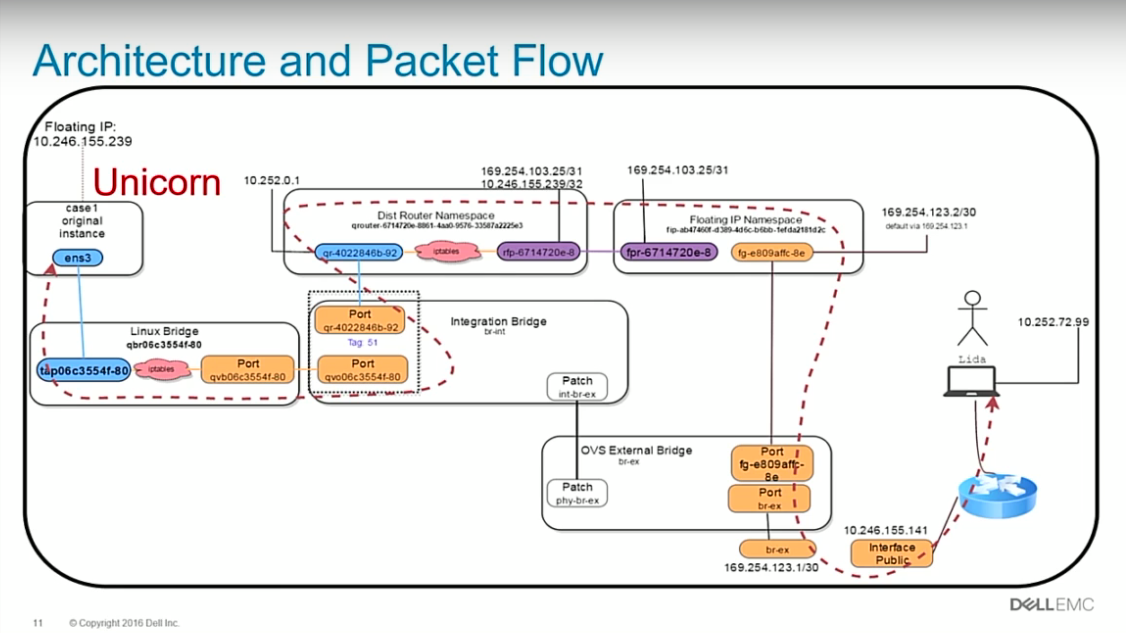
ARP とは何かや、FloatingIP Namespace や QRouter について、それぞれの namespace の ID の取得方法などを手取り足取り教えてくれます。
また、brctl、ovs-vsctl、tcpdump、ip route、ip netns、iptables、neutron、nova、virsh、ethtoolなどの各種 CLI の使い方も
しっかり説明してくれるので、そこまで詳しくない方が勉強するのにも丁度いいレベル感だと思います。
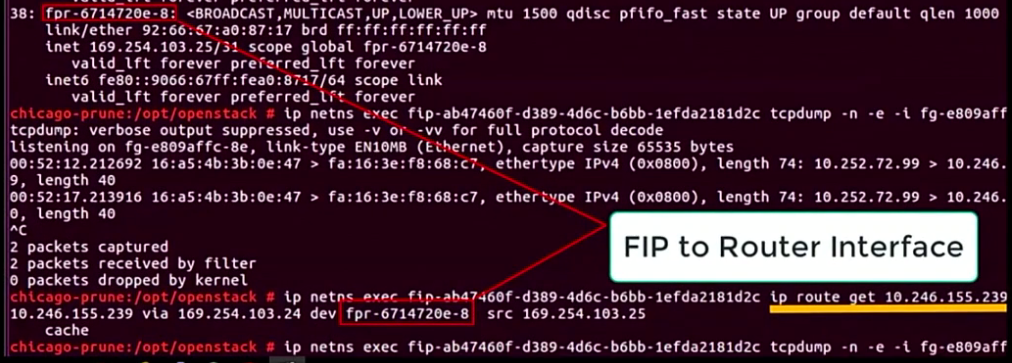
事例としては、次の2点をトレースしていました。
通常の L3 agentの 環境とオーバーレイの環境でそれぞれ知ることができます。
1つ目の障害例:インスタンスのFloating IP に向けて送ったパケットが、インスタンスの private IP と送信元 IP のサブネットが同じなせいで帰りパケットが返ってこない問題
2つ目の障害例: VXLAN を利用した Overlay 環境で、インスタンスの MTU を 1450 にしないと疎通しない問題
ここまで丁寧な説明、昔勉強する時にあればすごく助かったのになぁと思いました。
Adtech Studio でのオーバーレイ SDN 環境
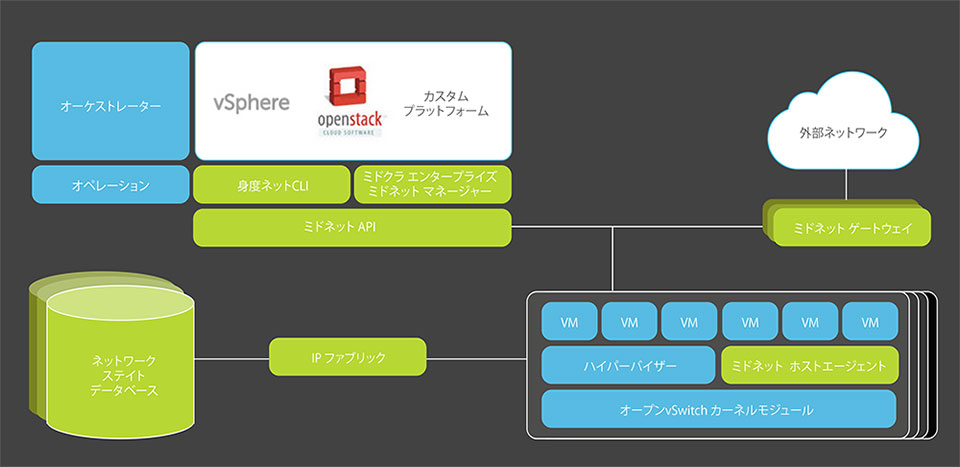
弊社のプライベートクラウド環境でも、Midonet を使ったオーバーレイ SDN 環境を 2015 年から提供しています。
Midonet では各コンピュートノードとゲートウェイとなるノードに midolman と呼ばれるエージェントを起動し、
VXLAN を使ってトンネリングしています。
Midonet を使うことで完全に仮想化された NW や FWaaS や LBaaS をはじめとした柔軟な L3 機能を提供することができるため、
サブネットの制約などを受けにくい環境で開発を行うことが可能となっています。
以上、運用改善編でした!
(コンテナ技術編はこちら、先輩 OpenStackerと OpenStack コミュニティ編はこちら)
Author