Blog
AAAI 2019参加報告:主にバンディットと因果推論について
こんにちは、経済学チームの安井(@housecat442)です。
先日開催されたAAAI 2019に参加・発表してきましたので、気になった研究や発表した論文の内容について簡単に記事を書かせていただきます。
そもそも今回はじめてAAAIへ参加させていただいたのですが、経済学徒にもおなじみのゲーム理論の存在感に非常に驚かされました。内容に関しても非常に面白く、因果推論や計量経済学だけでなくゲーム理論においてもComputer ScienceとEconomicsの交差点があったのかと深く感心させられました。これに関しては一緒に参加した後輩の金子くんが別途ブログ記事を投稿する予定なので、しばしお待ちいただいてそちらを参照していただければと思います。
実はAAAIは因果関係を考える様な学習モデルが以前から発表されてきました。中でも操作変数法をオンライン学習の設定に持ち込んだ研究は非常に面白く、自分のブログでその驚きを報告したほどでした。[1]
この論文を発見した時からぜひ一度AAAIへ参加してみたいと思っていたので、今回AAAIに参加する事ができ非常に嬉しかったです。

気になった発表三つ
“Balanced Linear Contextual Bandits”(Link)
こちらはContextual Banditにおける報酬予測モデルで、Importance Weightを用いる事を提案した内容の研究です。NeuralIPS 2017のWhat If What Next Workshopで発表された”Estimation Consideration in Contextual Bandits”(Link)のカンファレンス版となっています。
共著者の一人であるSusan Atheyはテック企業での研究活動を行う経済学者の代表的な存在であり、”機械学習を用いた因果推論”や”因果推論を用いた機械学習”や”因果推論を用いた機械学習の評価”といったテーマでKDD,NeuralIPSといった様々なトップカンファレンスで論文を量産しています。まさに予測と因果の交わる部分の最先端をいく研究者だと思います。そんなSusan Atheyが関わっている研究だったのもあり、個人的には非常に注目していた研究です。
Contextual Banditは自己の決定に基づいて学習データが作られていきます。よって、学習データは予測したいデータの分布そのものではなく、そこでさらに自己の意思決定によるバイアスが発生する事になります。この様な状況に対応するために傾向スコアを用いて学習データを予測したいデータに近づけてあげて、その状態で報酬予測モデルを学習するといったことを行います。
理論パートではUCB/Thompson Samplingのそれぞれに対してこの提案手法を用いた場合についてのRegret Boundが示されており、Linear Thompson Samplingと結果がそう変わらないことを示しています。実験パートにおいては二つの実験結果が示されています。1つはシミュレーション環境における性能評価で、もう一つは300個ほどあるマルチラベルのデータセットにおける性能評価です。
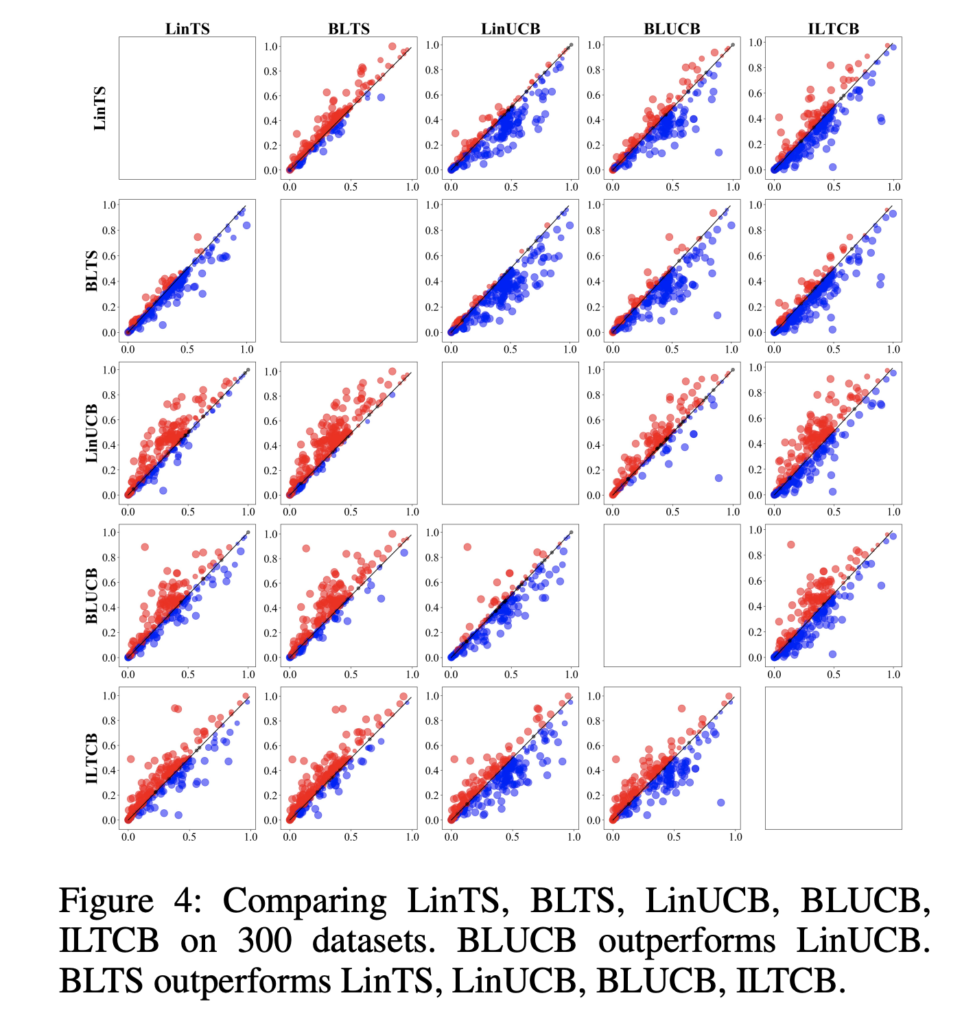
このグラフは点一つ一つがデータセットでの結果となっており、縦軸が行に表示されている手法の報酬性能で、横軸が列に表示されている手法の報酬性能となります。点が青くなっている場合には列側の手法の報酬性能が高く、赤くなっている場合には行側の報酬性能が高いということを示しています。
ここでメインとなる様な提案手法はBLTSであるため、上から2番目の行の結果に着目します。比較対象であるLinTS, LinUCBに対してはほとんどの点が青くなっており、傾向スコアを用いたBLTSの報酬性能が平均的に
高い事がわかります。この結果バンディット自体がもたらすバイアスを取り除く機構を入れることで性能が改善する事が示されました。
バンディットの報酬予測モデルにおける学習データと予測データの分布の違いを考えるというテーマでは傾向スコア以外にも利用できる方法は多く存在するはずなので、今後もいくらか進歩がありそうだと思える研究でした。また実務的にも報酬性能が向上する事が期待できる上にモデルの学習部分のみを変更すれば良いというのは導入が楽なので取り組みやすいという印象を受けました。
“Dynamic Learning of Sequential Choice Bandit Problem under Marketing Fatigue”(Link)
こちらはユーザーが広告に対して思う不快感を考慮に入れた様なバンディットの提案を行なっている研究です。とあるプラットフォームにユーザーが何回か訪れる時に、そのプラットフォームがどの様な広告の出し方をするべきかを考えます。とりあえず広告を出し続ける場合、広告を表示する回数が増えるのでユーザーがクリックする確率はいくらか上昇し、クリックした事によって広告主から費用をもらえる場合には売り上げの期待値が増加する事になります。一方でユーザーが広告に嫌気がさしてプラットフォームの利用自体を停止してしまうという行動を考えると、広告を出し続けるとユーザーがあるタイミングで離脱してしまい、未来における収益をえるチャンスを失ってしまいます。
こちらの論文ではこの様な状況の時にオフラインでの広告表示最適化問題を考え、それをonlineの設定で解くという流れでバンディットを導入しています。この時広告収益から離脱によるコストを差し引いた効用が最大化される様に考えます。この効用のUCBは、広告を表示する場合の収益と離脱した際のコストが決まっていれば、広告をクリックする確率と離脱する確率のUCBが定義できれば得る事ができます。この様にして効用のUCBを定義し、広告表示を行なっていきます。
この研究で提案されている内容はプラットフォームからの離脱をコストとして想定していたり、そのコストが一定であることを想定していたりと、RTBの世界では扱わない様な設定があります。この辺りをうまく変更することでRTBで広告の不快感を考えた様な広告選択を考えることは可能な様に思えました。
“A Distillation Approach to Data Efficient Individual Treatment Effect Estimation”(Link)
ABテストで計測される様な因果効果がサンプルの特徴によって異なる事が想定される場合に、非実験データにおいてその条件毎に異なる効果(ITE)をどの様に推定・予測するか?という研究があります。最近であれば先ほど話に出たSusan Atheyが提案したGeneralized Random Forest(GRF)と呼ばれる手法がよくこのITEの推定に用いられる様になってきました。[2]
この研究では、ITEを推定・予測するモデルを実際にプロダクトに導入する際に、オフラインで使えるデータがオンラインで使えるデータよりもリッチであるという実務では比較的よく見る状況におけるITEの予測方法を提案しています。観測データにおけるGRFの役割はデータのもつバイアスを取り除き、その上でITEを推定する事にあります。この時バイアスを取り除くためにはGRFに投入するデータの中にバイアスを生み出す様な変数が含まれている必要があります。しかし、バイアスを取り除くための変数は必ずしもITEの学習には必要でないというケースがあります。
よって、提案手法ではまずオフラインのリッチなデータを使ってGRFの学習を行い、バイアスを軽減してITEの推定値を出力します。そして次にオンラインで利用可能な限定されたデータでITEをラベルにして教師あり学習を行います。これによりITEの”予測”をプロダクトで利用可能な現実的なデータのみで行える様になります。
ITEの予測は広告効果を考えるという観点で多くのアドテク企業において非常に興味のあるトピックになっています。しかし実際にはITEの予測モデルは学習方法などに多くの問題があり、実務的な使いやすさにおいては大きな問題がまだまだ残っています。この研究はそんな問題の一つであるリッチなユーザーデータが必要という状況をいくらか緩和してくれる様な方法を提案してくれています。
さて、やはり自分が最近興味のあるバンディットアルゴリズムと因果推論に内容が偏ってしまいましたが、気になった発表の紹介としては以上となります。もしこの辺りの研究に興味のある方がいらっしゃればtwitterのアカウントまでコメントを飛ばしていただければと思います。
発表内容について
Efficient Counterfactual Learning from Bandit Feedback(Link)
今回のAAAIは聴講だけでなく、共同研究の一環として執筆した論文を発表してきました。
この研究はバンディットアルゴリズムのオフライン評価に関する研究で、統計的により効率的な評価を試みるものとなっています。このオフライン評価の基礎的な内容については以前に投稿した記事や、社内カンファレンスで発表した資料などがあります。
上記の資料で紹介されている様に、これらのオフライン評価では基本的に傾向スコアを利用したInverse Probabilty Weightingが行われます。Off-Policy Evaluationの特殊系とも言える因果推論では、IPWを利用した際にはSeive EstimatorやSeries Logistic Regressionなどを用いる事で統計的に効率的、つまり推定される分散の値が最小になる様な推定量が得られることが知られています。[3]
今回は因果推論の様に一つの選択肢だけを選び続けるPolicyの評価ではなく、特徴量の値によって選択肢を変える様なPolicyの評価を行うOff-Policy Evaluationにおいてどの様にして統計的に効率的な評価が行えるのかを考え、機械学習を含む様なnonparametricなモデルによって傾向スコアを推定することで、効率的なが可能であることを証明しました。この結果として推定される評価値の分散は縮小し、より信頼度の高い評価と意思決定をオフライン評価で行えることが可能になりました。
ポスターセッションではバンディットに関心のある方や機械学習の側面から因果関係に興味を持つ様な研究者の方に来訪頂き、様々なディスカッションを行うことが出来ました。

最終日のCausal LearningのセッションではOralの発表も行われ、共著者の矢田さんによるプレゼンテーションが行わ、発表後には先ほど紹介した”Balanced Linear Contextual Bandits”の著者や因果推論に興味関心のある研究者が自然と集まり、30分ほど様々な議論が行われました。

人工知能系のコミュニティにおいては因果推論を考える様な研究者はまだまだ少数派ですが、皆それぞれがそこに価値があると考え様々なアイデアで挑戦していることが知れて非常によかったです。またアドテクスタジオ内で行われているバンディットアルゴリズムと因果推論に関する議論の内容が決してAAAIで発表を行う様な研究者たちに遅れをとっているわけでもなさそうだという事がわかったのも、自分としては大きな自信につながりました。

引用
[1]Venkatraman et al., Online instrumental variable regression with applications to online linear system identification, Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[2]Athey et al., Generalized random forests, Annals of Statistics, January 2019
[3]Hirano et al., EFFICIENT ESTIMATION OF AVERAGE TREATMENT EFFECTS
USING THE ESTIMATED PROPENSITY SCORE , Econometrica, July 2003
Author