Blog
CVPR 2019 参加報告
はじめに
AI Lab の大田、大谷です。
6月にアメリカで開かれたコンピュータビジョンの国際会議、CVPR 2019 に参加してきました。
今年も簡単に参加報告をしたいと思います。

CVPR 2019
CVPR は ICCV、ECCV と並ぶコンピュータビジョン分野におけるトップカンファレンスです。AI Labは一昨年、昨年と参加しており、今年で3度目の参加となります。
今年はカリフォルニア州ロングビーチの Long Beach Convention Center にて6月16日〜20日の5日間での開催となりました。15日までは機械学習のトップカンファレンスである ICML 2019 も同会場で開催されており、現地に到着した際にはすでに会場付近が参加者で賑わっていたのが印象的でした。続けて参加された方も多かったのではと思います。その影響もあってか、今年の参加人数は9,227人と前年より2,000人以上増加しています。論文投稿数、採択数も5,160件、1,294件となっており、いずれも過去最高を更新しています。

今年の新しい取り組みとして、本会議でのショートオーラル発表が挙げられます。5分間での研究紹介を3件分行ったあと3件まとめて質疑応答というスタイルとなりました。288件ものオーラル論文を効率良く発表してもらうための工夫でしたが、研究内容の理解が少し難しかったようにも感じました。

併催されている Exhibition では世界各国の大企業や AI スタートアップがこぞってブースを出展。こちらも例年通りの盛況ぶりでしたが、自動運転車両の実車展示が特に目立っており、各社の実用への意気込みの高まりを感じます。

会場周辺はカリフォルニア州最大規模の水族館やアウトレットモールなどが揃う大きな港町です。会議終了後は軽い観光や食事も楽しむことができましたが、アメリカならではの大量で高カロリーな食事には未だに慣れません。

AI Lab からの発表
本会議には大谷による論文 Rethinking the Evaluation of Video Summaries が採択されており、ポスター前では多数の参加者と議論を交わしました。この研究では映像要約手法の評価指標と主要なデータセットを分析しています。より詳しい内容はブログ記事として公開されています。このポスターでは既存の映像要約指標と映像要約手法の一般的なパイプラインに潜在する課題を説明しています。研究者だけでなく映像配信サービスのビジネスサイドの人も議論に参加しており、産業界での関心の高さが伺えました。

本会議論文紹介
注目した論文についていくつか紹介します。
Semantic Image Synthesis With Spatially-Adaptive Normalization
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
Semantic Map からの画像生成において、Normalization 後のスケーリング係数に Semantic Map から得られる特徴を利用した SPADE という手法を提案しています。画像生成モデル自体への入力は Semantic Map ではなくランダムノイズであり、これを操作することで多彩なスタイルの画像生成を可能としています。GauGAN と名付けられたデモも話題になったため、ご覧になられた方も多いかもしれません。
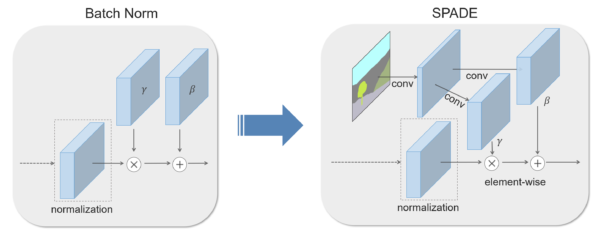 プロジェクトサイトより “Brief Description of the Method”
プロジェクトサイトより “Brief Description of the Method”
 論文より Figure 9. 提案モデルによる多様なスタイルの画像生成
論文より Figure 9. 提案モデルによる多様なスタイルの画像生成
Image Generation from Layout
Bo Zhao, Lili Meng, Weidong Yin, Leonid Sigal
Semantic Map から画像を生成する手法はこれまでにも数多く提案されてきていますが、大まかなレイアウトからの画像生成はテキストやシーングラフなども利用した手法が主でした。この論文では Bounding Box のみで物体の大きさと位置を表現するとてもシンプルなレイアウト入力から画像を生成する手法を提案しています。
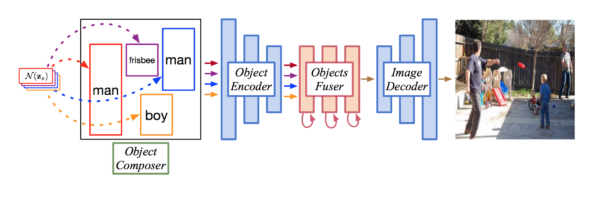 論文より Figure 1. Image generation from layout
論文より Figure 1. Image generation from layout
 論文より Figure 7. Examples of diverse images generated from same layouts
論文より Figure 7. Examples of diverse images generated from same layouts
Homomorphic Latent Space Interpolation for Unpaired Image-To-Image Translation
Ying-Cong Chen, Xiaogang Xu, Zhuotao Tian, Jiaya Jia
画像を特徴ごとにドメイン分けしドメイン間における差異を学習することで画像の変換に用いる Unpaired Image-to-Image 技術は StarGAN や MUNIT などマルチドメイン・マルチモーダルなモデルの提案により、より多彩な振る舞いが可能となってきています。提案手法ではそれらに加え、変換過程の補間についても考慮しています。滑らかで自然な変換アニメーションの生成もできるモデルとなっています。
 論文より Figure 2. Illustration of latent space interpolation along different paths
論文より Figure 2. Illustration of latent space interpolation along different paths
Image Deformation Meta-Networks for One-Shot Learning
Zitian Chen, Yanwei Fu, Yu-Xiong Wang, Lin Ma, Wei Liu, Martial Hebert
今年の本会議では {Zero, One, Few}-shot Learning というワードをよく目にしました。限られた学習データからの学習テクニックの一つにデータの水増しを行う Data-Augmentaiton がありますが、提案モデルはその Data-Augmentation を内包しているようなネットワークとなっており、少量のデータに対して End-to-End な学習を可能としています。
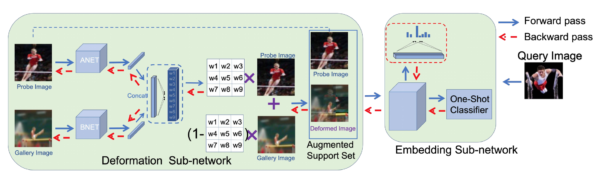 論文より Figure 2. The overall architecture of our image deformation meta-network
論文より Figure 2. The overall architecture of our image deformation meta-network
Efficient Video Classification using Fewer Frames
Shweta Bhardwaj, Mukundhan Srinivasan, Mitesh M. Khapra
同様に少量データからの学習ですが、こちらは動画分類に対するアプローチです。Distillation の仕組みを利用することで等間隔に間引かれた少数フレームによる学習を可能にし 、リソース消費の激しい動画分類のコスト軽減を図っています。
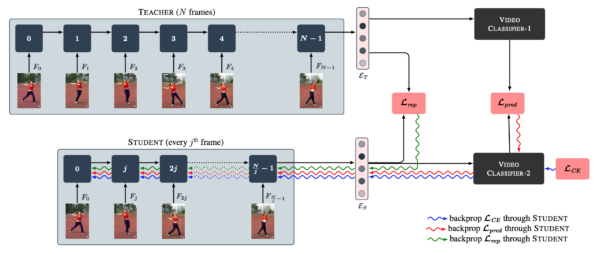 論文より Figure 1. Architecture of TEACHER-STUDENT network for video classification
論文より Figure 1. Architecture of TEACHER-STUDENT network for video classification
GoodNews Everyone! Context driven entity aware captioning for news images
Ali Furkan Biten, Lluis Gomez, Marçal Rusiñol, Dimosthenis Karatzas
画像のキャプション生成の研究です。この手法では入力として画像だけでなく、画像に関連する文書を使って固有名詞などのキーワードを取り入れたキャプションを生成します。広告制作においてはコピー生成などに活用できそうなアプローチです。
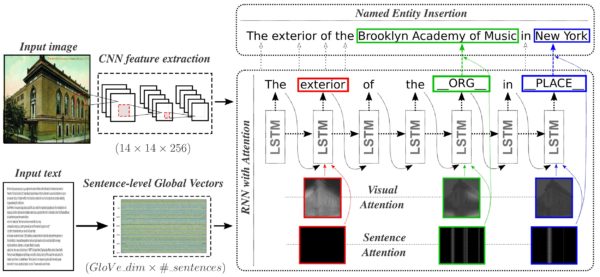 論文より Figure 2
論文より Figure 2
Complete the Look: Scene-based Complementary Product Recommendation
Wang-Cheng Kang, Eric Kim, Jure Leskovec, Charles Rosenberg, Julian McAuley
画像全体の雰囲気に合った商品を予測するモデルを提案しています。同様の構造を持ったタスクは広告バナーの制作にもあります。バナー画像の雰囲気に合ったフォントやテクスチャ素材などデザイン要素を提案するシステムなどにも応用できそうです。
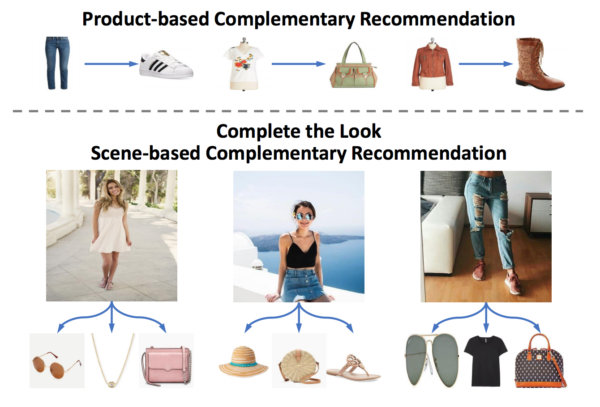 論文より Figure 1
論文より Figure 1
Less is More: Learning Highlight Detection from Video Duration
Bo Xiong, Yannis Kalantidis, Deepti Ghadiyaram, Kristen Grauman
映像から重要なシーンを抽出するハイライト検出の研究です。機械学習を用いた映像のハイライト検出では、学習データの収集コストが非常に高いという課題があります。そこでこの研究ではウェブ上の動画の長さを教師信号として活用する方法を提案しています。短い映像はより「ハイライトらしい」シーンで構成されている傾向にある一方で、長い映像はハイライトとしては適していないシーンを多数含んでいることが予想されます。この仮説に基づき、提案手法では短い動画と長い動画からハイライトらしい動画の特徴を学習しています。
 論文より Figure 1
論文より Figure 1
まとめ

CVPR は参加者・論文数共に爆発的な増加を続けており、もはや会議全体のトレンドを把握することは困難ですが、個人的には GAN や画像生成に関する研究の発展はやはり興味深く、質の高い研究について生で聴講できる機会はとてもありがたいです。引き続き広告やメディアデータに対するコンピュータビジョン・機械学習技術の応用に向けて今後も研究活動を続けていきます。
Author