Blog
ICCV 2019 参加報告:研究動向、発表ほか
はじめに
AI Labの大谷と山口(@kotymg)です。10月に韓国ソウルにて開催されたコンピュータビジョンの国際会議ICCV 2019に参加してきました。こちらの記事で簡単に参加報告させていただきます。
ICCVについて
ICCVはコンピュータビジョン研究の3大トップカンファレンスの一つに位置付けられる権威のあるカンファレンスで、隔年開催となっています。AI Labからは2017年に続いての参加となります。2019年のICCVは4303件の投稿、1075件の採択と、ここ数年の分野の人気に伴って過去最大規模になりました。規模こそ同分野トップカンファレンスのCVPRよりも若干小さいものの、会場となった巨大なCOEX展示場には7000人を超える参加者が集まりました。発表件数の増加に伴い、今回のICCVではCVPR 2019同様にショートオーラル形式による発表方式となり、その他は全てポスター発表という形態になりました。

ICCV 2019 オープニングセレモニー
写真は会議のオープニングセレモニーの様子です。オープニングセレモニーでは会議への投稿や参加者の統計について公表がある他、いわゆるベストペーパー賞に当たるMarr Prize他、各種の表彰が行われます。近年は人工知能分野の学会では中国と米国からの研究発表が圧倒的に多い傾向がありますが、ICCVもご多分に漏れずこの2国からの採択数が圧倒的に多く見られました。
AI Lab関連の研究発表
AI Labからは残念ながら今回本会議の発表はなく、併催のワークショップにて二件の研究発表をさせていただきました。
- Adaptive Gating Mechanism for Identifying Visually Grounded Paraphrases
- Mayu Otani, Chenhui Chu, Yuta Nakashima
- Regularized Adversarial Training for Single-Shot Virtual Try-On
- Kotaro Kikuchi, Kota Yamaguchi, Edgar Simo-Serra, Tetsunori Kobayashi
研究動向について
前回のICCV 2017に比べてICCV 2019で研究発表のタイトルに出現する割合の高くなったキーワードは以下のようなものでした。抽出方法は、ICCV 2019とICCV 2017論文タイトルからunigram/bigramを抜き出し、その出現頻度を会議全体の出現数で割った割合の変化が大きかったものから、目についたものを掲載しています。
- Object Detection
- Aware
- Guided
- Graph
- Point Cloud
- Person Re-Identification
ICCV 2017と比べてObject Detectionが多く見られるようになったことは意外に思えますが、単純な2D DetectionではなくVideoや3Dを対象にした手法や、ドメイン転移を考慮したDetectionのように、様々な環境でのDetection手法が提案されるようになったことが理由でしょう。AwareやGuidedはモデルの学習時に何らかの補助的情報を利用する手法によく見られるキーワードです。Graphが出てきたのはScene GraphやGraph Convolutionといったグラフ構造を考える手法が増えたためと見られます。Point Cloudは三次元点群を対象とした研究に出てきますが、ニューラルネットワークで三次元データを扱う研究はここ最近増えていることが反映していると考えられます。また、Person Re-Identificationは実応用にかなり近いタスクですがベンチマークデータも整備が進んだことで発表件数が増加しているようです。
この他にも全体の中の割合として大きな変化があったわけではありませんが、Image Synthesis、Domain Adaptation、Human Poseといったトピックでの研究発表が目につきました。
クリエイティブ制作に関連する研究紹介
AI Labではグラフィックデザインや動画制作などのクリエイティブ制作に関連のある研究に着目しています。今回のICCVでもクリエイティブ制作に関係がある研究発表がいくつもありました。特に我々が注目する研究発表を以下に数件紹介します。
InGAN: Capturing and Remapping the “DNA” of a Natural Image
Assaf Shocher, Shai Bagon, Phillip Isola, Michal Irani
[Paper] [Project] [Github]

InGANでは一枚の画像(赤枠)を入力として多様なサイズの画像を出力できる(論文中Figure 1より引用)
InGANは一枚の画像から敵対的生成モデルを学習する試みで、ICCV 2019でMarr Prizeを受賞したSinGANに設定は似ています。画像から小さなサイズの領域パッチをサンプルして生成モデルを学習することで、異なるサイズ、アスペクト比の画像を生成することが可能となります。広告制作でも異なるサイズのバナーデザインを制作することはよくありますが、テキストや飾りを載せる前の背景のような画像を使う際にデザイナーを強力に支援してくれそうです。
Controllable Video Captioning With POS Sequence Guidance Based on Gated Fusion Network
Bairui Wang, Lin Ma, Wei Zhang, Wenhao Jiang, Jingwen Wang, Wei Liu
[Paper] [Github]

POSタグによる生成キャプションの操作例(論文より引用)
POSタグ列を使って、動画キャプションの生成結果をコントロールする手法です。動画のキャプションと同時にPOSタグ列を予測するモデルですが、実験ではこの予測POSタグを操作することで多様なキャプションを生成する方法を提示しています。AI Labでは広告コピーの生成にも取り組んでいます。この論文で提案されたフレームワークを発展させることで、バナー画像/動画などのビジュアルコンテンツを考慮したコピーの生成が期待できそうです。特に異なるPOSタグテンプレートを用いた多様なキャプションの生成は、ユーザごとに様々なバージョンのコピーを作る必要があるインターネット広告では嬉しい性質です。
Seq-SG2SL: Inferring Semantic Layout From Scene Graph Through Sequence to Sequence Learning
Boren Li, Boyu Zhuang, Mingyang Li, Jian Gu
[Paper]
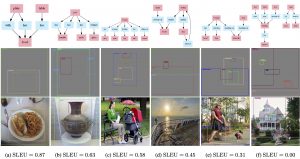
上から入力のscene graph、予測されたレイアウト、入力scene graphに対応する元画像。(論文より引用)
Scene graphからレイアウトを予測する手法です。Scene graphとレイアウトをタグの系列として表現することで、レイアウトの生成タスクをsequence to sequenceモデルの学習に落とし込んでいます。バナー画像自動生成において、このようなレイアウト予測は重要な要素技術です。オブジェクトや背景の相対的な位置を予測するこの手法は、与えられた素材画像やテキストなどの要素を自動で配置するバナーデザインシステムに応用できる可能性があります。
おわりに
ICCVではDetectionやSegmentationのような主要なコンピュータビジョンの研究トピックが継続して多く発表されていましたが、それに加えて画像生成のようにタスク自体が難しいものや、三次元点群のようなデータ構造を対象にニューラルネットワークを活用してend-to-endに課題解決する手法など、新しいことに果敢に挑戦する研究が多く見られたように感じます。
AI Labではコンピュータビジョンを活用してテキスト、グラフィックデザインなどの広告制作を支援する技術を研究開発しています。研究成果は会社事業に使われるだけでなく、ICCVをはじめとする学術会議で発表することを奨励しています。我々のチームに興味のある方は採用のページもぜひチェックしてください。
Author