Blog
言語処理学会第28回年次大会(NLP2022) 参加報告
はじめに
こんにちは。AI Lab NLPチームの村上(@ichiroex)です。普段は広告文生成の研究をしています。
言語処理学会第28回年次大会(NLP2022)が、2022年 3月14日(月)〜 3月18日(金)に開催されました。
本記事は、その参加報告となります。
NLP2022とは
言語処理学会が開催している年次大会で、自然言語処理分野やその関連分野の研究者および学生などの研究成果発表、交流の場として集う大規模なイベントです。
今年で28回目となった本大会は、静岡県浜松市のアクトシティ浜松 コングレスセンターでの開催を予定されておりましたが、社会情勢を鑑みて一般参加者はZoomやSlack、Gatherを活用したオンライン形式で開催されました。
今回の参加登録数は歴代1位の1718名、発表件数は歴代3位の386件ということで、自然言語処理分野の盛り上がりを感じました!
また、スポンサー企業数も歴代1位の66社となり、産業界からの関心度の高さが伺えます。サイバーエージェントからは今年もプラチナスポンサーとして協賛させていただきました。弊社のスポンサー展示ブース(Gather)にお越し頂いた皆様、ありがとうございました。
サイバーエージェントからの研究発表
サイバーエージェントからは本大会に併設のワークショップを含め6件の研究発表を行いました。
\ お知らせ /
3/14-3/18に行われる言語処理学会第28回年次大会(#NLP2022)にて、AI事業本部から産学連携の成果を含む6件の発表とオンライン展示を行います!
NLP2022に参加される方は是非発表にお越しください!#NLP2022sponsorhttps://t.co/MyCyGASwQf— CyberAgent AI事業本部広報 (@cyberagent_ai) March 14, 2022
私からは「LP-to-Text: マルチモーダル広告文生成」について研究発表しました。ランディングページ(LP)における視覚情報やレイアウト、テキストなどのマルチモーダル情報を活用した広告文生成に関する研究です。 ランディングページを1つの文書画像として捉え、文書画像からの言語生成として広告文生成タスクに取り組んでいます。
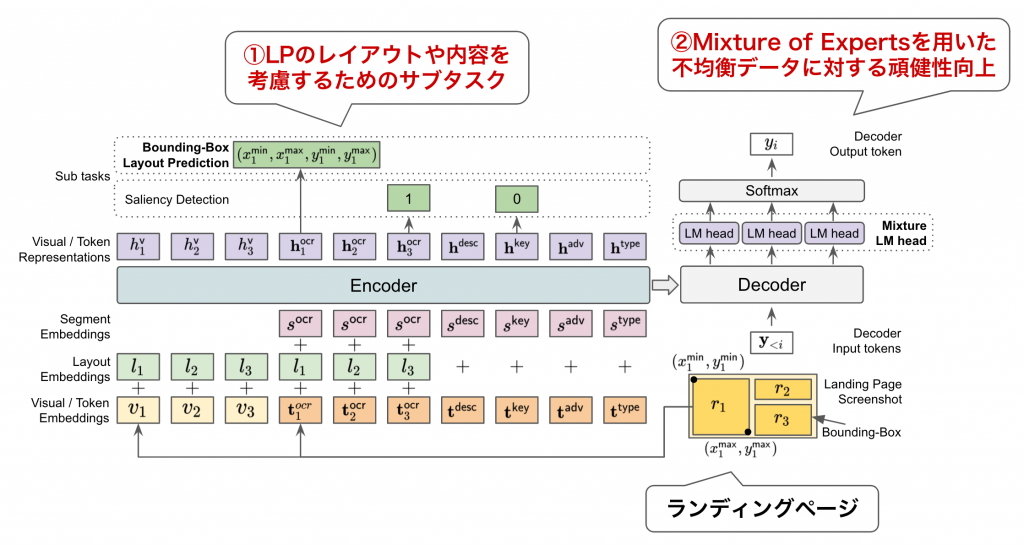
提案手法のポイントとしては2点あります。
- LPのレイアウトや内容を考慮したマルチタスク学習の導入
- Mixture-of-Expertsによる広告データの不均衡性を考慮した学習
これらの工夫を導入することで、生成テキストの品質や多様性の改善を確認できました。詳細については、言語処理学会HPより後日予稿が一般公開されますので、ぜひご覧ください。
また口頭発表の際には、ZoomやSlackを通して多くの方からご質問やコメントをいただきました。貴重なご意見を頂きありがとうございました!今後の研究の参考にさせていただきます。
聴講内容
私が発表を聴講した/論文を読んだ研究の中で、特に興味深かった研究発表を紹介します。
C1-3: テキストと視覚的に表現された情報の融合理解に基づくインフォグラフィック質問応答
○田中涼太, 西田京介 (NTT), 許俊杰 (筑波大), 西岡秀一 (NTT)
インフォグラフィックに対する機械読解タスクに取り組んでいる研究です。文書画像理解などの関連タスクにおいて、インフォグラフィックはテキストと視覚の融合がもっとも必要な文書画像であることが知られています。そのため本研究では、文書画像中の視覚物体とテキストの関係性を考慮するための配置予測タスクを新たに導入しています。また、算術演算が必要な質問応答に対応するために、演算過程を生成するデータ拡張手法を提案し、演算が必要な質問にも対応可能になったことが報告されています。
所感
インフォグラフィックは広告のランディングページと類似した部分もあるため、注目していました。このような文書画像を対象とした言語生成においては、文書画像中の視覚物体とテキストの関係性を考慮することが重要であり、その課題に着目した提案法に面白さを感じました。また、算術演算にも対応する工夫など大変興味深いです。本論文は若手奨励賞を受賞されておりました。
A1-1 Representative Data Selection for Sequence-to-Sequence Pre-training
○Haiyue Song (京大), Raj Dabre (NICT), Zhuoyuan Mao, Chenhui Chu, Sadao Kurohashi (京大)
大規模コーパスからのデータ選択に取り組んでいる研究です。大規模コーパスを用いたモデル学習はコストが高いことが問題視されています。その解決策として、大規模コーパスから有用な代表データを選択することでより小規模なコーパスで効率的にモデル学習することが考えられます。本研究では、クラスタリングベースの教師無し手法を提案しています。各文ベクトルのクラスタリングを行う際に、外れ値(outlier)を削除する手法を適用することにより、外れ値削除を適用しない場合と比べて後段タスク(翻訳、要約)の性能が改善することが報告されています。
所感
モデル構築において、大規模データは計算リソース制約などの観点において研究開発の現場でも課題になります。本研究ではその課題に対してデータ選択に取り組んでおり、クラスタリングに基づく教師無し手法かつシンプルな手法であるため、実装のしやすさという観点でメリットを感じました。また、実験結果ではオリジナルデータ(458M)の0.26% であるデータ(1.2M)を用いた場合でも後段タスクにおいてある程度の性能が発揮するといった大変興味深い結果が報告されていました。
A3-1 ニューラル言語モデルの効率的な学習に向けた代表データ集合の獲得
○鈴木潤 (グーグル/東北大), 全炳河, 賀沢秀人 (グーグル)
こちらもA1−1と同様にデータ選択に取り組んでいる研究です。本研究では、先行研究を参考に2つの言語モデルの尤度差を利用して文をランキングすることで代表データを選択しています。具体的には、特定のドメインに特化した言語モデル(特化型言語モデル)と特定のドメインに特化しない言語モデル(汎用言語モデル)より計算された対象テキストの尤度差を用いて、特定のドメインにより適したデータを選別しています。この選定されたデータ集合を用いることで、言語モデルの性能評価のためのベンチマークであるGLUEにおいて、元データ(745GB)の21分の1程度のデータ規模(35GB)でも平均性能の観点で同等の性能が得られることが報告されています。
所感
提案手法は言語モデルに基づく教師無し手法かつシンプルな手法であるため、実装面でメリットを感じました。また、実験では様々なモデルサイズ、データ量が検証されており、大変参考になりました。さらにデータ量を絞った際にどのような結果になるかなど検証してみたいです。また本論文は、最優秀賞を受賞されておりました。
C6-3 近傍の事例を用いた非自己回帰生成
○丹羽彩奈, 高瀬翔, 岡崎直観 (東工大)
Levenshtein Transformerなどの非自己回帰モデルによる生成品質の改善に取り組んでいる研究です。非自己回帰モデルは並列化が容易なため、自己回帰モデルと比べて生成速度に優位性がありますが、一般的に生成品質が劣るという欠点がありました。そのため本研究では、このような問題を解決するために非自己回帰モデルの初期値として、近傍の事例を用いる方法を提案しています。具体的には、翻訳メモリ(学習データ)から対象の近傍事例を検索し、初期値として使用します。また、近傍事例と参照文の差分に着目した学習方策を導入することで、近傍事例から編集して文生成することが可能となりました。
所感
非自己回帰生成の初期値として近傍を使うというアイデアはこの周辺分野のスタンダードになりそうな予感がしました。また、Top-5の近傍を使うことでOracle近傍に匹敵するような性能を出しており、非自己回帰生成の性能向上の将来性が期待できます。一般的に非自己回帰生成は自己回帰生成よりも生成品質が低くなりがちですが、この研究によってそのような課題の解決を期待しています。複数ドメインの対訳コーパスでの検証など今後が楽しみです。また本論文は、委員特別賞を受賞されておりました。
G2-3 IMPARA: パラレルデータにおける修正の影響度に基づいた文法誤り訂正の自動評価法
○前田航希, 金子正弘, 岡崎直観 (東工大)
文法誤り訂正タスクにおける参照文を用いない自動評価法に取り組んでいる研究です。既存の文法誤り訂正の評価法では、誤文に対する複数の参照文が必要とされていたり、評価モデルの学習データが必要といったデータ作成の課題がありました。そのため本研究では、評価に特化したデータを使わず、誤文と正文のペアからなるパラレルデータのみを用い、修正時の「影響度」に基づいた評価尺度を学習する手法(IMPARA)を提案しています。具体的には、編集操作の影響度を、正文とその編集操作を除いた文の文ベクトルの距離により定義し、各編集操作の影響度を定義しています。こちらの編集に対する影響度を基に、訂正文の良し悪しの順序関係をラベル付けした教師データを作成し、評価モデルを学習することで、各訂正文に対する相対的な評価尺度を獲得することが可能となりました。実験では、人手評価との相関において従来手法と同等以上であったと報告されています。
所感
編集操作の「影響度」を文ベクトルの距離で定義するというアイデアが大変興味深いです。実験では誤りタイプごとの影響度の分析もされており、結果を理解する上で参考になりました。文ベクトルの作成法を変えた場合(BERTではなく別のモデルを使った場合など)にどのような結果になるのか検証してみたいです。また本論文は、優秀賞を受賞されておりました。
B3-2 後処理ネットワークを用いた強化学習によるタスク指向型対話システムの最適化
○大橋厚元, 東中竜一郎 (名大)
複数のモジュールからなるパイプライン型のタスク指向型対話システムの最適化に取り組んでいる研究です。これまで、このようなシステムの最適化を行うためには各モジュールを同時に学習する方法が取られていましたが、これは各モジュールが学習可能な手法で実装されている必要があり、ルールベースに基づくモジュールなどには適用できませんでした。そのため本研究では、各モジュールに対する後処理ネットワークを導入し、強化学習を用いることで実装手法に依存せずにシステム全体を同時に最適化する方法を提案しています。これにより、ルールベースや学習可能なモジュール(ニューラルネットワーク等)が混在するシステムの最適化が可能になりました。
所感
さまざまなモジュール(ニューラルベース、ルールベース等)で構成されるパイプライン型のタスク指向型対話システムにおいて、システム全体の最適化が難しいという弊社でも抱える課題に対して、後処理ネットワークや強化学習により全体最適するといった課題解決法が大変参考になりました。提案手法の汎用性が高く、弊社内でもぜひ同様の手法を検証してみたいという声が多く上がっていました。そのため本論文はスポンサー賞として、弊社からサイバーエージェント賞を贈呈致しました。また本論文は、委員特別賞も受賞されておりました。
おわりに
今回で3回目のオンライン開催の年次大会となりましたが、ZoomやSlack、Gatherなど活用し、イベントや交流機会の創出を準備していただたいおかげで大変盛り上がった大会でした。運営委員の皆様に感謝申し上げます。
来年のNLP2023の開催地は沖縄ということで、最後のクロージングの際にSlackやTwitterがとても盛り上がっていたところが印象的でした。来年の開催も楽しみにしています。
また、最後に告知となりますが、サイバーエージェントでは自然言語処理を活用した研究開発を促進しており、研究者、エンジニア、データサイエンティストなど募集しています!また、インターンシップもあります。
ご興味のある方はぜひこちらからご応募下さい。よろしくお願い致します。
Author