Blog
【採択論文紹介】拡散モデルに基づく制御性の高いレイアウト生成モデル (CVPR2023)
AI Lab Creative Researchチームの井上です。我々のチームでは広告クリエイティブの制作支援と自動生成に関する研究開発に取り組んでおり、その中でも自分は特にバナー画像の自動生成技術の開発に取り組んでいます。この記事ではCVPR2023に採択された、拡散モデルに基づいた制御性の高いレイアウト生成モデルに関する論文について紹介します。
LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
はじめに
レイアウト生成は、コンテンツ生成のために「どこに」「何の要素を」配置すべきかのパターンを提示する基盤技術であり、バナーやスライド、ポスターなどといったグラフィックデザインの生成への応用が期待されています。近年の研究では実際にデザインを行なっていく上で大事な、ユーザの大まかで多様な指示に忠実に生成する「制御可能」な生成に着目した設定が多く提案されてきました(各設定の詳細に関しては昨年のサーベイブログ「レイアウト生成の研究紹介」をご覧ください)。いくつかの設定例を図1に示します。我々の研究は各設定に特化したニューラルネットワークを学習する従来手法と違い、全設定の生成を単一モデルで実現しました。
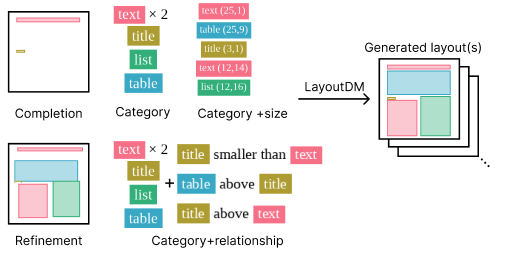
図1: LayoutDMがカバーする、制御可能な生成の設定例。Refinement はnoisyな観測が得られる時にレイアウトを微調整するタスク。
提案手法: LayoutDM
LayoutDMの要点を説明します。レイアウト情報は位置とカテゴリの情報を要素数個分持ちますが、図2のようにこれらを全て離散変数として表現し一次元の配列のようにみなします。拡散モデルは連続変数用のモデル (例: [1]) が有名ですがLayoutDMは離散変数用のモデル [2] をベースにしており、順過程では事前に定められたスケジュールで徐々にデータにノイズを加えていきます(実際には変数値がランダムなトークンに入れ替わったり、特殊なトークンに入れ替わったりします。)。逆過程では、現在わかっている情報を手掛かりに、より自然なレイアウトを推定することを繰り返して自然なレイアウトを生成していきます。逆過程は実際にはニューラルネットワークで表現され、事前にレイアウトのデータセットを用いて学習されます。テスト時のみ、我々は逆過程の各ステップにおいて、ネットワークの予測をユーザ指示によって補正することで(図2の赤字部分)、生成を制御可能にします。色々な指示の種類がありますが、それらが全てmasking と logit adjustment という2種類の方法で補正として表現出来るのが興味深い点です。
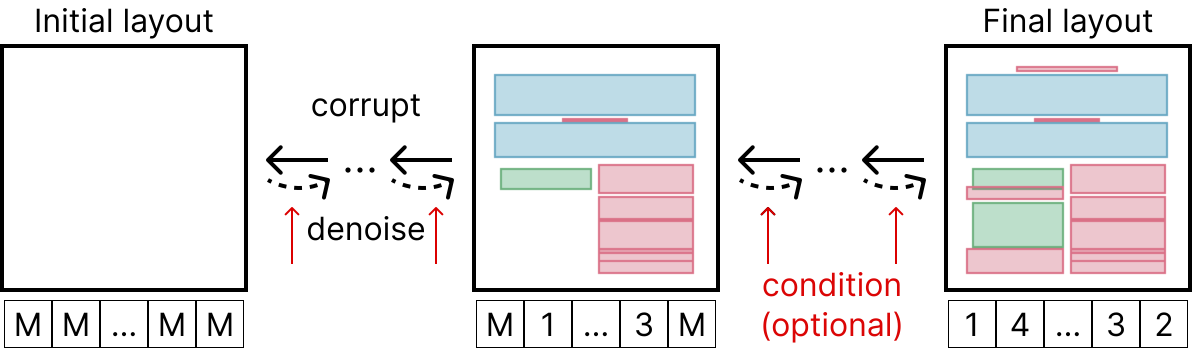
図2: LayoutDMの概要。初期レイアウトと実際のレイアウトの間の順過程(右→左)・逆過程(左→右)が表示されている。各ステップでは上部にそのステップでのレイアウト、下部にそのレイアウトを表現する離散変数の一次元配列を表示している。 M は BERT [3] などで有名な mask token という特殊トークンを表している。
そもそもどうやって位置情報を離散変数にするのか、変数にノイズを加えるスケジュール、逆過程をモデリングするニューラルネットワーク構造、既存手法との違いといった詳細情報はぜひ論文をご覧ください。
実験結果
実験では、提案手法が既存の様々な設定の生成問題において、タスク特化型のモデルに近い、もしくは同等の生成クオリティを実現することを定性・定量的に確認しました。その例を図3に示します。実際のレイアウトとの類似度に加え、左右が揃っているか,不必要に要素同士が重なっていないかなどの観点からもLayoutDMが良い生成をしていると考えられます。
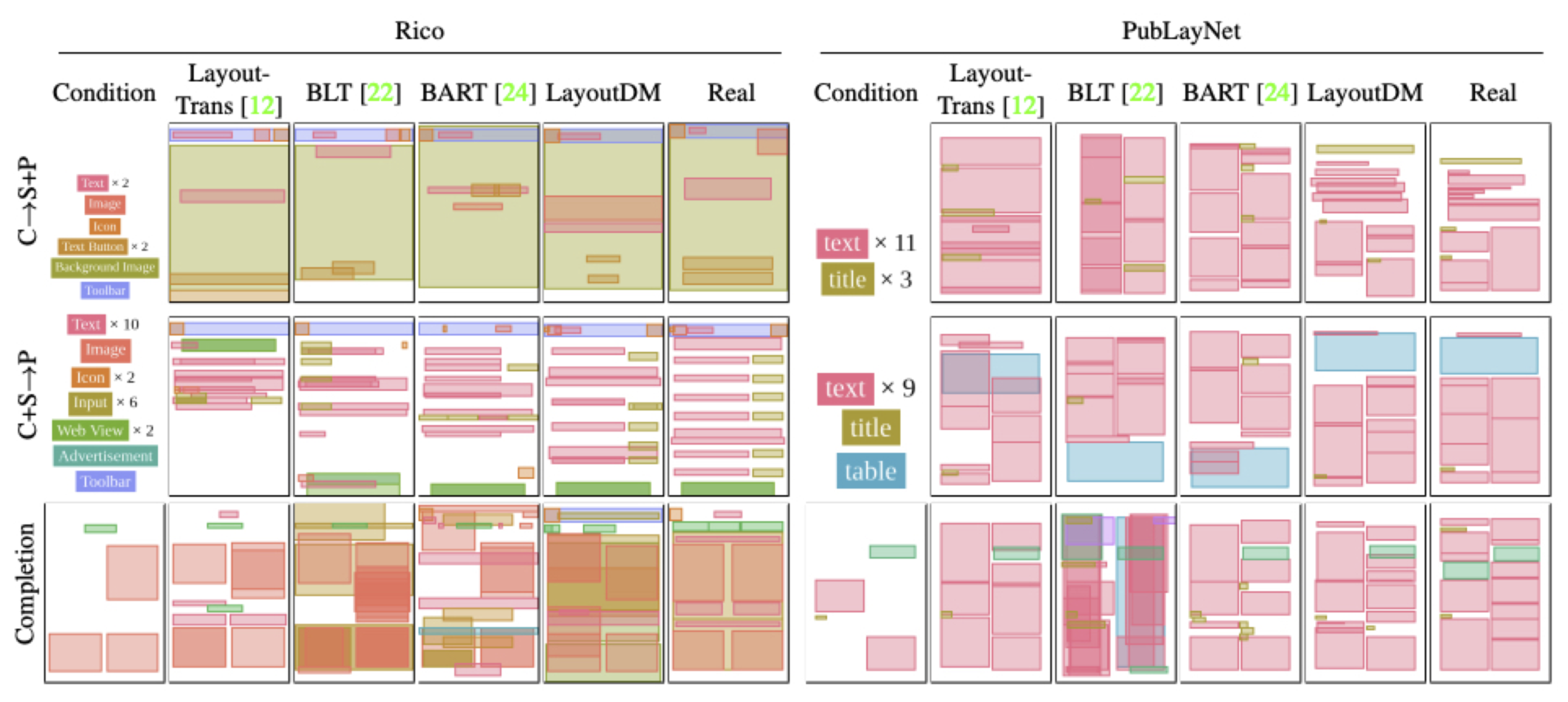
図3: ユーザ入力が与えられた時の生成結果の比較。Realは実際のレイアウト。左はRico [4]というMobile UIデータセットでの、右は PubLayNet [5] という論文のデータセットでの結果。C→S+P はカテゴリが与えられた時に位置とサイズを当てる設定。C+S→P はカテゴリとサイズが与えられた時に位置を当てる設定。Completionは幾つかの要素がわかっている時に残りを埋める設定。
LayoutDMは拡散モデルベースなので、生成にかけるステップ数は調整が可能で、生成の質と速度のトレードオフ関係を調整することができます。図4では、カテゴリとサイズ情報が入力として与えられた時にレイアウトを生成するタスクにおいて、様々な手法の生成の質と速度を比較したグラフです。提案手法であるLayoutDMが概ねベストであることがわかります。
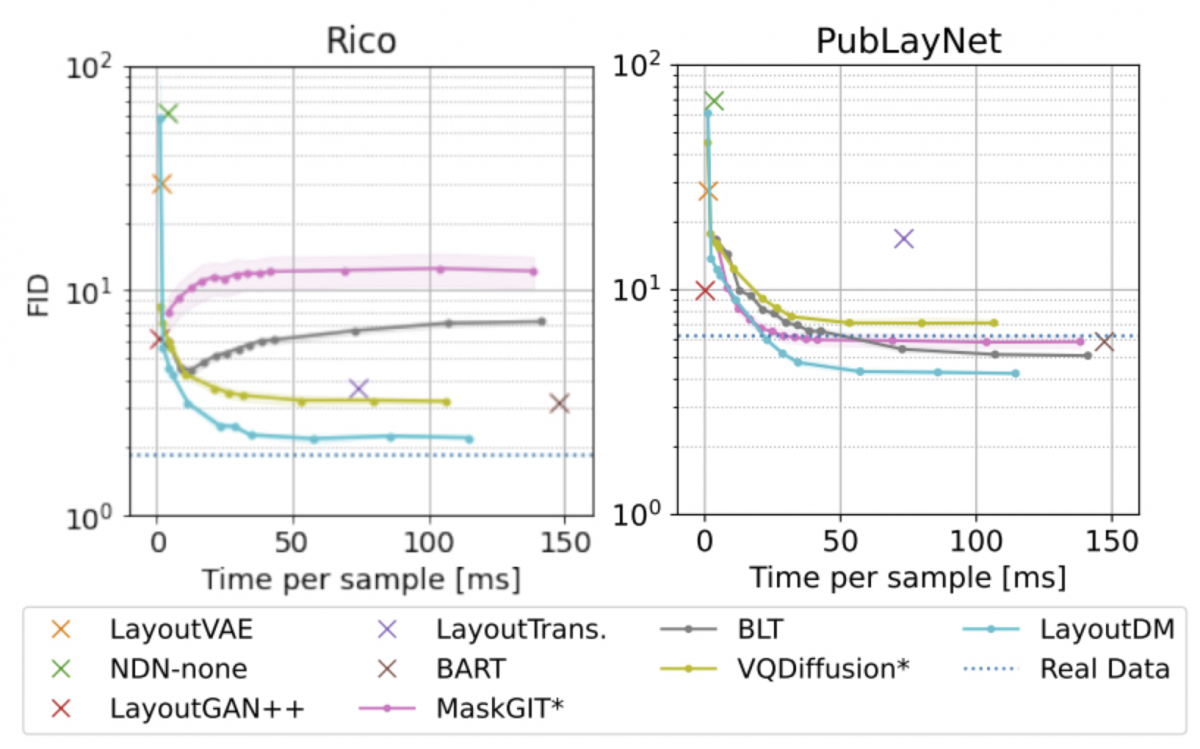
図4: 推論ステップ数を変化させた時の精度とのトレードオフ(Category + Size → Position)。FIDは低い方が良い生成結果であり,点・線が左下に行くほど良いモデルであることを表す。
おわりに
本研究では拡散モデルをベースにした、制御性の高いレイアウト生成モデルを提案しました。副次的な入力 (例: バナーの背景画像) も考慮に入れたレイアウト生成、画像やテキスト、詳細なスタイリング情報 (例: フォント) も含めた生成など、様々な拡張が考えられます。弊社では博士課程の学生を対象にリサーチインターンシップを募集しています。このような研究に興味を持たれた方はぜひ私たちに声をかけてみてください、一緒に研究しましょう。
参考文献
[1] Ho et al., “Denoising diffusion probabilistic models”, In NeurIPS, 2020.
[2] Austin et al., “structured denoising diffusion models in discrete state-spaces”, In NeurIPS, 2021
[3] Devlin et al., “Bert: Pre-training of deep bidirectional transformers for language understanding”, In NAACL, 2019.
[4] Deka et al., “Rico: A mobile app dataset for building data-driven design applications.”, In UIST, 2017.
[5] Zhong et al., “PubLayNet: largest dataset ever for document layout analysis.”, In ICDAR, 2019.
Author