Blog
[Strata Data Conference 2017 in New York] – Sessions Day1
アドテク本部の成尾と水野です。
まずは、セッションの1日目について
成尾から、初日に見たセッションの中で気になったものを取り上げます。
Geospatial big data analysis at Uber
ご存知の方も多いと思いますが Uber という配車サービスの事例です。
ユーザーが出発地、目的地をWebやアプリから入力しドライバーが迎えにきて目的地まで連れていく、いわゆるタクシーですが
ドライバーは自家用車を利用したり、ユーザーとドライバーが双方に評価をつけたり、とタクシーとは違った特徴もあります。
2009年3月にアメリカで設立された Uber は、2013年11月に日本でもトライアルを実施し
2014年8月から都内全域でサービスをしている事からも利用したことがある人もいるのではないでしょうか。
現在は6大陸、73ヵ国、633都市でサービスを行っています。
このセッションでは、 Uber として重要な地理空間のビッグデータ分析についてでした。
地理空間のデータは
出発地、目的地を選択すると、その地点までの最適なルートを計算したり
都市の場所、旅行情報、イベント情報などビジネスの意思決定を改善する情報 etc
非常に重要で、分析基盤のアーキテクチャとしては
膨大なデータを、Kafka や RDB ( MySQL, Postgres ) から集め
ストリーム処理、リアルタイム分析( Flink, Pinot, MemSQL ) し HDFS にデータが貯める(データレイク)
そのHDFSからバッチ、ETL処理はHiveとSpark、リアルタイム処理に Presto を実行しているとの事でした。
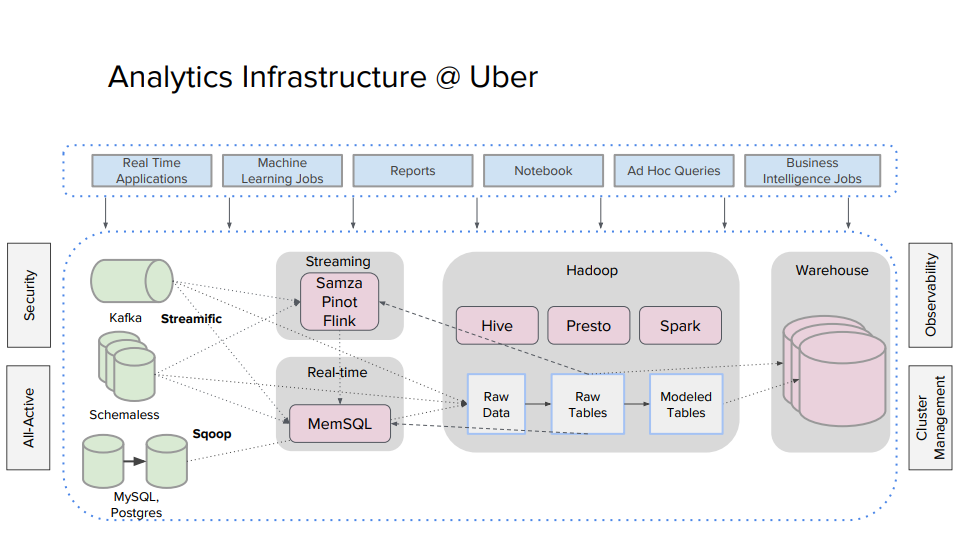
Presto を採用した理由は、そのアーキテクチャと速度の面から
また、複数のデータソースからコネクタを利用して、複製なしにデータを利用できるという点との事です。
後述で、GeoSpatial Plugin for Presto の事にも触れていたので、ここら辺も決め手になっている気がします。
データモデルは
単純な緯度経度を使った、点で表すポイントいうデータ
|
1 |
POINT (77.3548351 28.6973627) |
面で現すポリゴンというデータに分かれていて
|
1 2 3 4 5 6 |
POLYGON ((36.814155579 -1.3174386070000002, 36.814863682 -1.317545867, 36.814863682 -1.318221605, 36.813973188 -1.317910551, 36.814155579 -1.3174386070000002)) |
Uber ではポリゴン、マルチポリゴンからジオフェンスを作っているので
ジオフェンス内を移動しているユーザーに対してプロモーションを行う事もできます。
過去はポイントとジオフェンスをもとに
総当たりで Hive/MapReduce の計算を行いイベント回数を計算していたため膨大な時間がかかっていたところを
QuadTree (四分木) を使うことで最適化(この時点で最初の 15 倍高速)
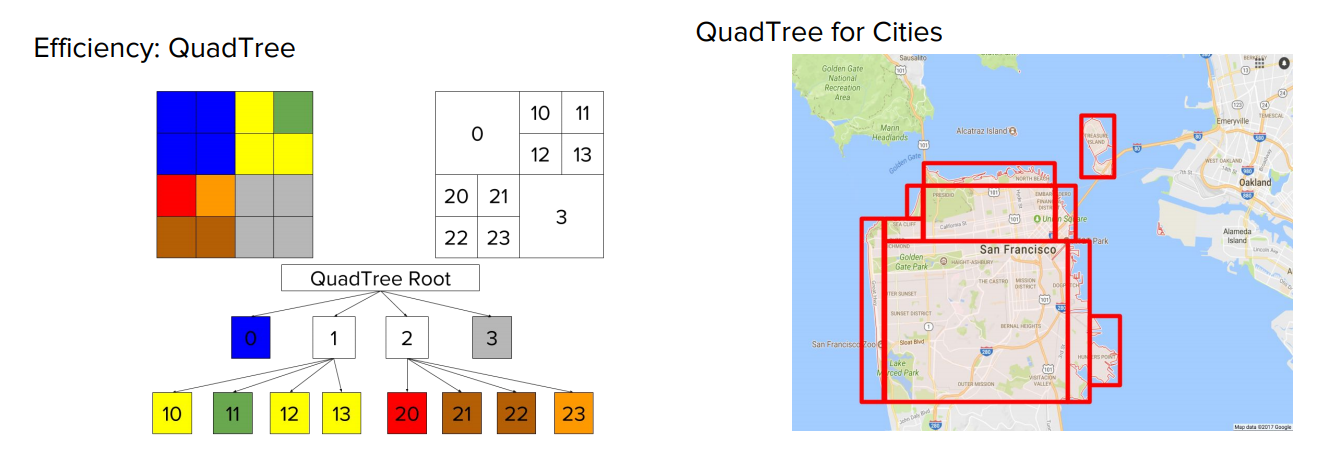
さらに Presto を利用したり、クエリを最適化したり
GeoSpatial Plugin など使うことにより、最終的に 60 倍高速になったとのことです。
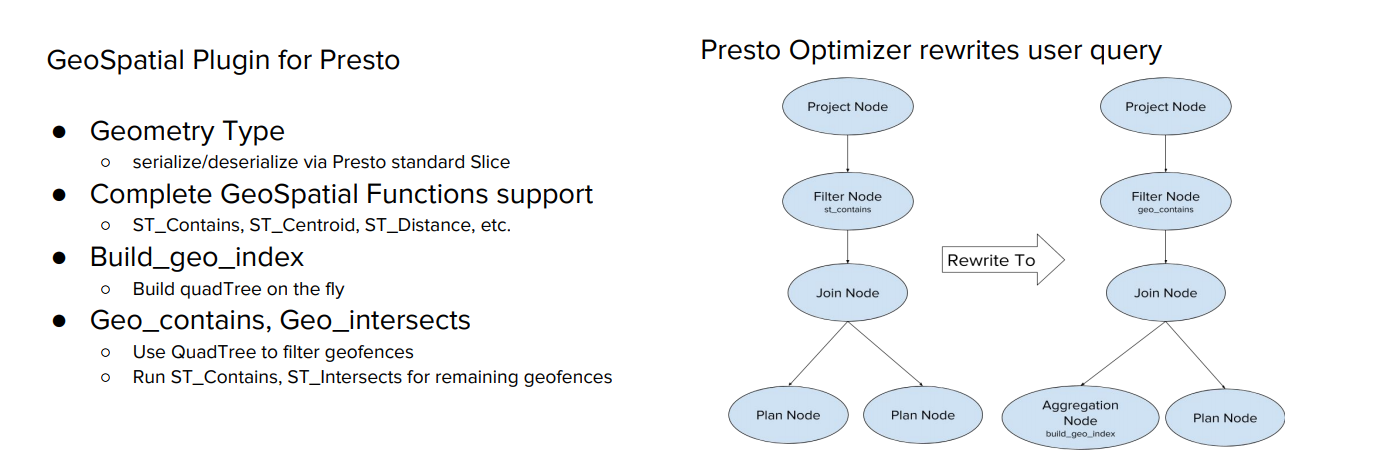
昨年の Starata でも Presto を使って高速化していますという事例や
Presto での最適化はこのような手法でしていますというセッションはいくつかあったのですが
今回は、地理空間データ(位置情報など)に対しても GeoSpatial Plugin というものをしれたり
実際に Hive で遅かった処理が 60 倍まで速くなる というところや、四分木アルゴリズムを使っているところは興味深かったです。
次に水野から, 興味深かったセッションのみ抜粋して紹介します.
Working smarter, not harder: Driving data engineering efficiency at Netflix
サービスの運用コストを削減するためにデータプラットフォーム周りをどのように整備すべきかが紹介されていました.
- Data Catalog周り
- Data Qualityの検知
- Configuration調整のサポート
等が作り込んであるようです.
DataCatalogはMetaCatを使って実現しているとのことでした.データの所在やLineage(データの出自情報)、テーブルへのアクセス状況を管理しており、データの重要度を計測してユーザにレコメンドしたりすることで利用効率を高めているようです.データセットの数が増えてくるとこういう取り組みも必要になってくるだろうなと思いました.
Data Quality周りはデータを取り込んだあとのパイプラインでデータの分布を集計してAnormaly detectionをにかけており異常があれば検知できる仕組みを作っているようです.
Configuration周りの話では、実行時間など設定を一緒に可視化しており、最適なConfigurationはどれだったのか、何故実行が遅いのかなど考察できるサポートをしているようでした.
Rethinking data marts in the cloud: Common architectural patterns for analytics
こちらは,コンピュートとストレージの分離周りのトレードオフにまつわるセッションでした.
簡単にまとめると,S3のような外部のオープンストレージにデータを配置する場合,
- ディスク領域確保の目的にクラスタノードをスケールさせる必要がない (純粋にコンピューティングリソースがたりない場合のみスケールすればよくなる)
- 様々なコンポーネントからアクセスでき,データのサイロ化が防げる
というメリットがある一方で,ローカルディスクに書き出す場合と比べるとどうしても書き出し性能は下がってしまうので,ここにはトレードオフの関係があるという話です.
ただ,以前QConでも類似した内容のセッションがあり,こちらの方が説明も丁寧でわかりやすいのでオススメです.
https://www.infoq.com/presentations/netflix-big-data-infrastructure
7:43から13:54ぐらいまでで,同様の内容に関して議論しています.データを処理しているパイプライン全てでS3に保存するのではなく,パイプラインの途中まではローカルのHDFSに書き出しておいて,処理が終わったデータのみS3に書き出すようにすることで,パフォーマンス上のデメリットはかなり緩和できると述べられています.確かに,自分もこれぐらいの使い方をしておくのががバランスがよいのかなと感じました.
上記の内容に加えてS3はオブジェクトのバージョニング機能も使えるので,データが安全に管理できるという話があったりと,他にも参考になる話がたくさん入っているので,こちらもぜひご覧ください.
End-to-end data discovery and lineage in a heterogeneous big data environment with Apache Atlas
こちらは,Apache Atrasを使ってリッチなデータカタログを構築したという内容のセッションでした.
ここでは,データの所在,出自,スキーマを一元管理しており,どこにどのようなデータがあるのか一目でわかるようになっているとのことです.
データのスキーマとして統一的にAvroのスキーマを利用しており,私の所属するグループで構築している基盤と類似したアプローチをとっていたので非常に親近感が湧きました.ちなみにAtlasにはもともとAvroのスキーマを管理する機能はないので,拡張機能として独自開発したそうです.
UIでスキーマの登録や閲覧時のドリルダウンをサポートしていたり,各フィールドに必ず注釈をつけるようにしているという部分は非常に参考になりました.
また,ユーザビリティと堅牢性のトレードオフに関する議論もあり、SSOT for metadata and lineage, MVOT for dataという考え方が紹介されていました.サイズが大きく、移動させるコストが大きいデータ本体は利便性を考慮して複数散らばっているような状態も許容する.ただし、そのメタデータはSingle Source of Truthとして一元管理すべきという方針で運用されているようです.
出展ブースにもいくつかデータカタログ周りの製品が展示されていたりと,データガバナンス周りの話は,カンファレンス全体を通してホットな分野になってきているなと感じました.
Author