Blog
ONNXモデルのチューニングテクニック (応用編1)
サイバーエージェント AI Lab の Conversational Agent Team に所属している兵頭です。今回は私が半年ほど蓄積したONNXのチューニングテクニックを全てブログに残したいと思います。皆さんが既にご存知であろう基本的なことから、かなりトリッキーなチューニングまで幅広くご紹介したいと思います。長文になりますがご容赦願います。今回は応用編1です。
このブログのメインターゲット層は「リサーチャーが実装したモデルを実環境へデプロイするタスクを有する方々」です。一部リサーチャーの方々の参考になる情報が混じっていることもあるかもしれませんが、あまり興味を引かない内容だとは思います。リサーチャーメインの組織に属しながらリサーチエンジニアの立ち位置で身を投じていますので、研究の観点の少し手前あるいは少しその先の部分を担っている立場からこのブログを記載しているものとご認識願います。
いきなりですが、我々のチームでは一緒に Human Computer Interaction の研究・開発を行っていただけるリサーチエンジニアを募集しています。本ブログを見てご興味を持って頂けた方は是非一度カジュアルにお話させてください。よろしくお願いします。
-
クリックするとYouTubeへ遷移します。

7. モデルのチューニング [応用]
基礎編 では、単一層のモデルやオペレーションの生成方法、簡易的なベンチマーク方法の一例をご紹介しました。今回は応用編として一歩踏み込んだモデルチューニングのテクニックをご紹介していきたいと思います。試行環境の構築方法やONNXの基本構造などをご理解いただいていることを前提として書き進めますので、基礎編 をご覧になっていない方はご一読いただいてからこちらの記事を読み進めていただくほうが理解が進みやすいと思います。この章では、simple-onnx-processing-tools に列挙されているツールをユースケースと利用方法を併せて上から順番にご紹介します。
7-1. モデルの融合 (snc4onnx)
2種類以上のモデルを1つのモデルへ融合します。これはあまり現実的なユースケースではないかもしれませんが、例えばVision系のモデル2種類であれば、1枚の2D画像を2つのモデルで1つの入力テンソルとしてシェアしつつ、1回の推論で2つのモデルの推論結果を同時に得られるようにすることができます。また、完成されたモデルではなくコンポーネントとしてバラバラにストックされたモデルを融合してひとつの end-to-end モデルへ構成することもできます。具体的に例を挙げてご紹介します。
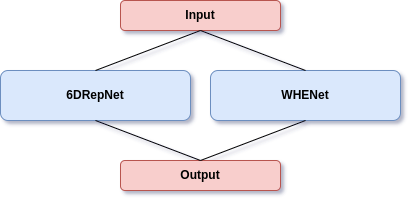
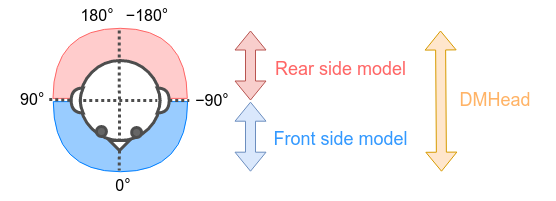
分かりやすく2種類の論文実装モデルを1つのモデルに融合してみます。DMHead に動作イメージの動画やサンプルコード、実際に融合済みのONNXモデルをコミットしてあります。顔面あるいは頭部の6軸角度を推定するモデルです。イメージは下図のとおりです。
| モデル | 概要 |
|---|---|
| 6DRepNet (RepVGG-B1g2) or SynergyNet (MobileNetV2) |
顔前面の概ね -90°から+90° 範囲の Yaw, Roll, Pitch を高精度に検出するモデルです。図中の青い文字 Front side model と表現されている部分の推論を担当するモデルです。 |
| WHENet (EfficientNet-b0) |
後頭部を含む 360° の Yaw, Roll, Pitch を検出可能とうたっているモデルです。図中の赤い文字 Rear side model と 青い文字 Front side model で表現されている部分の両方の推論を担当するモデルです。360° 一周分の方向を推定できますが精度がそれほど高くありません。また、Front side model の推論範囲と重複します。 |
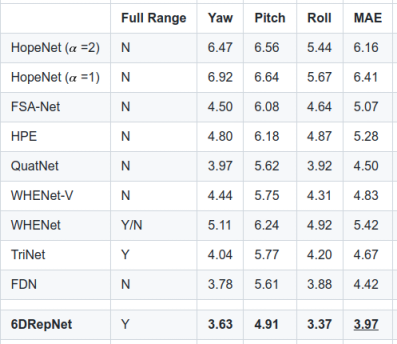
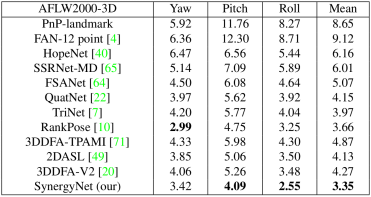
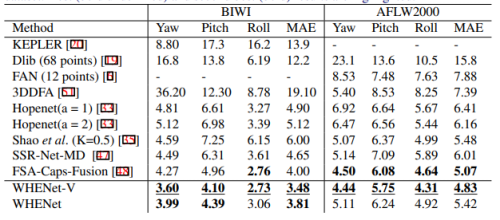
論文に記載されている定量的な評価は下表のとおりです。平均絶対誤差(MAE:Mean Absolute Error)つまり、MAE の数値が小さいほど実態との乖離が小さいということです。実際にワイルドな環境下で試さないと分からないことなのですが、SynergyNet は指標上はとても性能が高く見えますが、マスクを着用したり、実際にマスクを着用した画像でトレーニングを行うと著しく性能が劣化します。整った条件下でないと論文指標どおりの性能は一切出ません。ただ、ベースモデルが MobileNetV2 ですので超軽量です。一方で、6DRepNet はベースモデルの性能が高いためか、マスクを着用した顔画像を使用してトレーニングを行うと論文指標を上回る性能が出ます。VGG16 の改良版 RepVGG-B1g2 を使用しているため、重みの大きさとは裏腹に若干動作が速いですが、やはりトレードオフで MobileNetV2 に比べると動作が重たいと言わざるを得ません。また、6DRepNet と SynergyNet は正面を向いた顔しか推定できませんが、WHENet だけは後方を向いた後頭部でもある程度角度を推定できます。つまり、それぞれのモデルに一長一短があるため、それぞれのモデルのメリットのみを抽出したいというユースケースがあると仮定します。
-
6DRepNet (RepVGG-B1g2) – 引用:https://github.com/thohemp/6DRepNet
-
SynergyNet (MobileNetV2) – 引用:https://github.com/choyingw/SynergyNet

-
WHENet (EfficientNet-b0) – 引用:https://github.com/Ascend-Research/HeadPoseEstimation-WHENet
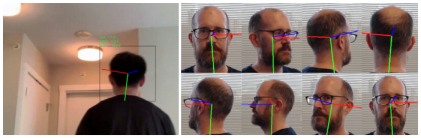
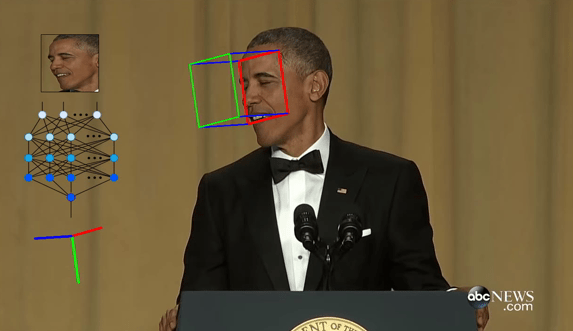
下図のように、正面を向いた状態と後方を向いた状態の360°の範囲をできるだけ精度高く保ったまま6軸推定できるモデルを生成します。青色の枠は前向き、赤色の枠は後ろ向き、紫は中間ぐらい、というグラデーションで向いている方向が視認しやすいように表現しています。また、青の棒は Yaw、赤の棒は Roll、緑の棒は Pitch の角度を表します。これらのモデルは物体検出による顔位置の特定までは行わず、あくまで与えられた顔画像の6軸角度のみを推定するモデルですので、顔位置の検出には別途軽量な物体検出モデルを使用する必要があります。サンプル画像は YOLOv7-tiny を頭部画像データセットを使用してセルフトレーニングしたカスタムモデルを使用して頭部検出しています。全てのコンポーネントをNバッチ化済みですので、RAMの上限を超えない限り物体検出モデルからの出力内容を1度に何人分でも同時に投入できます。サンプル画像は15人同時に検出していて、物体検出と顔向き推定と全ての前処理と後処理を合算して20ms弱です。TensorRTですので速いです。

では、さきほどご紹介したとおり、正面側の精度が高い 6DRepNet と後方を検出できる WHENet を snc4onnx を使用して融合します。
使用するモデル・コンポーネントの概要です。大きく分けて合計4つのコンポーネントを融合します。個々のオペレーションの生成方法は 基礎編 でご紹介済みですのでここでは取り上げません。画像がガタガタしてしまっている点はご容赦願います。
| モデル・コンポーネント | 概要 |
|---|---|
| 6DRepNet 157MB | N個の顔画像を受け取り、N個の正面側Yaw,Roll,Pitchを出力します。公式リポジトリの PyTorch のロジックを使用してONNXモデルを生成しました。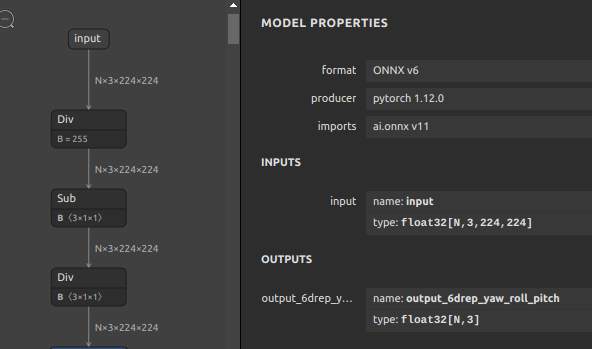 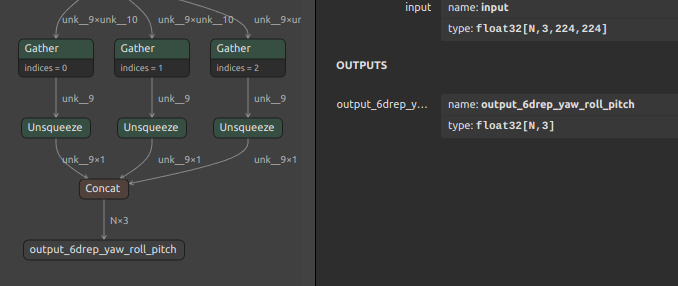 |
| WHNet 17MB | N個の顔画像を受け取り、N個の全方位のYaw,Roll,Pitchを出力します。公式リポジトリの Keras のロジックを使用してONNXモデルを生成しました。生成難易度が高いですが、こちらに作業メモを残していますので気になる方はご覧ください。WHENetのエクスポート Pickleの形式に互換性が無くなってしまった Python3.5以前のレガシーな環境が必要です。なお、トレーニングコードが公開されていないため手軽に重みをチューニングすることはできませんが、ONNXに変換してしまえばこのブログのテクニックを使用してモデル構造を自由に書き換えることはできます。すでに非公式にモデル構造を改変してバッチ処理化した状態です。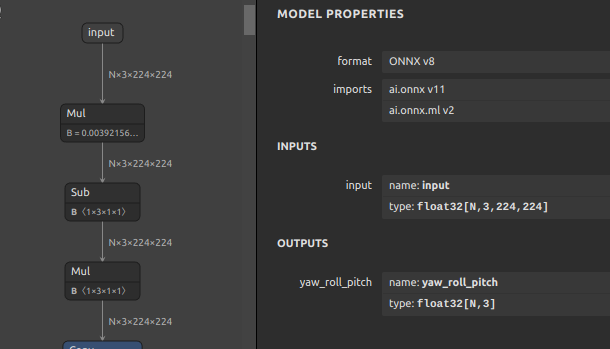 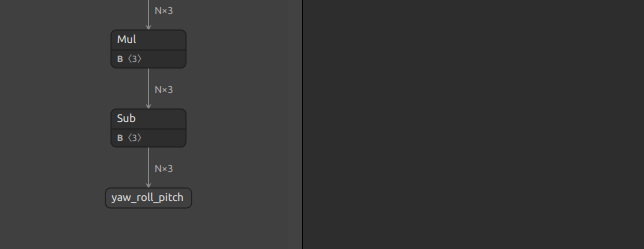 |
| shrunk_6drepnet_N | 6DRepNetの出力のうちYawを-75°〜+75°の範囲のみ活性化するコンポーネントです。N個のYaw,Roll,Pitchを受け取り、YawをカットしたN個の出力を得ます。このコンポーネント自体も事前に snc4onnx を使用して複数のオペレーションをマージした状態です。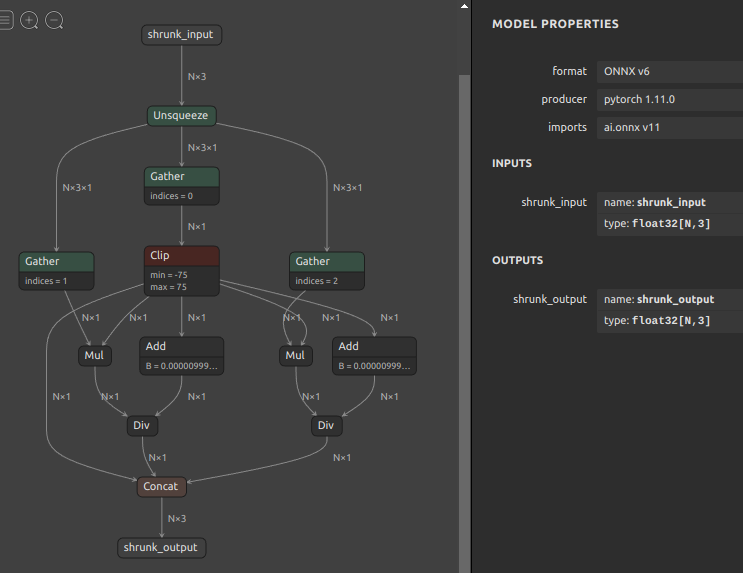 |
| shrunk_whenet_N | WHENetの出力のうちYawを-76°〜-180°および+76°〜+180°の範囲のみ活性化するコンポーネントです。-75°〜+75°の範囲の角度を0°に補正します。N個のYaw,Roll,Pitchを受け取り、YawをカットしたN個の出力を得ます。このコンポーネント自体も事前に snc4onnx を使用して複数のオペレーションをマージした状態です。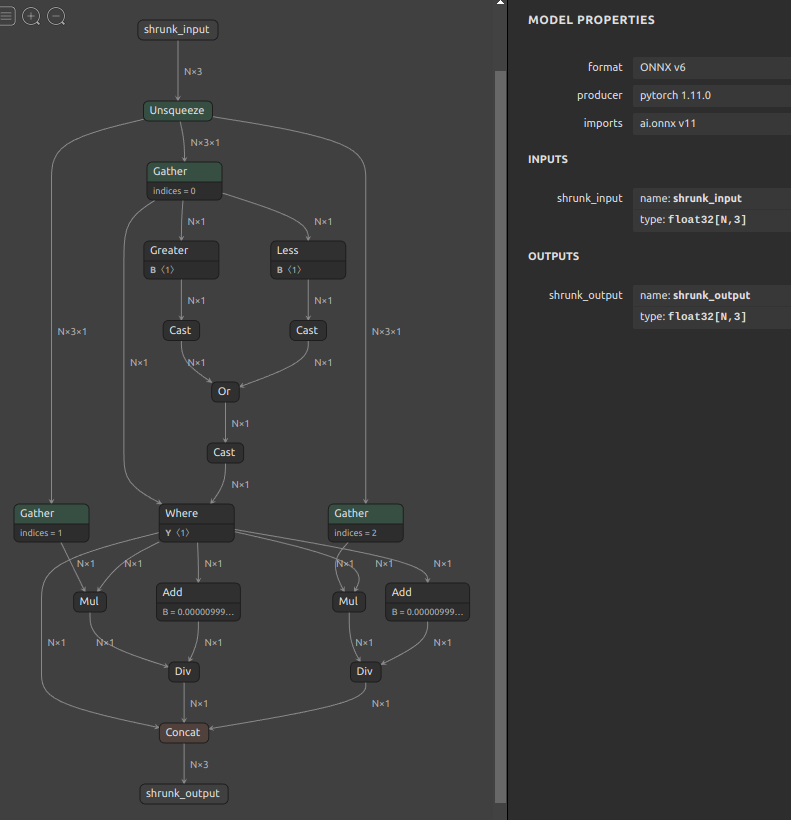 |
2つのモデル、2つのコンポーネントをどのような順番で融合しても問題ありませんが注意点があります。どちらかというとコンポーネント生成時に注意すべき点です。
- 融合したモデル内でオペレーションの名前が重複しないように全体で一意なネーミングにしておくこと
- モデルのINPUT/OUTPUTの名前もオペレーションの名前と同様にモデル全体で一意なネーミングにしておくこと
- 融合するAとBのコンポーネントの結合部は同じ形状なおかつ同じ演算精度にしておくこと
の3点です。
前置きが長くなりましたが融合してみます。ファイル名が長くパラメーターの切れ目が分かりくいですので、あえて改行とインデントを多めに入れて転記しています。
6DRepNetとshrunk_6drepnet_Nを融合123456789snc4onnx \--input_onnx_file_paths \sixdrepnet_300w_lp_maskplus_prepost.onnx \shrunk_6drepnet_N.onnx \--srcop_destop \output_6drep_yaw_roll_pitch \shrunk_input \--output_onnx_file_path \sixdrepnet_300w_lp_maskplus_prepost_disable_rear_side_detection_Nx3x224x224.onnxWHNetとshrunk_whenet_Nを融合123456789snc4onnx \--input_onnx_file_paths \whenet_Nx3x224x224_prepost.onnx \shrunk_whenet_N.onnx \--srcop_destop \yaw_roll_pitch \shrunk_input \--output_onnx_file_path \whenet_prepost_disable_front_side_detection_Nx3x224x224.onnx- 1.と2.を融合
1234567891011snc4onnx \--input_onnx_file_paths \whenet_prepost_disable_front_side_detection_Nx3x224x224.onnx \sixdrepnet_300w_lp_maskplus_prepost_disable_rear_side_detection_Nx3x224x224.onnx \--srcop_destop \input \input \--op_prefixes_after_merging \whenet \6drepnet \--output_onnx_file_path dmhead_merged_N.onnx
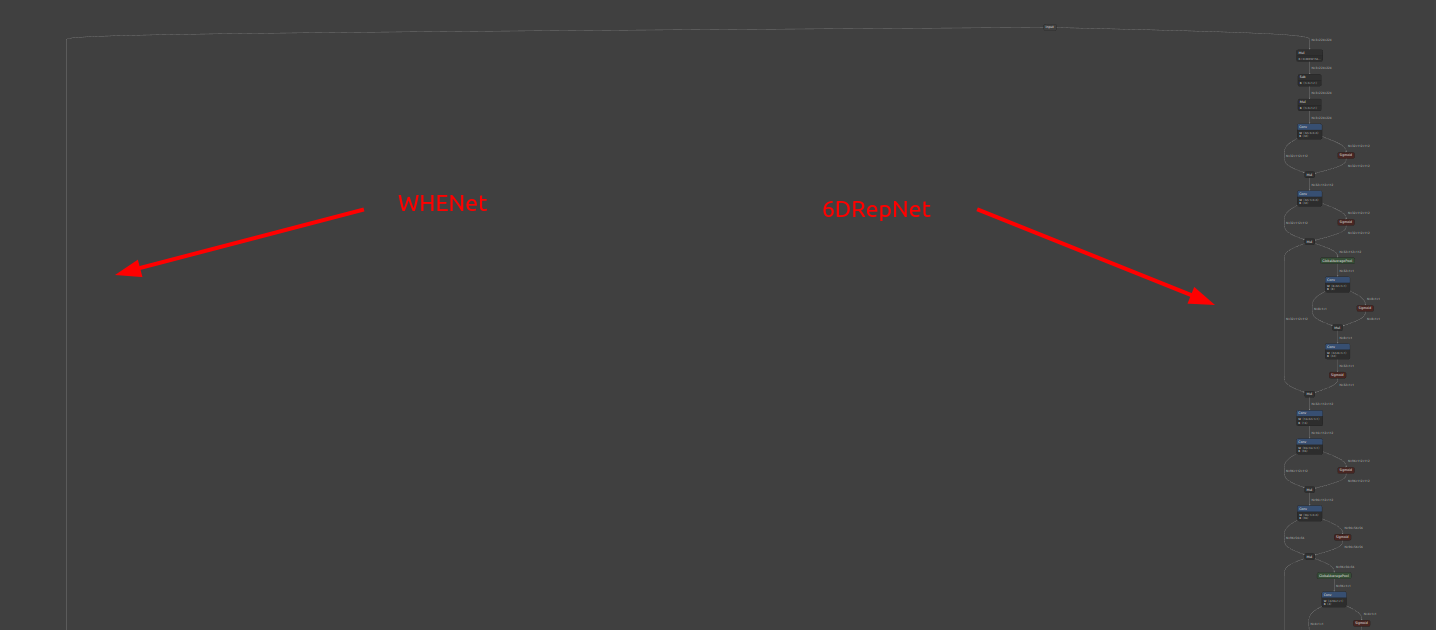
2種類のモデルを融合したため可視化すると横幅が大きくなりすぎて少々見づらいですが、左側が WHENet、右側が 6DRepNet のフローです。入力テンソルが2つのモデルで共用されている点と、出力の最終部で2つのモデルの出力を合算して推論結果を合成しています。単純加算で合成できる理由は少し前でご説明したとおり、2つのコンポーネントで出力の活性化と非活性化の角度範囲を制御していたからです。2つのモデルの出力角度がなるべく重複しないように(100%ではありません)調整されているため単純加算で乗り切れる状態になっていました。つまり、同じ角度範囲で2つのモデルからなるべく同時にゼロより大きい数値が出力されることが無いように調整したということです。最後の Add の部分は単純加算になっており境界付近では不安定になることが若干ありますので改善の余地があります。
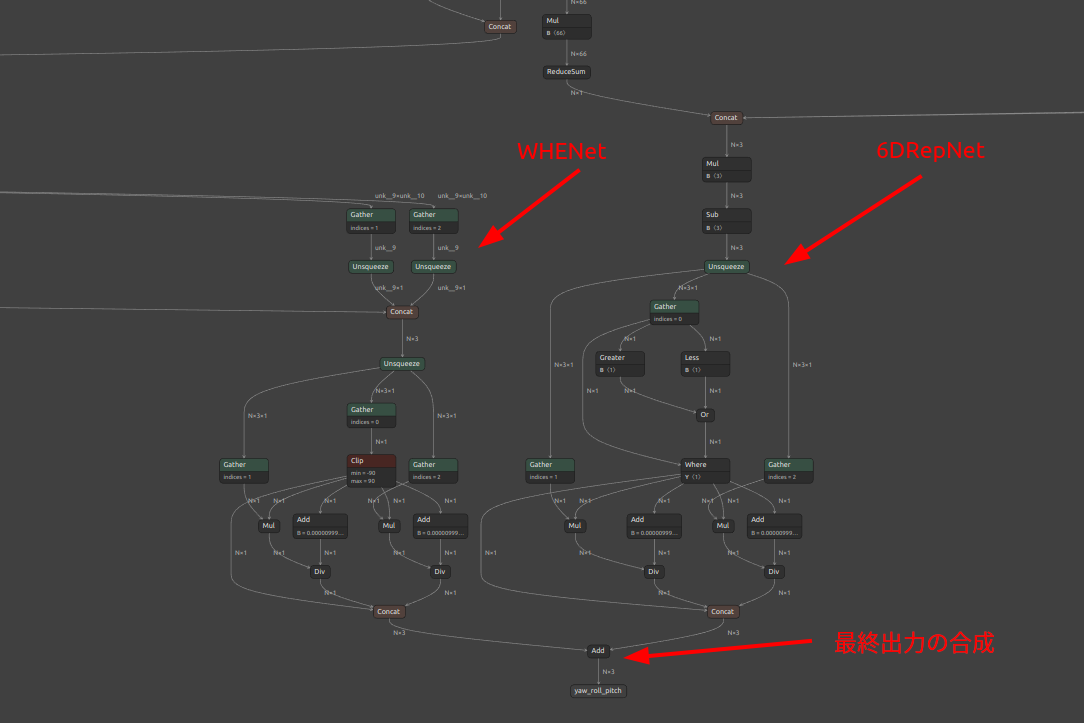
-
結果
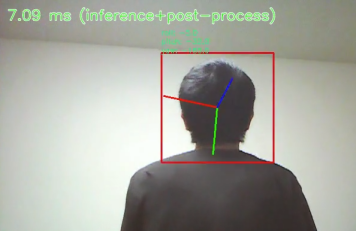
6DRepNetはファインチューニングしてマスク顔に対応し、さらに論文性能より0.11ポイント精度を向上した自作モデルを使用しました。前後ともに検出力はまずまずのようです。126DRepNet: Yaw: 3.31, Pitch: 4.90, Roll: 3.36, MAE: 3.86WHENet: Yaw: 5.11, Pitch: 6.24, Roll: 4.92, MAE: 5.42-
6DRepNet側で検出

-
シームレスにWHENet側で検出
-
snc4onnx のパラメータを転記するとブログが無用に長くなってしまいますので、応用編では詳細仕様が記載されたREADMEのURLのみご案内します。
ここまででモデルやコンポーネントの融合のテクニックをご紹介しましたが、このようなユースケースが活きると考えているのは、特定のタスクに特化した強力で軽量な部品単位のモデルを複数準備しておき、最終的には1つのモデルに融合して、実質マルチタスクに近いモデルをトレーニング後に自由に生成できるというところです。
7-2. モデルの分離 (sne4onnx)
1つのモデルを分離します。モデルの途中の特定のオペレーションの出力内容をデバッグするときや、7-1. モデルの融合 のようなユースケースでコンポーネントとして使用するためにモデルの一部分を抽出するとき、ハードウェアアクセラレータや推論フレームワークのバグを回避するためにモデルの一部分を別のコンポーネントに差し替える場合などがユースケースとして考えられます。また、世界中のリサーチャーが設計してくれたモデルは、実環境に投入して高効率に推論することまでを想定した綺麗なモデル構造になっていないことが多く、onnx-simplifier で最適化処理を施したときにAbortしてしまったり、モデルの最適化が十分に適用されないことが多いです。リサーチャーの観点からすれば、モデルを効率的に運用することや高パフォーマンスで推論することまでを想定しながらモデル設計することは本懐ではないと私自身は考えていますので、モデルの最適化タスクはエンジニアのタスクである、と割り切っています。リサーチャーが設計してくれた良いモデルを更に最適化するために、最適化が可能な範囲にモデルを分離して最適化を施し、のちに最適化済みのコンポーネント同士を再結合して全体を最適化したモデルを再構成する場合などが最もユースケースとして多いです。たとえば、一例でしかありませんしPyTorchのロジックをくまなく読み込んで自分で改修すれば問題ない事例ではありますが、Reshape の形状変更時に -1 が指定されたものが含まれているモデルはバッチ処理化をするときにAbortします。利用するエンジニア目線では -1 をできる限り指定してほしくないです。何故 Reshape に -1 が指定されている状態でバッチ処理化するとAbortするかという理由に触れておきます。Reshape後の形状指定が仮に [1,3,-1,512] だったとします。これをバッチ処理化するとどうなるかというと [-1,3,-1,512] となります。Reshape を行ったあとの出力の形状は分かりますでしょうか? 無理です。つまり、ONNXに限らずどのフレームワークを使用したとしてもこの状況になるとAbortします。実質バッチ処理化して使えないモデルです。なお、-1 を指定した数値に書き換えるトリックは後続の節でご紹介します。
では、今回はとてもシンプルなモデルを分離してみます。MNIST – Handwritten Digit Recognition mnist-12.onnx
まず、onnx/models で公開されているサンプルONNXファイルをダウンロードし、基礎編でご紹介した onnxsim (onnx-simplifier) を3回実行してモデルの冗長さを排除します。
|
1 2 3 4 |
curl -OL https://github.com/onnx/models/raw/main/vision/classification/mnist/model/mnist-12.onnx onnxsim mnist-12.onnx mnist-12.onnx onnxsim mnist-12.onnx mnist-12.onnx onnxsim mnist-12.onnx mnist-12.onnx |
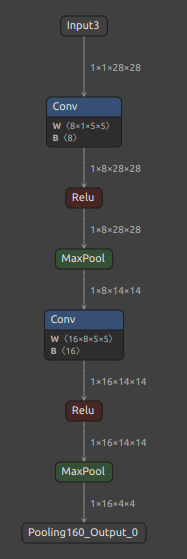
最適化後の MNIST ONNX の構造は下図のとおりです。
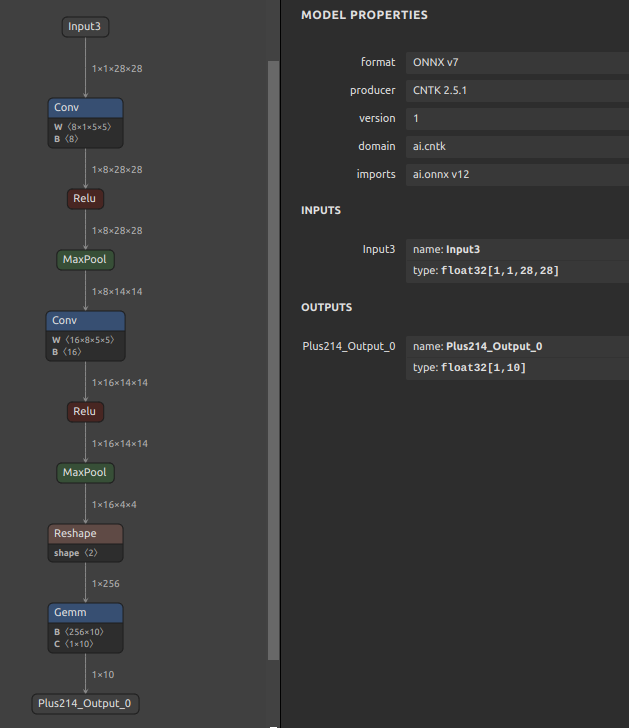
今回はモデルを分離してコンポーネント化する方法のご紹介のみにとどめるため、ユースケースに基づくモデルの分離ではない点にご注意願います。
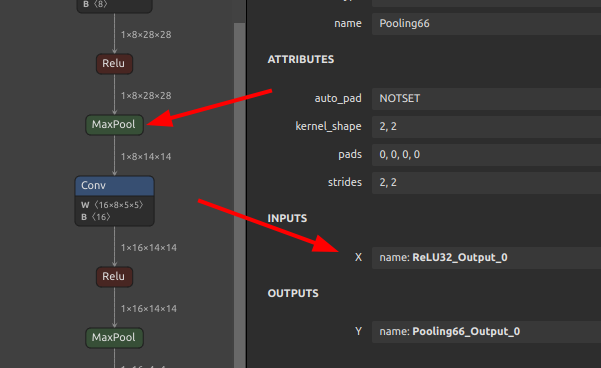
では、下図の MaxPool の Pooling160_Output_0 の出力部分でモデルを分断してみます。分離をスタートするINPUT OPの名前と分離の終端となるOUTPUT OPの名前の両方を指定します。
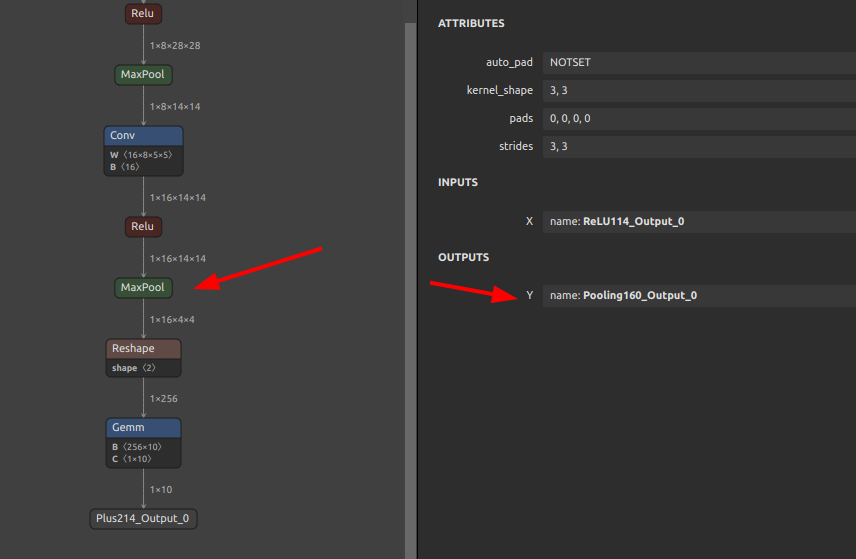
|
1 2 3 4 5 |
sne4onnx \ --input_onnx_file_path mnist-12.onnx \ --input_op_names Input3 \ --output_op_names Pooling160_Output_0 \ --output_onnx_file_path mnist-12_part.onnx |
分離されたONNXファイルが生成されました。Reshape と Gemm に含まれていた定数がモデルから除かれたかたちになりますのでファイルサイズが大きくシュリンクしているのが見て取れます。
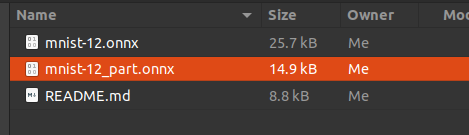
| Before | After |
|---|---|
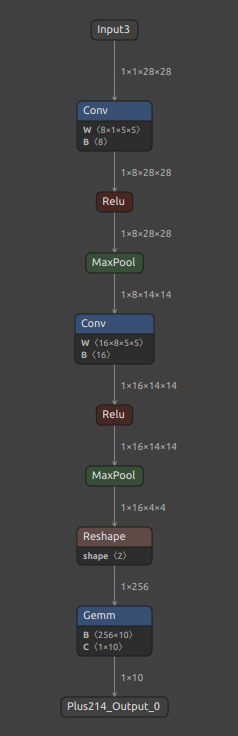 |
 |
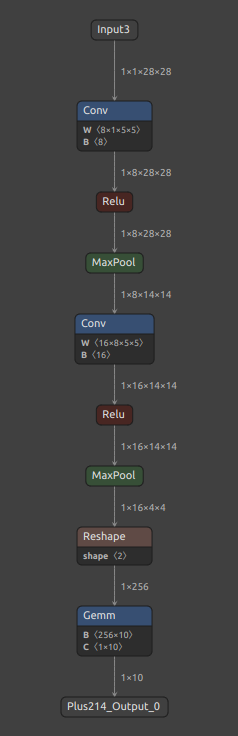
当然ながら、モデルの中間部分のみを分離することもできます。2つの MaxPool で挟まれた区間を分離してみます。
|
1 2 3 4 5 |
sne4onnx \ --input_onnx_file_path mnist-12.onnx \ --input_op_names ReLU32_Output_0 \ --output_op_names Pooling160_Output_0 \ --output_onnx_file_path mnist-12_part2.onnx |
分離したONNXファイルが生成されました。 Conv に含まれていた定数がモデルから除かれたかたちになり、さらにモデルサイズがシュリンクしました。
| Before | After |
|---|---|
 |
 |
なおこのツールは、複数のINPUT NameとOUTPUT Nameを同時に指定することでひとつのモデルから複数の始点と複数の終点を持つモデルを抽出できるようにしてあります。 ONNXの標準API にも同様の処理が実装されていますし、onnx-graphsurgeon にも同様のインタフェースが用意されていますが、Pythonのソースコードを駆使してロジックを組み立てる必要があるため少々手間です。ちなみに、Idein さんも同じ思想で同様のツールを提供されています。onnigiri “The purpose of this package is to create subgraphs by partitioning computational graphs in order to facilitate the development of applications.” 私は完全にひとりでツールを作成していますので、Ideinさんのようにお仕事で作成されているツールをご利用いただくほうが運用の継続性の観点からはメリットがあると考えています。
7-3. Nodeの削除 (snd4onnx)
ONNXの標準APIや onnx-graphsurgeon を使用したPythonコードで表現するときにはかなり手間が多く複雑な操作です。そもそも、削除 という行為は複数のプリミティブな操作を組み合わせて実現する必要があり、コード量が若干多くなります。具体的には、
- モデルを指定のNodeの入出力位置で上下に分断してコンポーネント化する
- 削除対象のNodeをモデルから削除する
- 分断した上下部分のコンポーネントの終端と始端が同じ形状および同じ算術精度であることをチェックする
- 1.で分断した上下のコンポーネントを削除後の断面の入出力変数で結合しなおす
- 全てのコンポーネントを再結合して生成しなおしたモデルの構造が破綻していないかチェックする
- モデルをONNXファイルとして再出力する
という流れです。意味不明ですよね。でも、正常にモデルからNodeを削除するために必要な手番はこれだけあります。無理にこの節でご紹介するツールを使用しようとするとうまくNodeが削除できないパターンが多いですが、シンプルな構造のモデルであれば直感的に実施できます。実際に試してみます。snd4onnx というツールを使用します。
非常に限られたユースケースしかありませんが、不必要な cast を削除したり、フレームワークのバグを回避するための下準備として特定のNodeを削除する場合、などが該当します。
前節で使用した mnist-12.onnx を再び使用します。
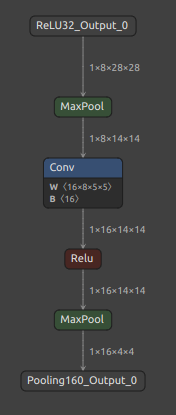
意味の無い操作ですが、Conv の次にある Relu を削除してみます。
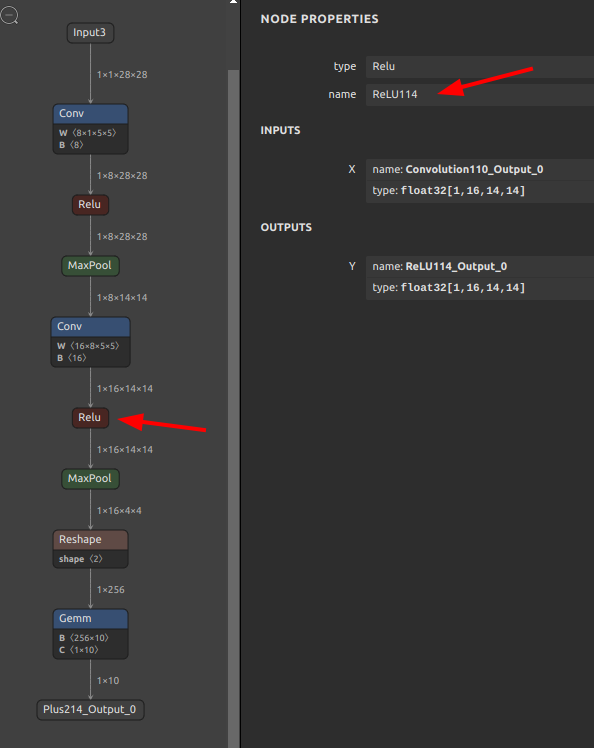
|
1 2 3 4 |
snd4onnx \ --remove_node_names ReLU114 \ --input_onnx_file_path mnist-12.onnx \ --output_onnx_file_path mnist-12_del.onnx |
ONNXファイルが生成されました。
削除対象に指定した Relu Node名 ReLU114 がモデルから削除され、Conv と MaxPool が直結した状態のモデルが生成されました。
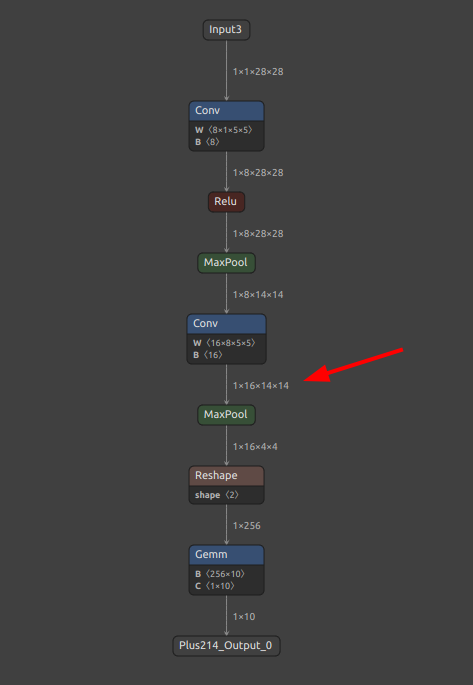
簡単にNodeが削除されてしまいましたが、現実的なシチュエーションでは複数の入力があるNodeや複数の出力があるNodeを削除したいことが多いと思いますので、このツール単体で手軽に実施できるパターンはごく限られています。削除はできても再接合部の形状不一致のワーニングやエラーが頻繁に出ます。あまり手を抜かず、他のツールを組み合わせて慎重にモデルをチューニングしたほうが確実です。
7-4. モデルサイズの圧縮 (scs4onnx)
これは 基礎編 でご紹介した onnx-simplifier を使用して最適化したONNXモデルを更にサイズ圧縮するためのテクニックを検証するために独自に考えた手法ですので、あまりユースケースとしては適切ではありません。したがいまして、ツールの使用方法や効果をこのブログで詳しくご紹介することはあえてしませんが、気になる方は scs4onnx のREADMEをご覧ください。
詳細には触れませんが、このツールのコンセプトだけを簡単にご説明します。
onnx-simplifierで各種オペレーションを最適化・定数化する過程でモデルが肥大化することがある- モデルが肥大化する原因は定数に置き換えられた画像のパッチ化処理などに必要となる大量のINT64精度のインデックス値など
- INT64 は 64bit で値を保持するため、定数化されたテンソルの
要素数 x 64bitの容量がモデルに埋め込まれる - したがって、INT64 で埋め込まれた定数を INT32 などのより低精度な定数へ置換することでモデルのサイズを圧縮する
- INT32であれば50%、INT16であれば25%、INT8であれば12.5% まで圧縮できる
- ONNXファイル内部で複数回登場する定数を共用定数としてひとつに集約する
- ONNXファイルから指定した定数のみを外部ファイル.npyへ切り出してONNXファイルを軽量化できる
このツールで効果が出るモデルは限られていますが、念の為結果の画像だけ貼り付けておきます。最も効果が高かったモデルでは、1.8GB あったONNXファイルが 2.1MB まで圧縮できました。ただし、ONNX本体から巨大な定数を外部ファイル(.npy)に抽出した結果です。量子化は行いませんので一切精度劣化はしません。
-
297.8MB -> 67.4MB (.onnx)

-
1.8GB -> 2.1MB (.onnx) + 884.7MB (.npy)

ツールの仕様でちょっとだけ面白い点に触れさせて頂くとすれば、モデル内部の定数部分を xxx.npy というNumpyのndarray形式のバイナリファイルにエクスポートする機能があることです。下図のクラゲのように線が伸びている部分が xxx.npy ファイルから読み出したテンソルを入力するための入力OPです。xxx.npy へエクスポートするタイミングで自動的にモデルへ入力OPを追加します。クラゲのようにひとつの入力OP部から複数の線が伸びているのは同じ定数を使用するOPが線の本数分だけ存在することを表します。したがって、xxx.npy へエクスポートしたONNXの定数は 再利用されるOPの数 x 定数のサイズ だけ圧縮されます。実は、繰り返し登場する同じ定数を集約するだけでモデルファイルの全体サイズを圧縮する効果はかなり大きいです。xxx.npy ファイルへ抽出しなくても scs4onnx を実行するとデフォルトの動作で定数を自動集約してファイルサイズを圧縮したONNXファイルを再出力する仕様にしています。定数を集約する、の意味がいまいちイメージできない方は 基礎編 の 5-1. ONNXモデルの構造 をご覧いただき、定数の名前を複数のNode間で共用するだけで簡単に実現できるトリックであることをご確認ください。プログラムで変数や定数を使い回しすることと概念に違いはありません。initializer 部で定義した定数の rawData を複数のNodeから参照することができる仕組みです。使い方として成り立つのかどうかが分かりませんが、モデルに投入する定数を推論ごとに差し替えることもできますね。意味不明ですが。もしかすると、定数部分を外部ファイルに抽出できているので、外部ファイルに抽出された定数ファイルのみを暗号化して秘匿してしまうとか、イロイロと遊べそうな要素がありそうです。復号化ロジックをどのように隠蔽するのかは考えていません。
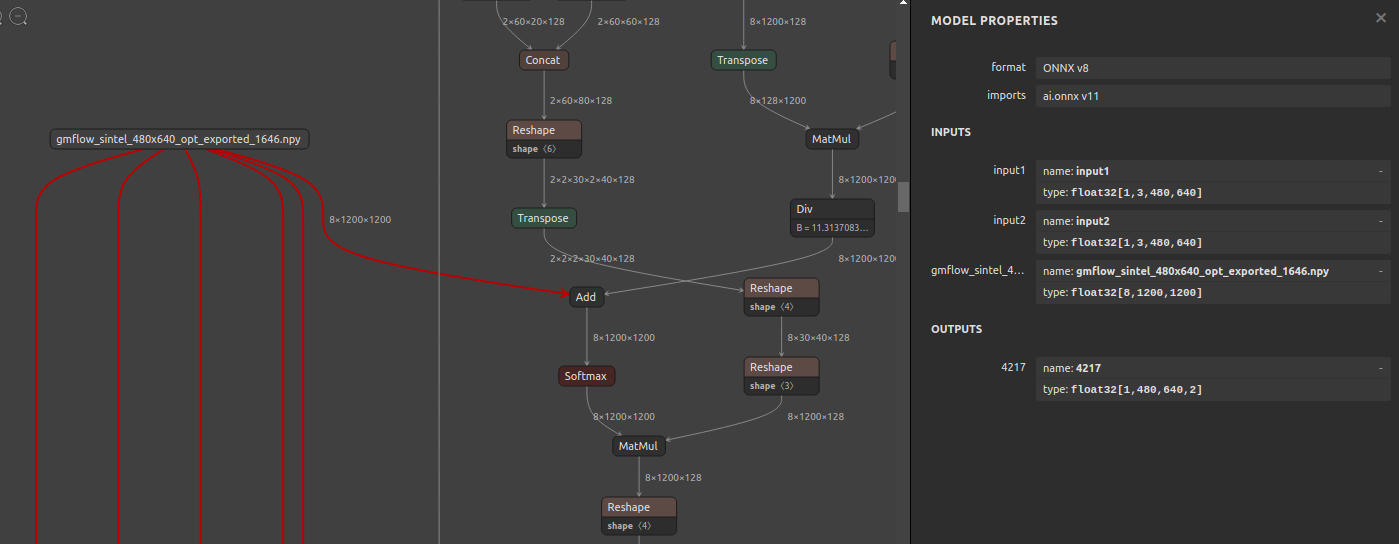
具体的な仕様が気になる方はこちらの scs4onnx の README をご覧ください。
7-5. Nodeの生成 (sog4onnx)
基礎編 の 5-3. Node生成 でご紹介しましたので応用編では説明を省略します。
7-6. Nodeの属性値や定数の書き換え (sam4onnx)
モデルのチューニングを行ううえで最も使用頻度が高くなるであろうツール sam4onnx をご紹介します。このツールでできることを直感的に把握していただくために、先に画像で結果をご覧ください。
-
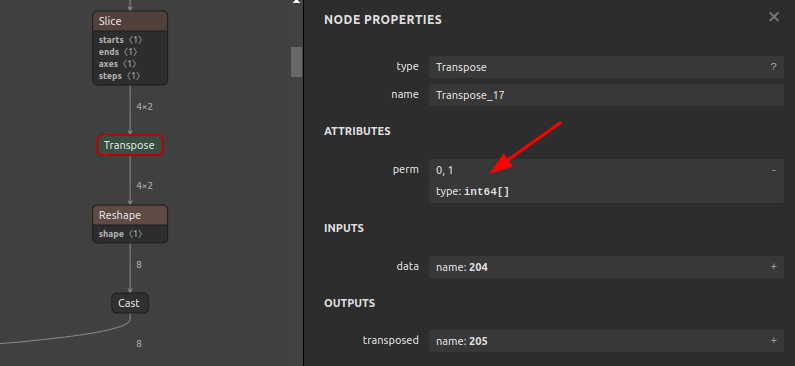
Transposeのperm属性の書き換え例Before After 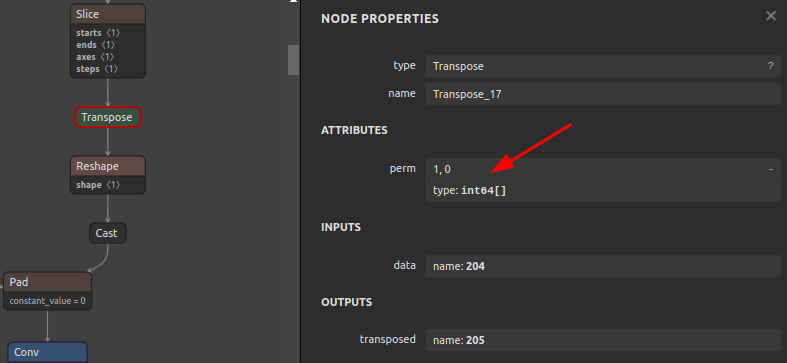
-
Mulに埋め込まれた定数の書き換えBefore After 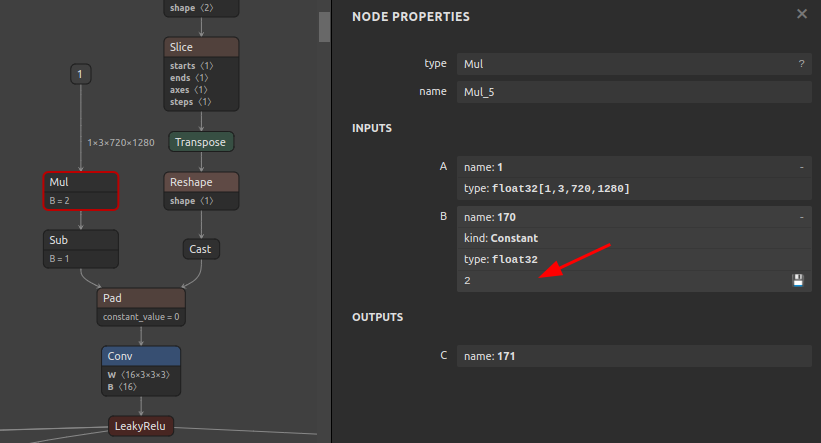
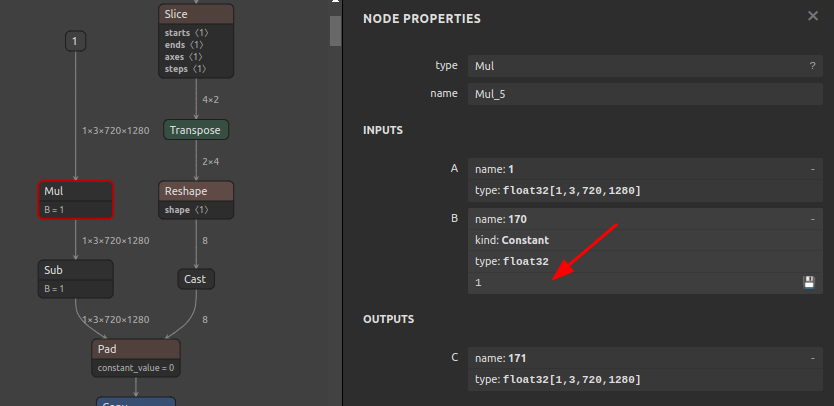
-
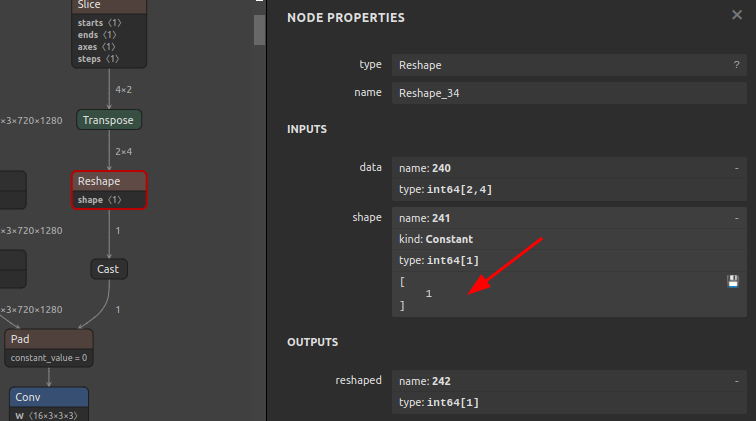
Reshapeに埋め込まれたshape定数の-1を1に書き換えBefore After 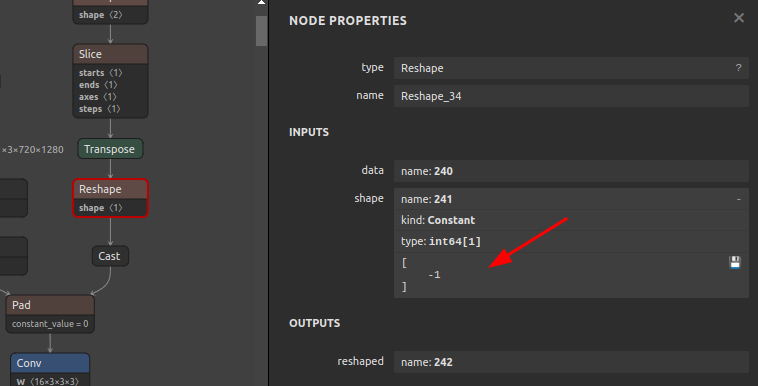
-
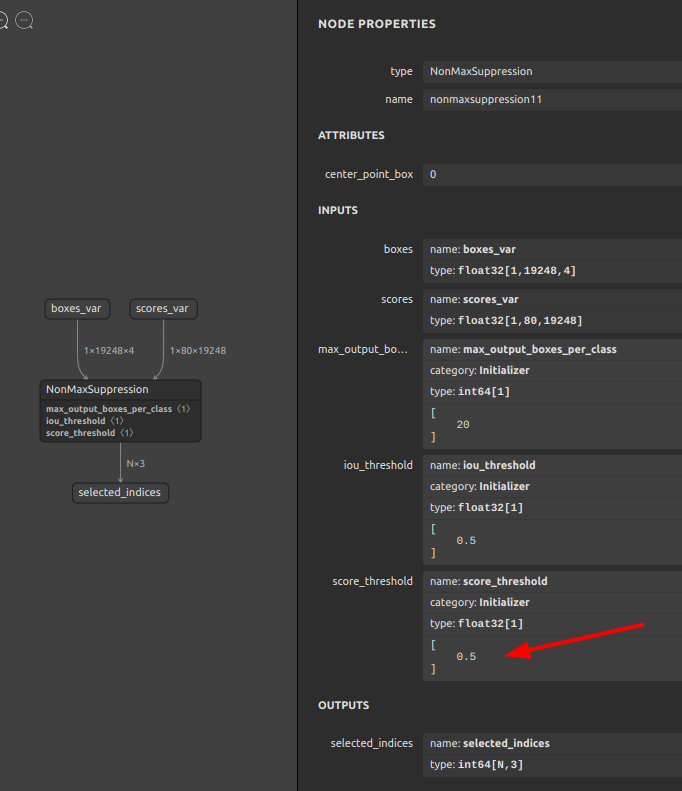
NonMaxSuppressionに埋め込まれたscore_threshold定数の-Infinityを0.5に書き換えBefore After 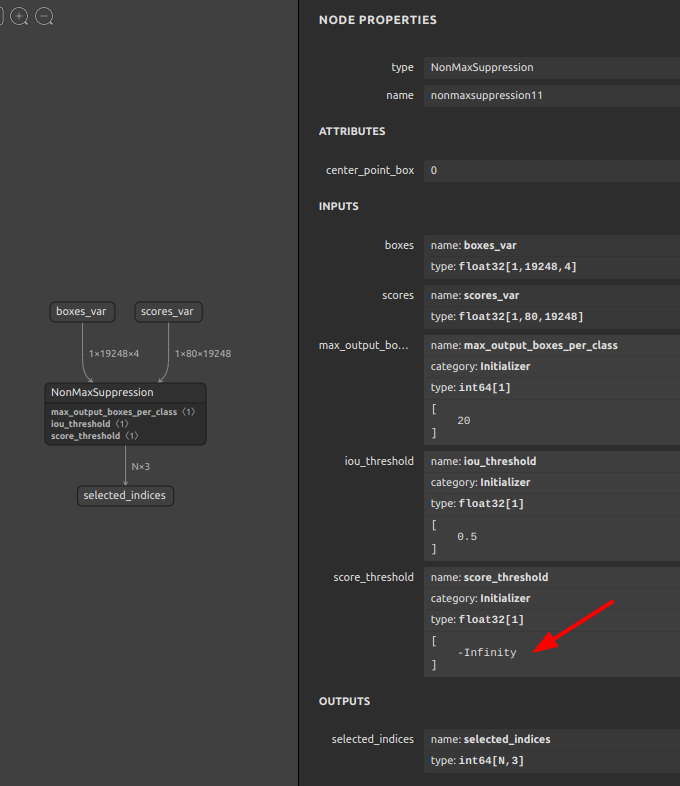
本質的には類似のコマンドを実行するだけなのですが、1. と 3. と 4. のコマンドを例示します。各Nodeの属性や変数・定数に指定可能な値の種類や精度はONNX公式の一覧表をご覧ください。 ONNX Operator Schemas
-
Transposeのperm属性の書き換え例OP名
Transpose_17の属性値permを[1,0]から[0,1]に書き換える12345sam4onnx \--input_onnx_file_path input.onnx \--output_onnx_file_path output.onnx \--op_name Transpose_17 \--attributes perm int64 [0,1] -
Reshapeのshape定数の書き換え例OP名
Reshape_34の入力定数241を[-1]から[1]に書き換える12345sam4onnx \--input_onnx_file_path input.onnx \--output_onnx_file_path output.onnx \--op_name Reshape_34 \--input_constants 241 int64 [1] -
NonMaxSuppressionのscore_threshold定数の書き換え例OP名
nonmaxsuppression11の定数score_thresholdを[-Infinity]から[0.5]に書き換える12345sam4onnx \--input_onnx_file_path input.onnx \--output_onnx_file_path output.onnx \--op_name nonmaxsuppression11 \--input_constants score_threshold float32 [0.5]
このツールのメリットは、onnx-simplifier で最適化が終わった状態のONNXのパラメータを直接書き換えできることです。例えば、入力解像度に応じた複数種類のモデルを最適化した状態で用意しておき、後処理の検出閾値のみをあとから書き換えて検出精度の変化をテストしたい時や、前節で挙げたように、そもそも Reshape の変更後の形状に -1 が指定されている場合に onnx-simplifier の最適化やバッチ処理化が失敗する時に強制的に指定したパラメータに書き換えできることです。PyTorch や TensorFlow のロジックを一切読む必要がありません。また、おそらくモデル構造を最適化するタスクに取り組み始めるとすぐに直面する課題なのですが、PyTorch や TensorFlow からONNXを出力、あるいは変換して出力するときに問題になることがあるのが、PyTorch や TensorFlow のモデルオプティマイザが必要のないモデル構造変更を行ったり、少しの最適化を勝手にしてしまうことがあり、想定通りの構造のONNXモデルを素直に生成できないことがあります。そういう場合にも onnx-simplifier で最適化後のONNXファイルのパラメータを直接書き換えできるところに大きなメリットがあります。また、opset間で互換性の有無が有る属性値の追加や削除ができます。
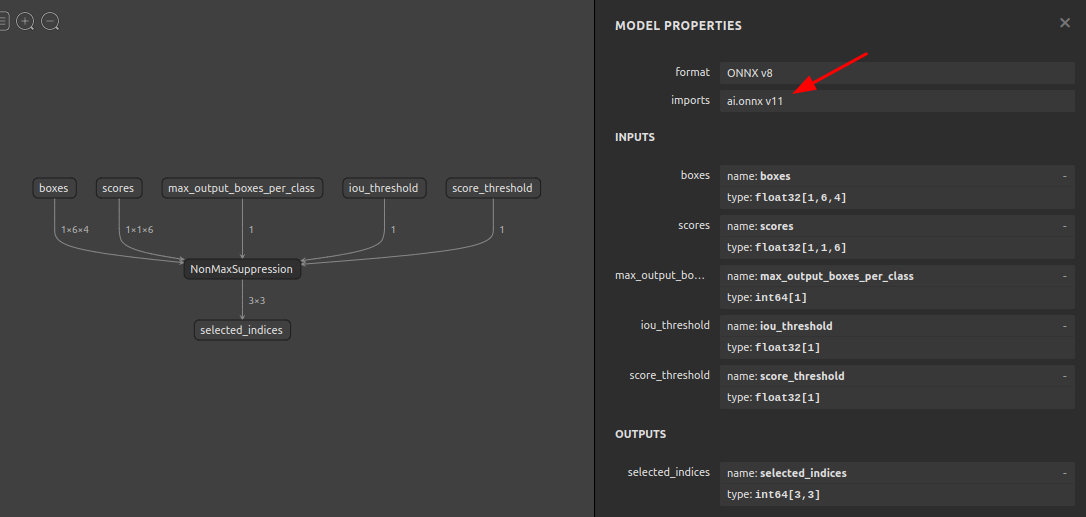
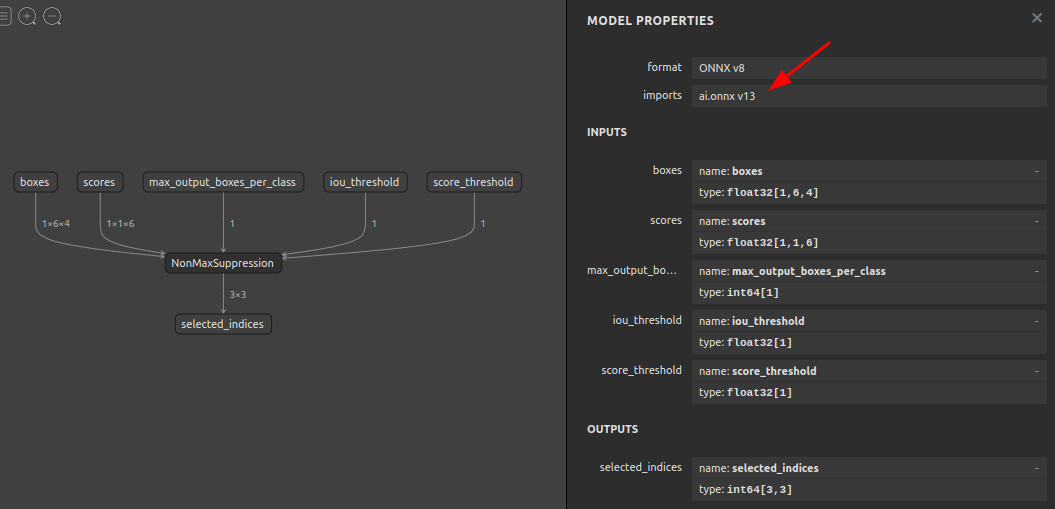
7-7. opsetの書き換え (soc4onnx)
opsetの数字を強制的に書き換えるツールです。運用上はほとんど使いどころが無いため大幅に説明を省略します。下図のイメージです。opsetの数字を書き換えるだけでNodeの構造をopsetに対応した構造に書き換えることまではしません。ユースケースとしては、コンポーネント化したONNXファイルを複数結合する際にopsetアンマッチによる結合エラーを回避する場合が考えられます。
|
1 2 3 4 |
soc4onnx \ --input_onnx_file_path NonMaxSuppression.onnx \ --output_onnx_file_path NonMaxSuppression_13.onnx \ --opset 13 |
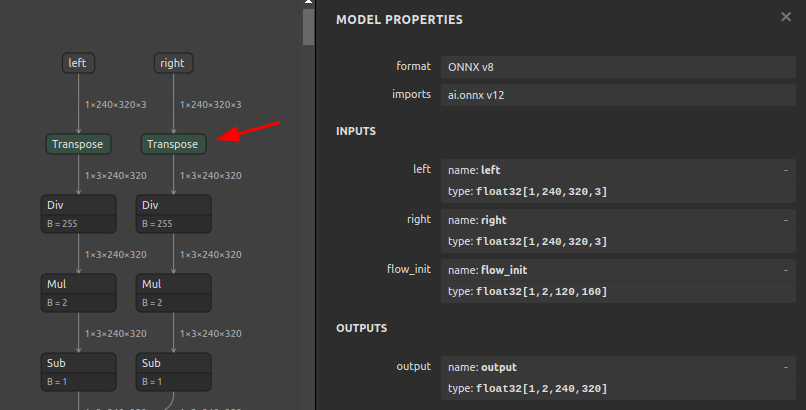
7-8. 入力OPのみのNCHW<->NHWC変換 および BGR<->RGB変換 (scc4onnx)
このツールもあまりユースケースが思い浮かびませんので説明を簡略化します。モデル全体を NCHW <-> NHWC 相互変換するのではなく、入力OPのみを NCHW <-> NHWC 相互変換します。また、BGR <-> RGB の変換用コンポーネントを入力OPの直後に外挿します。下図を見ていただくと雰囲気をご理解いただけると思います。
-
NCHW <-> NHWC 相互変換
ONNXの内部はNCHW形式で処理されるため、入力OPをNHWC形式に変更した場合は、入力OPの直後で NCHW形式に転置し直す必要があります。あくまで推論用プログラムをONNXとTensorFlowで共用したいときにモデルの入力形式をNHWC形式へ統一して運用する、あるいはその逆のNCHW形式へ統一して運用する、ぐらいの使いどころぐらいしか思い当たりません。
Before After 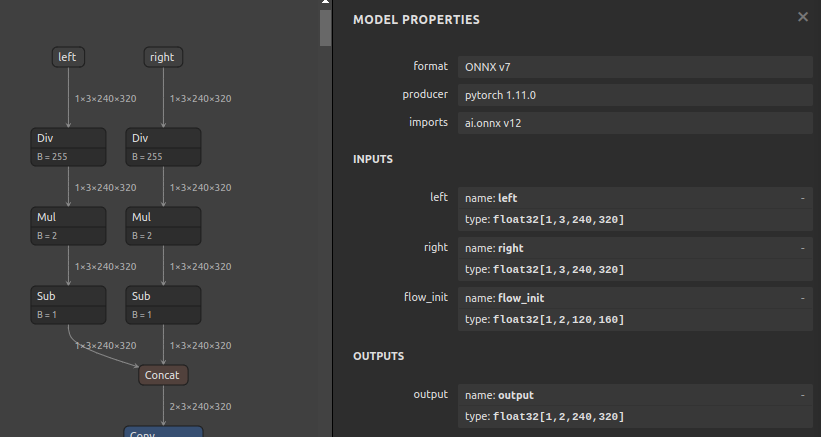
-
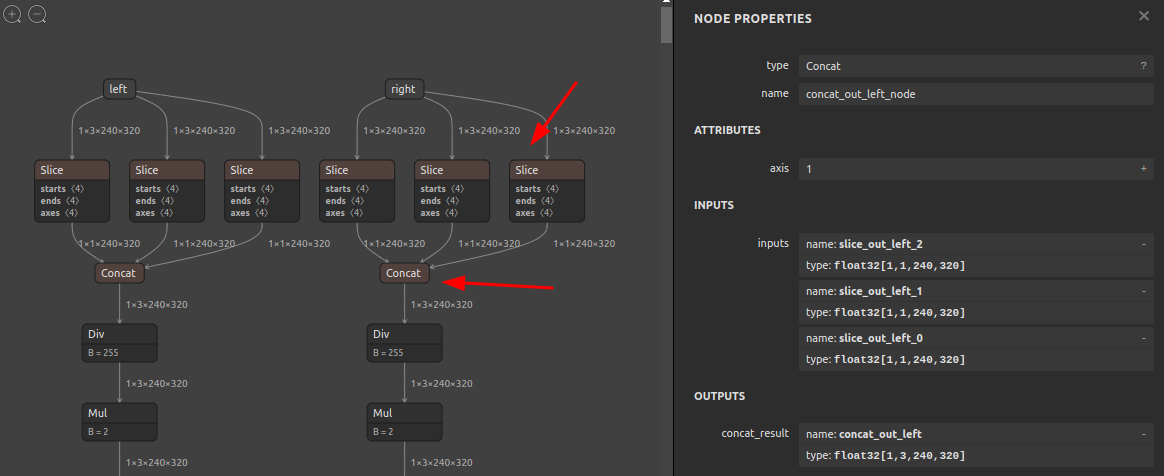
RGB <-> BGR 相互変換
入力OPの直後に3チャンネルをスライスして順番を入れ替える処理を外挿します。プログラムの前処理側でOpenCVを使用して定型的に実装することが多い、BGR -> RGB 変換 あるいはその逆の変換をモデルの入口に外挿してしまうイメージです。
Before After 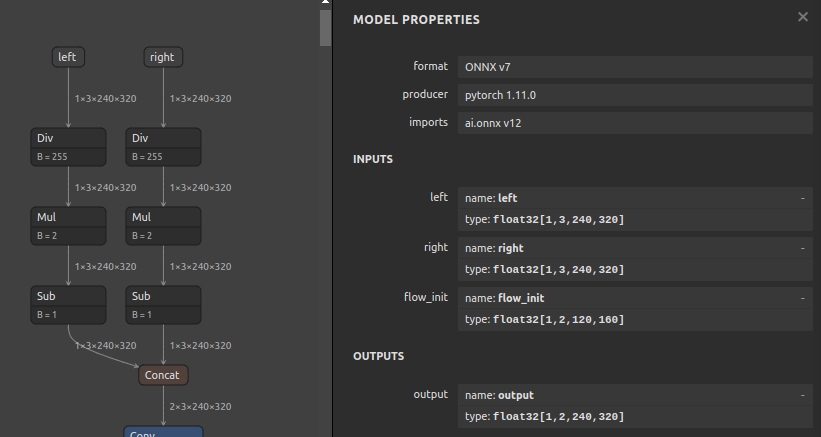
7-9. Nodeの追加 (sna4onnx)
ONNXの標準APIや onnx-graphsurgeon を使用したPythonコードで表現するときにはかなり手間が多く複雑な操作です。7-3. Nodeの削除 と逆向きの操作を行うという点以外はほぼ同じです。追加 という行為は複数のプリミティブな操作を組み合わせて実現する必要があり、コード量が若干多くなります。具体的には、
- モデルを指定のNodeの入出力位置で上下に分断してコンポーネント化する
- 追加対象のNodeをsog4onnxを使用して生成する
- 分断した上下部分のコンポーネントの終端と始端が2.で新規生成したNodeの入出力と同じ形状、同じ算術精度であることをチェックする
- 1.で分断した上下のコンポーネントと2.で生成したNodeを間に挟んで入出力変数で結合しなおす
- 全てのコンポーネントを再結合して生成しなおしたモデルの構造が破綻していないかチェックする
- モデルをONNXファイルとして再出力する
こちらのツールも、無理に使用しようとするとうまくNodeが追加できないパターンが多いですが、シンプルな構造のモデルであれば直感的に実施できます。実際に試してみます。sna4onnx というツールを使用します。
前節で使用した mnist-12.onnx を再び使用します。
意味の無い操作ですが、Conv の次に Mul を追加してみます。
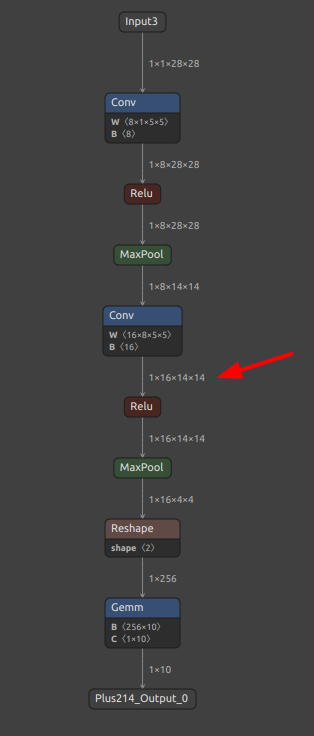
|
1 2 3 4 5 6 7 8 9 10 |
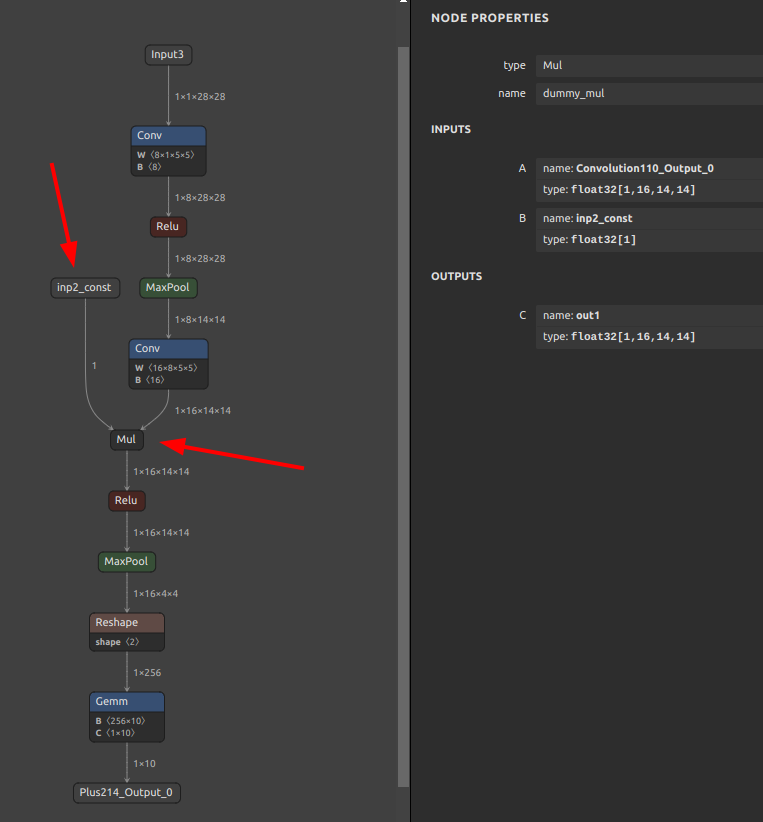
sna4onnx \ --input_onnx_file_path mnist-12.onnx \ --connection_src_op_output_name Convolution110 Convolution110_Output_0 dummy_mul inp1_var \ --connection_dest_op_input_name dummy_mul out1 ReLU114 Convolution110_Output_0 \ --add_op_type Mul \ --add_op_name dummy_mul \ --add_op_input_variables inp1_var float32 [1,16,14,14] \ --add_op_input_variables inp2_const float32 [1] \ --add_op_output_variables out1 float32 [1,16,14,14] \ --output_onnx_file_path mnist-12_add.onnx |
ONNXファイルが生成されました。
追加指定した Mul Node名 dummy_mul がモデルに追加され、Conv と Relu の間を仲介しているモデルが生成されました。ただ、sna4onnx は定数を自動生成することができませんので、入力 B 側は inp2_const という名前の変数のみ定義された状態となっています。別途定数を定義して inp2_const に紐付ける必要があります。少し手間ですね。ややこしいですが、ONNXは Constant (定数) であってもひとつの Node (オペレーション) として独立して定義が存在しています。従って、Constant を新規に生成した場合は snc4onnx を使用して個別に融合する必要があります。ONNX公式の Constant オペレーション仕様はこちらに記載があります。Constant-12 一例としてopset=12の Constant を取り上げています。
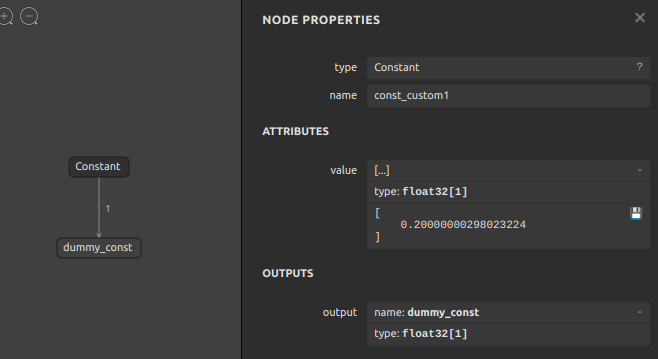
定数を定義した Constant Node を生成します。
|
1 2 3 4 5 6 |
sog4onnx \ --op_type Constant \ --opset 12 \ --op_name const_custom1 \ --output_variables dummy_const float32 [1] \ --attributes value float32 [0.2] |
生成されました。
では、前節で取り上げた snc4onnx を使用して Constant と Mul を結合してみます。
|
1 2 3 4 |
snc4onnx \ --input_onnx_file_paths Constant.onnx mnist-12_add.onnx \ --output_onnx_file_path mnist-12_merged.onnx \ --srcop_destop dummy_const inp2_const |
融合済みのONNXファイルが生成されました。Conv と Relu の間に Mul を外挿することに成功しました。
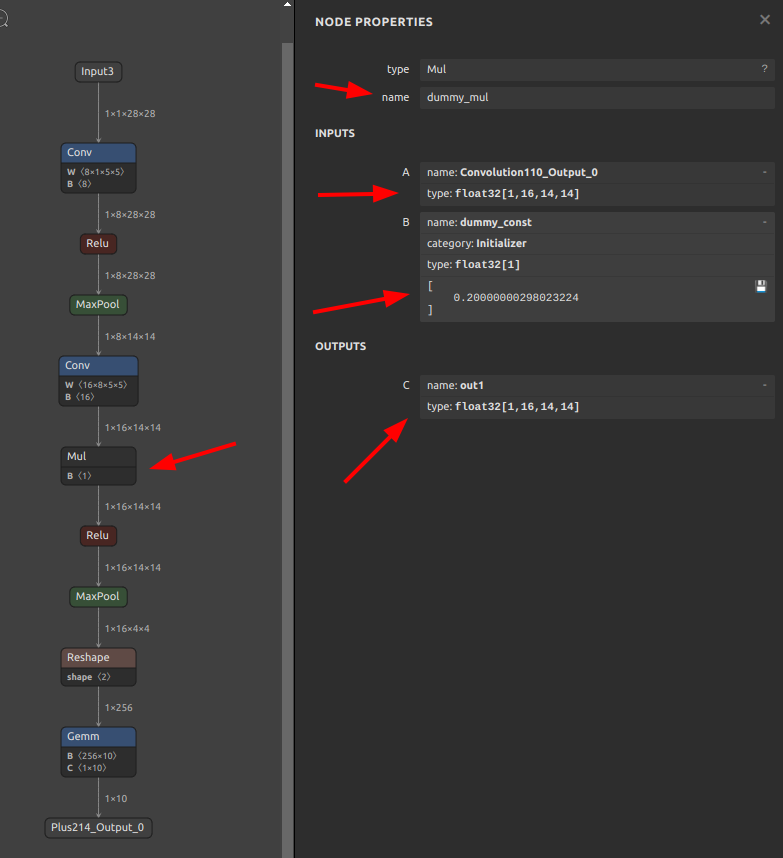
少し手間ですが、任意の位置にNodeを追加することができました。オペレーションを1個追加する程度ではあまりメリットを感じませんが、大量に追加する場合はシェルで一気に操作できるため便利なときがあります。大半のシチュエーションではPyTorch側のロジックを調整して再エクスポートしたほうが早いです。
7-10. 固定バッチサイズを可変バッチサイズに書き換え (sbi4onnx)
可変バッチのONNXファイルを生成する場合、PyTorch側で torch.onnx.export(...) を実行するときに下記のように dynamic_axes にバッチサイズを表す次元を指定して初期化する文字列を与えるだけで生成することができます。下記の場合はゼロ次元目に batch_size と文字列が付与された入力OPが生成されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
onnx_file = f"{MODEL}_HxW.onnx" x = torch.randn(1, 3, 180, 320).cuda() torch.onnx.export( self.model.module, args=(x), f=onnx_file, opset_version=11, input_names=['input'], output_names=['output'], dynamic_axes={ 'input' : {0: 'batch_size'}, 'output': {0: 'batch_size'}, } ) model_onnx = onnx.load(onnx_file) model_onnx = onnx.shape_inference.infer_shapes(model_onnx) onnx.save(model_onnx, onnx_file) |
では、あえてこの章でご紹介する 固定バッチサイズを可変バッチサイズに書き換え のテクニックが必要となるシチュエーションはどんなものがあるかというと、
- PyTorchモデルのソースコードが存在しない、あるいは提供されていない
- バッチサイズが固定されたONNXは提供されているが可変バッチのONNXが提供されていない
- リサーチャーが書いてくれたソースコードが複雑過ぎて読み込む作業の精神的ストレスが大きい
というパターンです。こういう状況はわりと多いです。従いまして、運用上は可変バッチのほうが扱いやすい場合を想定し、提供された固定バッチのONNXファイルを可変バッチのONNXファイルに書き換えます。
前節で使用した mnist-12.onnx を再び使用します。
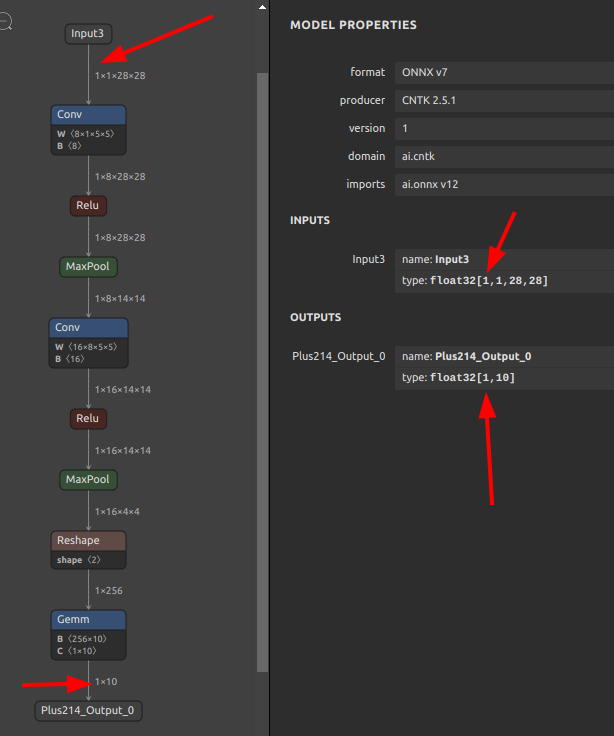
mnist-12.onnx はゼロ次元目のバッチサイズが 1 に固定されています。ここを可変バッチの N に書き換えてみます。
|
1 2 3 4 |
sbi4onnx \ --input_onnx_file_path mnist-12.onnx \ --output_onnx_file_path mnist-12_Nbatch.onnx \ --initialization_character_string N |
ONNXファイルが生成されました。ゼロ次元目のバッチサイズが指定した文字列 N で更新されています。
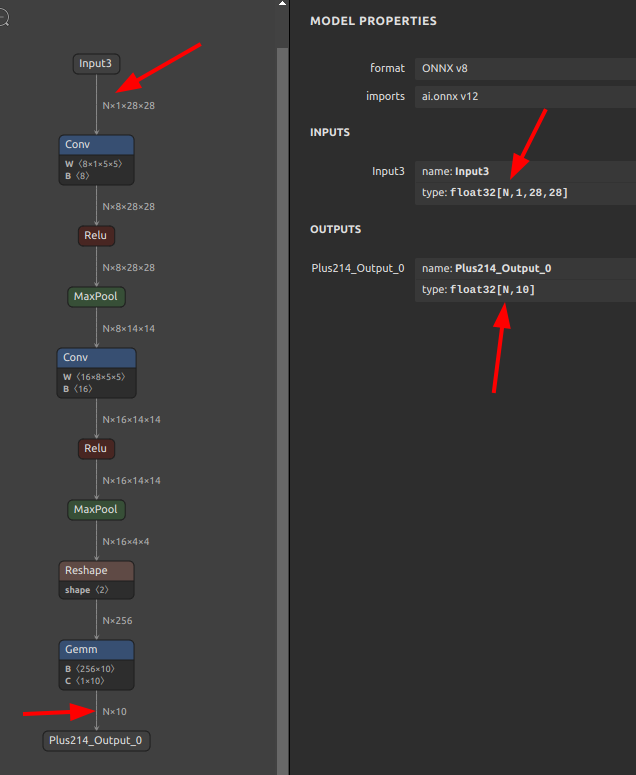
注意点として、このツールはゼロ次元目を数値から文字列へ強制的に書き換える動作のみを行います。したがいまして、ゼロ次元目を含む形状変更を伴う Reshape の形状変更、が含まれている場合や、バッチサイズそのものの意味を表現できないNodeが含まれている場合は書き換え動作が失敗します。シンプルに機械的にゼロ次元目を書き換える動作のみに対応しています。とはいえ書き換える方法が無いわけではなく、モデルのバッチサイズを書き換えたい場合は 7-2. モデルの分離 (sne4onnx) を使用して該当部分のNodeを切り離したうえで、切り離したコンポーネント個々の単位でバッチサイズを初期化し、バッチサイズ初期化後に再び 7-1. モデルの融合 (snc4onnx) を使用して再結合すれば問題ありません。既出のツールを組み合わせて作業手順を組み立てる発想の転換次第でほとんどの問題は回避可能です。このブログのテクニックを総動員して生成したモデルがこちらにあります。yolact_edge_onnx_tensorrt_myriad
7-11. Node名の書き換え (sor4onnx)
入力OP、出力OP、中間Nodeの名称を書き換えることができます。ユースケースは、PyTorchから出力されたONNXのNode名が冗長なときに、運用ルールに則した分かりやすいネーミングに一括で統一する場合や、7-1. モデルの融合 (snc4onnx) を使用して複数のコンポーネントを結合する際、コンポーネント間でNode名の重複がある場合に、融合後のモデル全体で一意な名前になるようにあらかじめ名前を更新しておくような状況で良く利用します。ONNXのNode名はモデル全体で必ず一意になる必要があります。
では、再び mnist-12.onnx を使用します。
-
モデル全体のNodeを前方一致検索し
ConvolutionをCONVに書き換え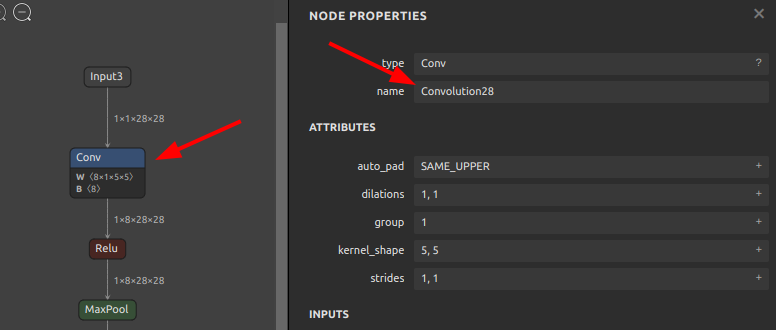 123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename1.onnx \--old_new "Convolution" "CONV" \--mode full \--search_mode prefix_match
123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename1.onnx \--old_new "Convolution" "CONV" \--mode full \--search_mode prefix_match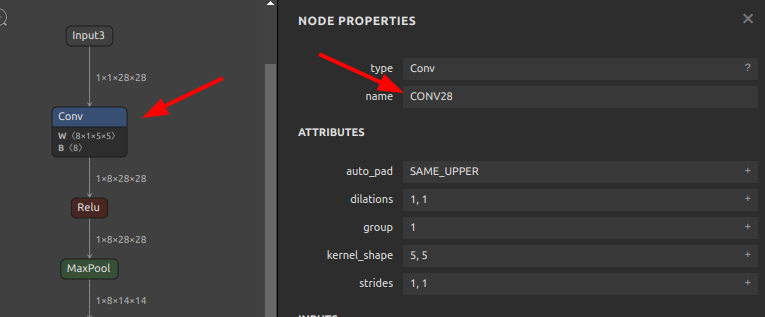
-
入力OPのみを前方一致検索し
Input3をinputに書き換え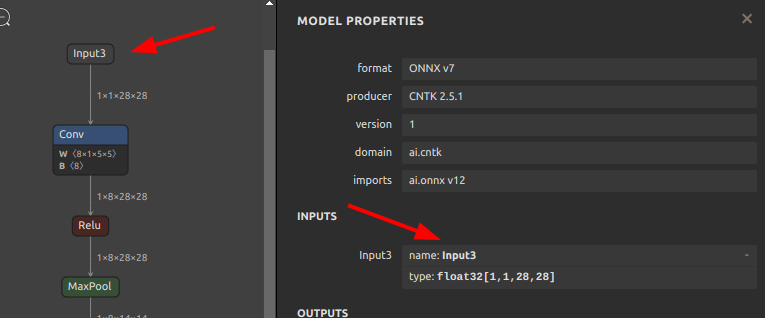 123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename2.onnx \--old_new "Input3" "input" \--mode inputs \--search_mode prefix_match
123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename2.onnx \--old_new "Input3" "input" \--mode inputs \--search_mode prefix_match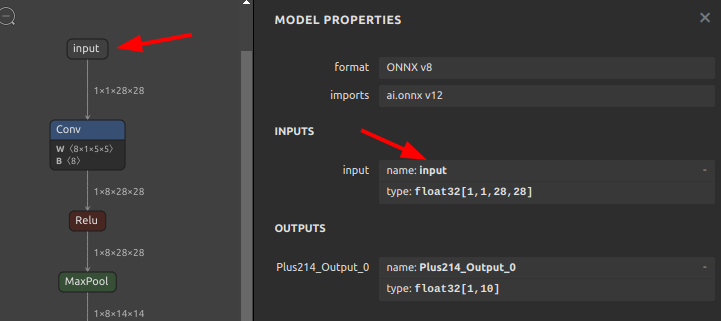
-
出力OPのみを前方一致検索し
Plus214_Output_0をoutputに書き換え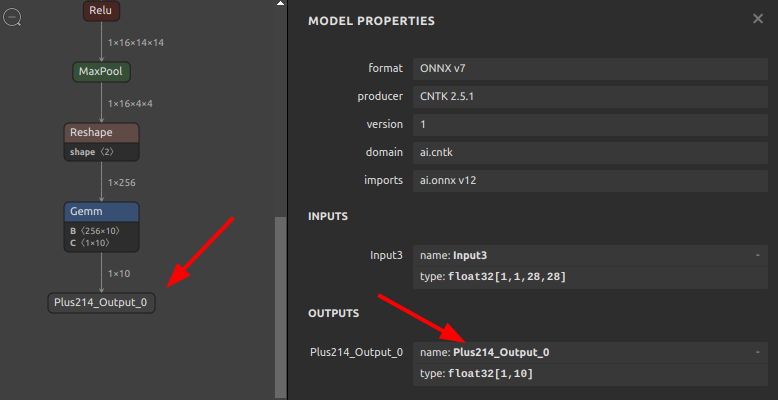 123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename3.onnx \--old_new "Plus214_Output_0" "output" \--mode outputs \--search_mode prefix_match
123456sor4onnx \--input_onnx_file_path mnist-12.onnx \--output_onnx_file_path mnist-12_rename3.onnx \--old_new "Plus214_Output_0" "output" \--mode outputs \--search_mode prefix_match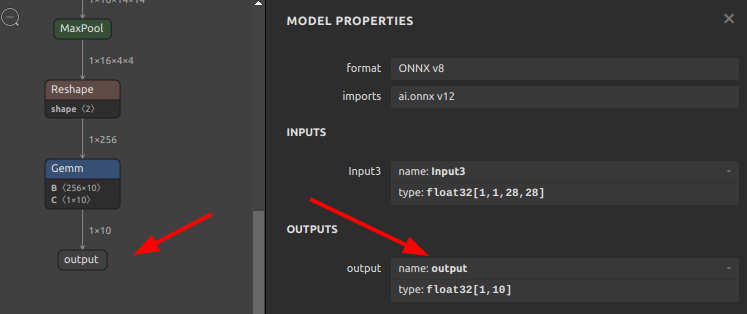
名前の置換範囲や検索アルゴリズムには次のものが選択可能です。モデル全体、入力OPのみ、出力OPのみ、完全一致検索、部分一致検索、前方一致検索、後方一致検索。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-m {full,inputs,outputs}, \ --mode {full,inputs,outputs} Specifies the type of node to be replaced. full or inputs or outputs. full: Rename all nodes. inputs: Rename only the input node. outputs: Rename only the output node. Default: full -sm {exact_match,partial_match,prefix_match,suffix_match}, \ --search_mode {exact_match,partial_match,prefix_match,suffix_match} OP name search mode. exact_match or partial_match or prefix_match or suffix_match. exact_match: Exact match search for OP name. partial_match: Partial match search for OP name. prefix_match: Prefix match search for OP name. suffix_match: Suffix match search for OP name. Default: exact_match |
モデル構造を見直すときはかなり使用頻度が高くなるツールです。モデル利用者側から見た構造の視認性向上にも役立ちます。
7-12. モデルに出力OPを追加 (soa4onnx)
モデルの任意の位置のNodeから出力OPを追加生成します。すでにツール群 simple-onnx-processing-tools を活用している海外のエンジニアからのリクエストを受けて作成しました。 soa4onnx 各ノードの出力値をデバッグする場合や複数のモデルを融合するための接合点を生成するユースケースに使用します。
再び mnist-12.onnx を使用します。
最初の Relu から出力OPを生成してみます。加工前のモデルの出力は Plus214_Output_0 のひとつのみです。また、Relu の出力変数名は ReLU32_Output_0 です。
-
モデルの全体構造
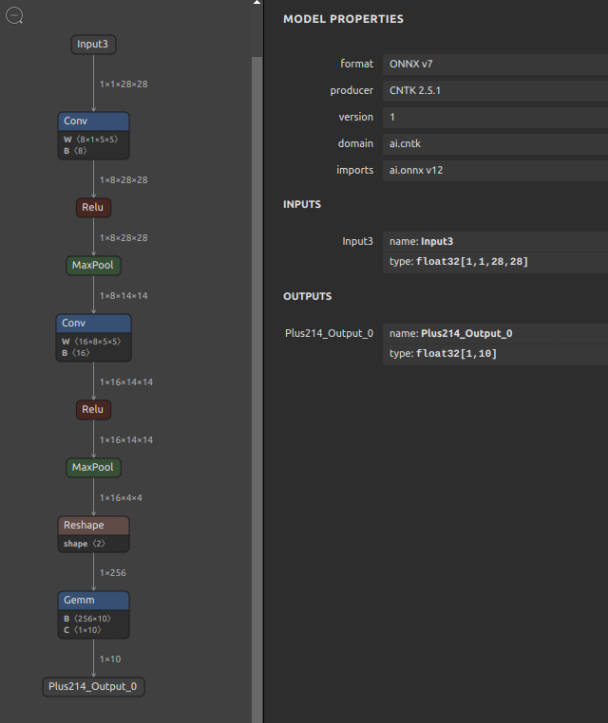
-
最初の
ReluNodeの情報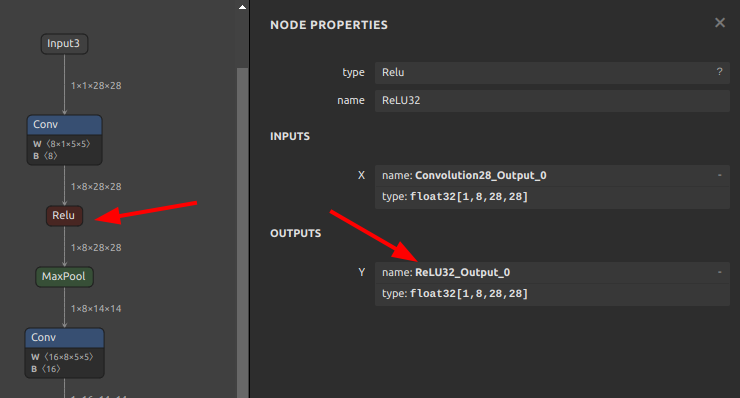
Relu の出力変数名 ReLU32_Output_0 をモデルへ追加するように指示します。
|
1 2 3 4 |
soa4onnx \ --input_onnx_file_path mnist-12.onnx \ --output_op_names "ReLU32_Output_0" \ --output_onnx_file_path mnist-12_output_added.onnx |
ONNXファイルが生成されました。ReLU32 Nodeの出力 ReLU32_Output_0 がモデルの出力として追加され、モデル全体の出力が2つに増えました。
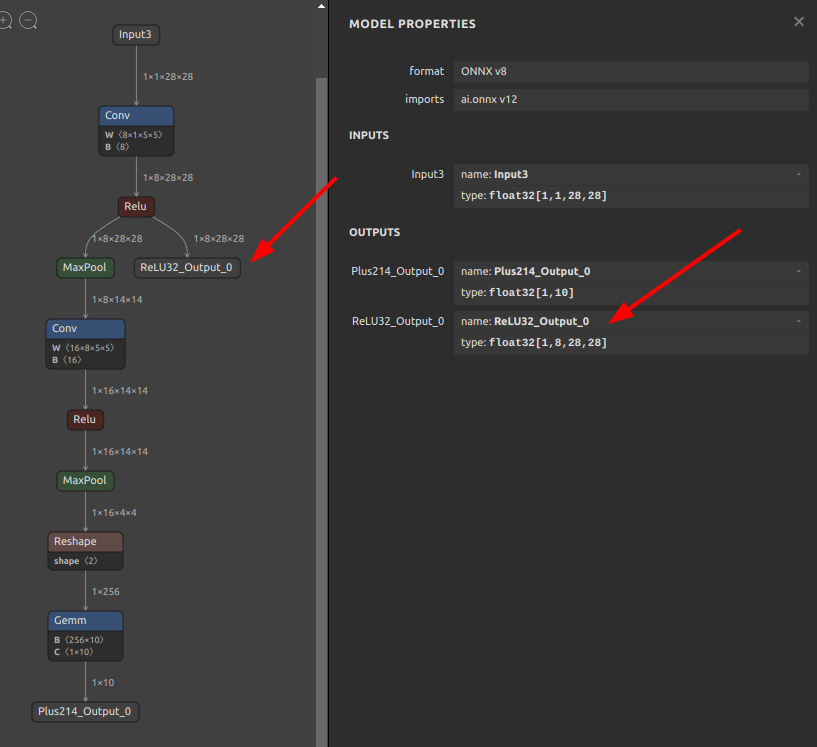
ちょっとしたモデル構造の改変程度ではあまり利用する機会がありませんが、複数のモデルを融合するときに接合点を生成するときに役立つときがあります。
soa4onnx の README はこちらです
7-13. モデルの出力OPを削除 (sod4onnx)
それほど多くはありませんが、PyTorchの公式論文実装から出力したONNXの出力OPに使用されないものが複数含まれていることがあります。無駄な出力を含めたままにしていると、ハードウェアアクセラレータとHostPC間での無駄なデータ転送コストが発生してレイテンシを悪化させることにつながることがあります。特にUSBを経由して使用するハードウェアアクセラレータなどを使用する場合はできる限りHostとやりとりする情報の転送量を抑えるのがレイテンシ低減に効果的です。なお、PyTorchの論文実装をカスタムして出力OPを削除する場合は不用です。
今回は複数出力OPを備えたモデルを使用してテストする必要がありますので、こちらの Robust Video Matting (RVM) モデルを使用します。
入力ひとつに対し、出力が fgr pha r1o r2o r3o r4o の6つあるモデルです。仮にこの出力のうち pha だけが必要とした場合のユースケースを想定します。
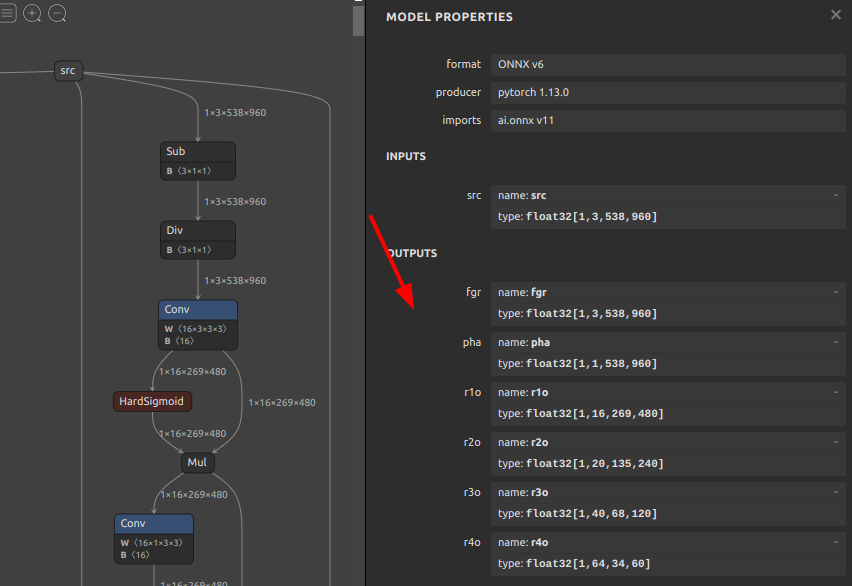
では、pha 以外の出力を全て削除してみます。
|
1 2 3 4 |
sod4onnx \ --input_onnx_file_path rvm_mobilenetv3_538x960.onnx \ --output_op_names "fgr" "r1o" "r2o" "r3o" "r4o" \ --output_onnx_file_path rvm_mobilenetv3_538x960_output_del.onnx |
ONNXファイルが生成されました。
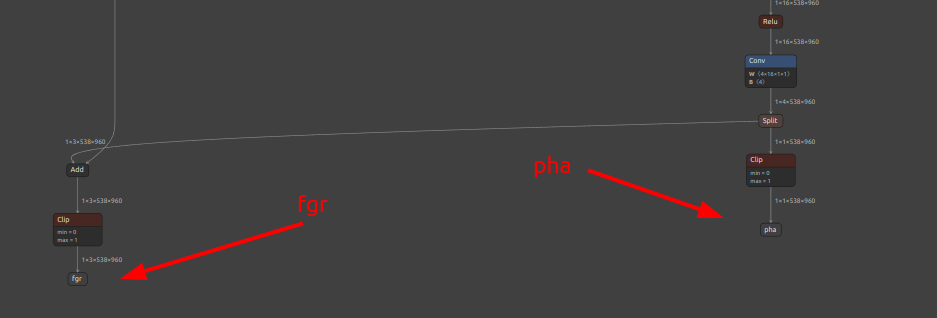
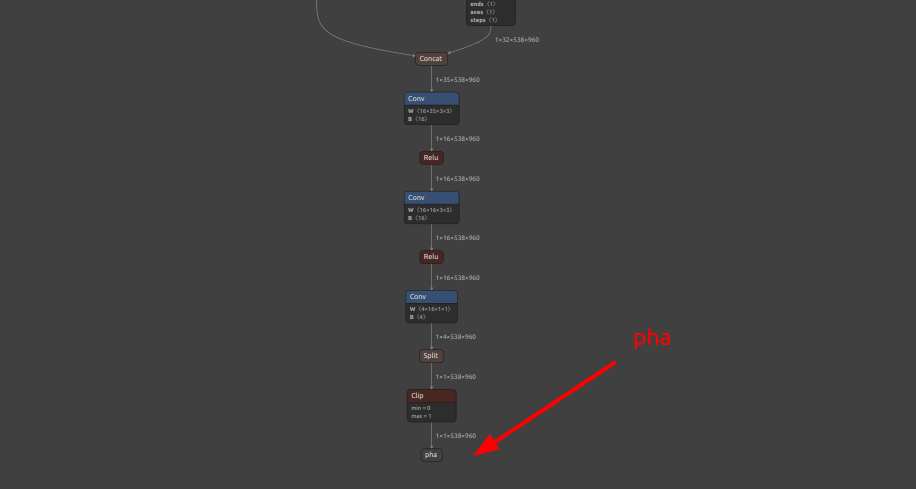
削除する、ということ自体は当たり前のようにできるのですが、注目していただきたい点は別の部分にあります。下図の出力OP削除前と出力OP削除後を交互にご覧ください。出力OP削除前に fgr に接続されていた各種OP (Add と Clip) が fgr 削除後に一掃され、最終出力に不必要なモデルのフローが全て自動的に削除されました。つまり、無駄な出力OPを全て削除することで通過しなくてもよい演算ルートを全て一掃する効果があるという点です。今回テストに使用したモデル rvm_mobilenetv3_538x960.onnx は削除された最終出力OPの手前に接続されているNodeが2つしかありませんでしたので推論速度向上に対する効果は限定的ですが、より一層複雑なモデルに対して同様の削除操作を行った場合、不必要な演算を大幅にカットできることがあります。PyTorchのロジックを目視で読み込んで手作業で最適化しなくてもツールが自動的に最適化してくれます。
-
出力OP削除前のモデルの最終出力近辺の様子
-
出力OP削除後のモデルの最終出力近辺の様子
7-14. モデルの中間Nodeの形状推定操作のみ実行 (ssi4onnx)
モデルのチューニングをするにあたって、モデルの中間Nodeの形状推定をすることのメリットは 基礎編 の 6-1-2. オペレーションの形状推定と定数変換と埋め込み でご紹介しました。しかしながら、状況によっては onnx-simplifier を使用してモデル構造の最適化はしたくないが各Nodeの入出力の形状のみ事前に推定しておきたいシチュエーションがあります。例えば、最適化までを行ってしまうとONNX以外の推論フレームワークで問題が発生する場合や、最適化前の形状を正しく把握してどのNode部分を最適化対象とするかを分析したいときなどです。onnx-smiplifier を使用すると自動的に形状推定を行いつつモデル構造を最適化してしまいます。
したがって、そういうユースケースに対応するため、このツール ssi4onnx はモデル構造の最適化を一切行わず、全Nodeの形状推定処理のみを実行します。
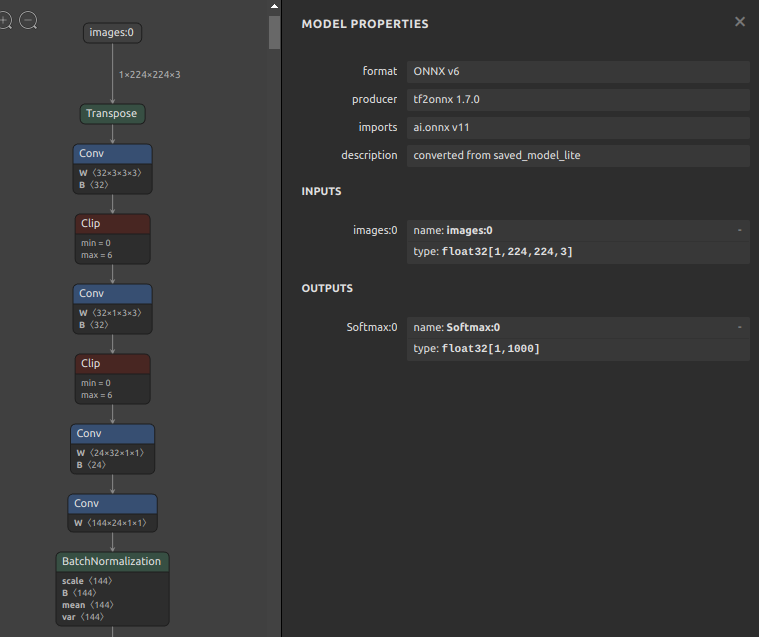
今回はこちらのモデル efficientnet-lite4-11.onnx を使用します。モデルの構造は下図のとおりです。onnx-simplifier で未最適化の状態です。
比較のためにまずは onnx-simplifier で形状推定とモデル構造の最適化の両方を実行してみます。
|
1 |
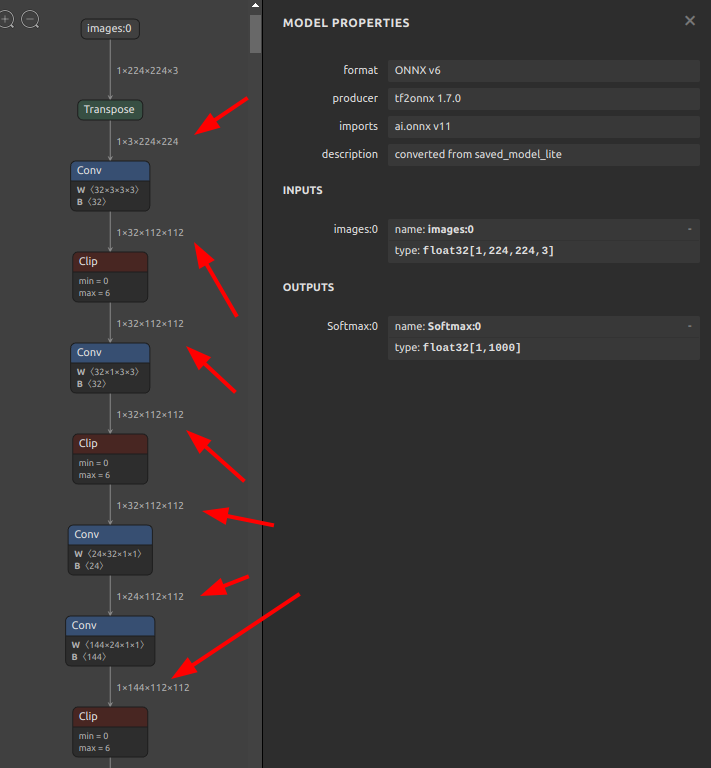
onnxsim efficientnet-lite4-11.onnx efficientnet-lite4-11_onnxsim.onnx |
モデルの形状推定と構造の最適化後の様子です。4つ目の Conv の次にあった BatchNormalization が Conv に取り込まれて消滅するのと同時に各Nodeの入出力情報が書き込まれ、モデル構造の視認性が向上しました。
次に ssi4onnx を使用して形状推定のみ実行してみます。
|
1 2 3 |
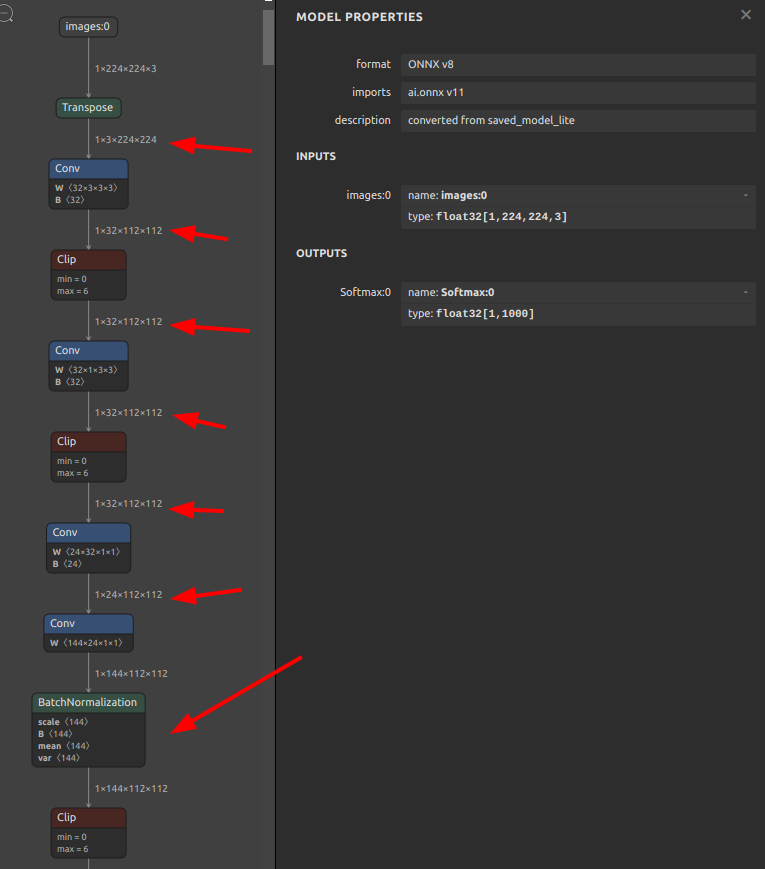
ssi4onnx \ --input_onnx_file_path efficientnet-lite4-11.onnx \ --output_onnx_file_path efficientnet-lite4-11_inf_only.onnx |
モデル構造の最適化が行われていないため BatchNormalization が Conv に取り込まれることなくそのまま残っていますが、各Nodeの入出力情報が書き込まれ、モデル構造の視認性が向上しました。
7-15. ONNXの推論速度の簡易的なベンチマーク (sit4onnx)
基礎編 4. モデル生成の基礎 [PyTorch -> ONNX] で使用方法をご紹介しましたので応用編では説明を省略します。
7-16. ONNXのJSON変換 (onnx2json)
基礎編 5-1. ONNXモデルの構造 で使用方法や生成されたJSONファイルの読み方、IDEを使用した書き換え方法などをご紹介しましたので、応用編では説明を省略します。
7-17. JSONのONNX変換 (json2onnx)
基礎編 5-1. ONNXモデルの構造 で onnx2json を使用して生成したJSONファイルに対して自由な編集を加えたモデル構造を再びONNXファイルへ逆変換するためのツールです。これまでの節でご紹介したツール群によるモデル加工の代わりに、IDEを使用してモデルの構造を直接手で書き換えてからONNXファイルへ戻すほうが早いシチュエーションが数多く存在します。たとえば、モデル内に繰り返し登場する類似の処理部分を一括で置換して書き換えたい場合などです。IDEの検索と置換の機能は高機能ですので、IDEの正規表現の置換機能などを駆使してテキストベースで一括変更すると楽な時があります。
ここでは 基礎編 5-1. ONNXモデルの構造 の説明をベースにしてモデルをIDEで書き換えたうえでONNXファイルへ戻すテクニックをご紹介します。
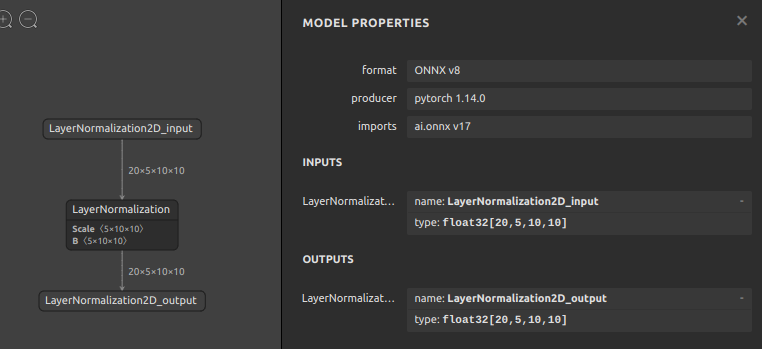
加工対象のサンプルとするモデルは 基礎編 5-1. ONNXモデルの構造 で生成した opset=17 の LayerNormalization2D_17.onnx です。事例はシンプルな方が分かりやすいと思いますので、定数のBase64エンコードが不要な属性値 epsilon を 1e-05 (0.000009999999747378752) から 1e-01 (0.10000000149011612) へ単純に書き換えます。
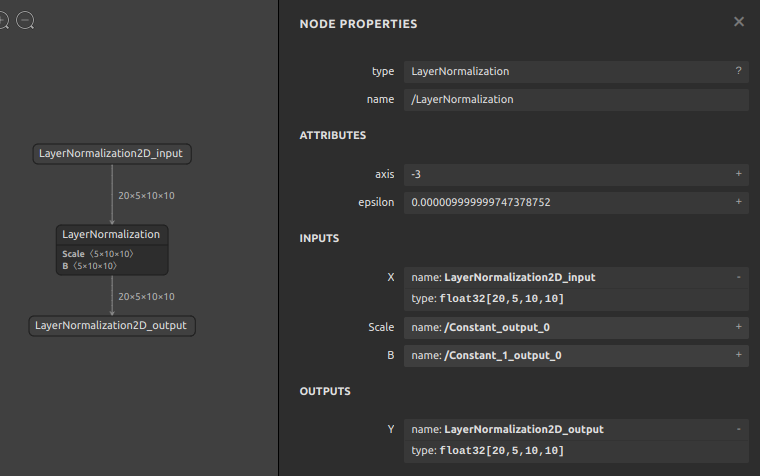
まずはONNXファイルをJSONに変換します。
|
1 |
onnx2json -if LayerNormalization2D_17.onnx -oj LayerNormalization2D_17.json |
JSONファイルをVSCodeなどのIDEで開きます。編集箇所は "f": 1e-05, の部分です。編集したらJSONを上書き保存します。
- 編集前
123456789101112131415161718192021222324252627282930313233343536373839{"irVersion": "8","producerName": "pytorch","producerVersion": "1.14.0","graph": {"node": [{"input": ["LayerNormalization2D_input","/Constant_output_0","/Constant_1_output_0"],"output": ["LayerNormalization2D_output"],"name": "/LayerNormalization","opType": "LayerNormalization","attribute": [{"name": "axis","i": "-3","type": "INT"},{"name": "epsilon","f": 1e-05,"type": "FLOAT"}]}],"name": "torch_jit","initializer": [{"dims": ["5","10","10"],
- 編集後
123456789101112131415161718192021222324252627282930313233343536373839{"irVersion": "8","producerName": "pytorch","producerVersion": "1.14.0","graph": {"node": [{"input": ["LayerNormalization2D_input","/Constant_output_0","/Constant_1_output_0"],"output": ["LayerNormalization2D_output"],"name": "/LayerNormalization","opType": "LayerNormalization","attribute": [{"name": "axis","i": "-3","type": "INT"},{"name": "epsilon","f": 1e-01,"type": "FLOAT"}]}],"name": "torch_jit","initializer": [{"dims": ["5","10","10"],
次に、JSONファイルをONNXファイルへ逆変換します。
|
1 |
json2onnx -ij LayerNormalization2D_17.json -of LayerNormalization2D_17_eps.onnx |
JSONファイルからONNXファイルが生成されました。ONNXファイルをNetronで表示すると、属性値 epsilon の値が 1e-01 (0.10000000149011612) へ更新されていることが確認できます。
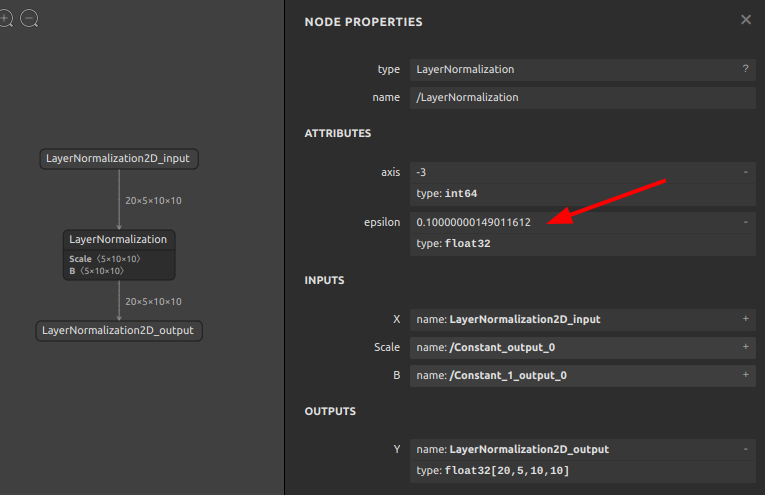
このレベルの簡易的な修正であれば、前節までのツールを使用してスクリプトを実行するよりも、JSON化してテキストベースで編集を加えたうえでONNXファイルを再生成したほうが直感的で手っ取り早いことが多いです。使い慣れたIDEを使用してONNXを一括書き換えできます。
7-18. 定数値のBase64エンコード/デコード (sed4onnx)
基礎編 5-1. ONNXモデルの構造 で扱い方をご紹介しましたので応用編では説明を省略します。
7-19. 簡易的な構造分析 (ssc4onnx)
基礎編 6-1-3. 使用するうえでのテクニック で扱い方をご紹介しましたので応用編では説明を省略します。
7-20. モデルの入出力形状名の書き換え (sio4onnx)
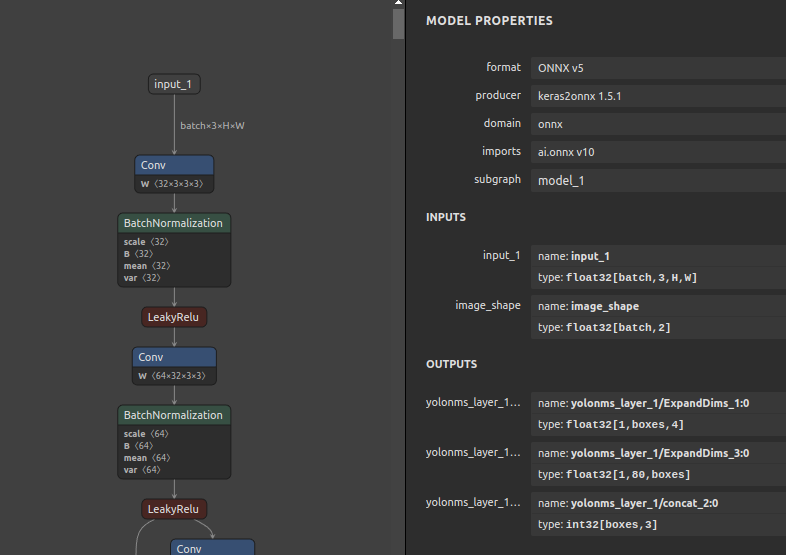
ONNXのモデルは未定義の次元 (unk__*) を受け入れます。例えば下記のような事例です。unk__* の部分はどのような形状でも受け入れることを表します。PyTorchからONNXをエクスポートする時に torch.onnx.export(...) で dynamic_axes に名前を指定しなかった場合などです。PyTorchの公式ドキュメントに記載があります。torch.onnx.export 下記の例では、yolonms_layer_1/* という名前の出力OPのゼロ次元目を未定義の次元に指定していますが、表示名を指定していませんので unk__* という少し長めで直感的ではない未定義の次元名が自動で付与されます。あるいは、onnx-simplifier を使用して形状推定とモデル構造の最適化を行っていない状態のときに形状未定という意味で unk__* が割り当てられることがあります。ONNXを推論で使用するうえでは特に問題は発生しませんが直感的なネーミングではなく、そして少し冗長です。このネーミング部分を sio4onnx で書き換えます。
|
1 2 3 4 5 |
dynamic_axes={ "yolonms_layer_1/ExpandDims_1:0": [0,1], "yolonms_layer_1/ExpandDims_1:3": [0,1,2], "yolonms_layer_1/concat_2:0": [0,1], } |
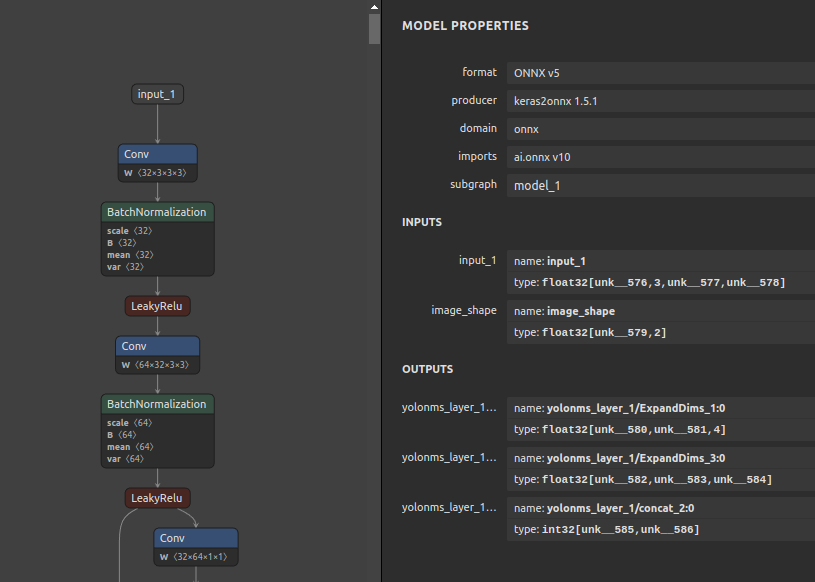
ネーミングを書き換えます。unk__* の部分を batch や H や W や boxes などに書き換えるコマンドは下記のとおりです。面倒ですが、全ての入出力OP名を列挙する必要があります。前節のJSON変換を使用してIDEで書き換えても大して作業コストに変わりはありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
sio4onnx \ --input_onnx_file_path yolov3-10.onnx \ --output_onnx_file_path yolov3-10_upd.onnx \ --input_names "input_1" \ --input_names "image_shape" \ --input_shapes "batch" 3 "H" "W" \ --input_shapes "batch" 2 \ --output_names "yolonms_layer_1/ExpandDims_1:0" \ --output_names "yolonms_layer_1/ExpandDims_3:0" \ --output_names "yolonms_layer_1/concat_2:0" \ --output_shapes 1 "boxes" 4 \ --output_shapes 1 "classes" "boxes" \ --output_shapes "boxes" 3 |
7-21. Node間コネクションの切り替え (svs4onnx)
7-9. Nodeの追加 (sna4onnx) および 7-3. Nodeの削除 (snd4onnx) では、任意のNode間に新たなNodeを外装したり、任意のNodeを削除する方法をご紹介しました。しかし同時に文中でも触れているように、外挿あるいは削除するNode位置の前後の入出力形状と演算精度が必ず一致していないとエラーになるということにも触れました。7-9. Nodeの追加 (sna4onnx) と 7-3. Nodeの削除 (snd4onnx) は内部処理が若干複雑な手番を踏んでいるがゆえに手軽に使える反面柔軟性に乏しい面がありました。そこでこのツール svs4onnx は少しだけ発想を変えて、コネクション間に新たなNodeを追加したり、コネクション間に存在するNodeを直接削除するのではなく、下記の順序で慎重に、そして正確にコネクションを接続替えする操作を数段階踏むことでNodeを外挿したり対象のNodeを削除する操作を表現するために作成しました。具体的な動作イメージは下記の通りです。
- 入力ノードの出力変数に新規ノードを接合する
- 新規ノードの出力変数をモデルの任意の入力変数へ接合する
- 2.で新規Nodeの出力変数で入力変数が上書きされたNodeより手前の任意の数のNode(モデルの全体フローから外れたコンポーネント)をどのコネクションにも接続されていない離れ小島の状態にする
- モデルの整合性をチェックし、全体構造から分離して離れ小島になっているコンポーネント部分をクリーニング(削除)する
わけのわからないことをゴチャゴチャと書きましたが、要は下図のとおりコネクションの接続替えをすることができる。ということです。この操作ができることで、7-9. Nodeの追加 (sna4onnx) および 7-3. Nodeの削除 (snd4onnx) の操作を表現できます。
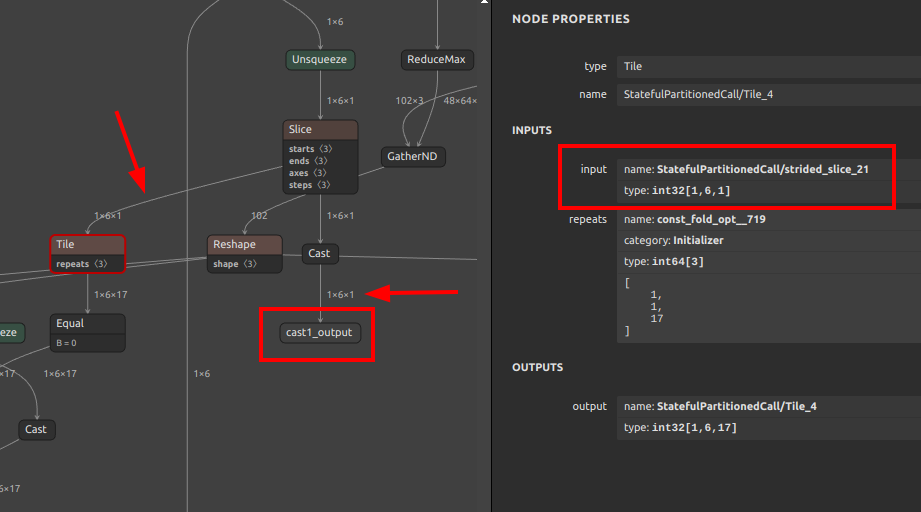
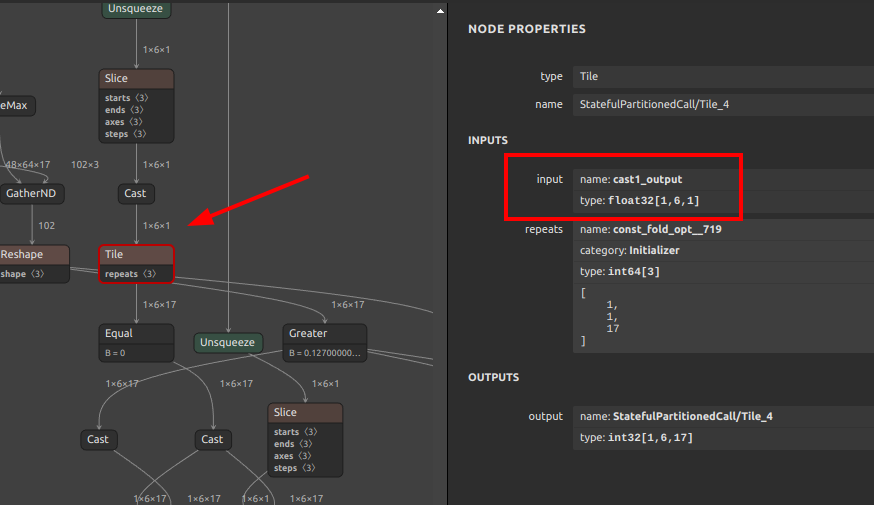
Nodeの追加やNodeの削除というややこしい考え方は置いておいて、単純にこのツールでコネクションの接合先を変更するコマンドは下記の通りです。Cast Nodeの出力変数 cast1_output を Tile の入力変数 StatefulPartitionedCall/strided_slice_21 に接合するように指示を出しています。From から To へ接続せよ。というだけの指示です。このタイミングで、もともと接続されていたコネクションは自動的に消失します。
|
1 2 3 4 5 |
svs4onnx \ --input_onnx_file_path movenet_multipose_lightning_192x256_nopost_tmp1.onnx \ --from_output_variable_name "cast1_output" \ --to_input_variable_name "StatefulPartitionedCall/strided_slice_21" \ --output_onnx_file_path movenet_multipose_lightning_192x256_nopost_tmp2.onnx |
7-22. ONNX(NCHW)形式からTensorFlow(NHWC)形式への自動コンバート (onnx2tf)
このツールだけは他のツールのようにモデルの構造を書き換える手段を提供するものではなく、シンプルにONNXをTensorFlowフォーマットへ変換するツールです。数年前からONNXの公式ツールとして onnx-tensorflow というものが提供されていたのですが、ツールを利用する上で大きな問題を抱えています。
- NCHWをシミュレートするように無理やり変換するため、全ての
Convの前後に無駄なTransposeを大量に外装し、変換後のモデルの推論パフォーマンスが極端に悪化する - ロジックの構造が TensorFlow v1.x を前提としたとてもレガシーな作りになっている
- 未定義の次元を含むモデルを変換できない
- 内部の作りが複雑なことに加えて依存パッケージが多く正常に動作しないパターンが多い
- コントリビュータが居ない
1.と2.の問題は大きな問題ではありますがOSSとして公開された当初からの仕様ですので、基本的な処理思想含めて大掛かりにリファクタリングをする必要があることを考えるとなんとか目をつぶることが出来ますが、5.はOSSとして致命的です。仮にプルリクエストを頑張って発行したとしてもレビューアが不在です。そして、内部のロジックの作りが複雑過ぎるためデバッグがとても困難でした。コントリビュータが36人も居て約5年?も継続的にメンテナンスされてきていたためとても残念ではありますが、メンテナ不在の時点で工数を掛ける気があまり湧きませんでした。
ということで、1.から5.の問題を全て解決すべく、ひとりでフルスクラッチしたツールがこちらのツール onnx2tf です。onnx-tensorflow が対応していない一部のオペレーションの変換にも追加で対応し、onnx-tensorflow で変換したモデルよりも 20% ほど高速なモデルを生成できます。ただし、RNN系とFFT系のオペレーションだけは TensorFlow v2.x 系での実装難易度が高すぎて今のところはうまく動作する状態で変換動作を実装することができていません。RNN LSTM GRU などです。もし気が向いた方がいらっしゃいましたら、是非プルリクエストをお送り下さい。
ちなみに、類似のツールとして onnx2tflite がありますが、現時点では以下の点で仕様の充足度が足りないと考えています。分かる範囲で記載しますので今後改善されていく可能性があるものも含みます。
-
tf.kerasを多用しているため、saved_modelを出力するときに頻繁にエラーが発生する -
モデルの入力にひとつのテンソルしか許容しない (複数入力を許容しない)
-
画像を入力にとるモデルしか考慮されていない
-
量子化時のノーマライゼーションの実装に画像入力しか考慮されていない
-
per-channelの量子化しか考慮されておらずper-tensorの量子化ができないためハードウェアアクセラレータへの配慮が不足している -
TPU や Myriad やその他のハードウェアアクセラレータに対するオペレーション置換のワークアラウンドが考慮されていない
-
ONNXからTFLiteへの変換しか考慮されておらず、その他のフレームワークへ転用することを考慮していない
-
多次元の転置が考慮されていない
-
汎用的な動作を定義する実装が無く、対応できるモデルの種類がとても少ない
-
TransposeConvの変換に問題がある -
Sliceの変換に問題がある -
INT8量子化されたONNXモデルを変換することができない
-
実装が不足しているオペレーションが多い (例えばNMSなど)
-
NHWC形式の入力を持つONNXモデルを変換できない
-
変換エラーが発生するパターンを回避するための手段としては、プログラムを独自改造する方法しか無い
-
パッケージ化されていない
-
CLIインタフェースが無い
7-23. 名前が未定義のNodeに対する自動ネーミング (sng4onnx)
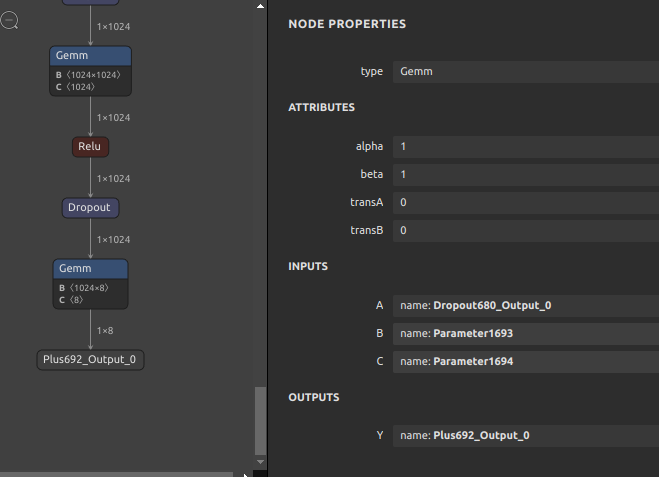
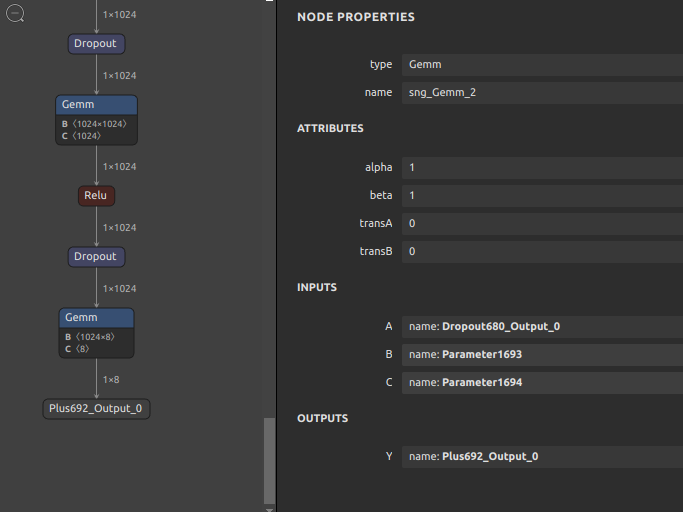
opset=8 より古いONNXのモデルにはNodeに名前が付与されていないことがあります。そういったモデルは onnx-simplifier やこのブログでご紹介したツール群でのモデル最適化に失敗することがあります。したがって、名前が付与されていないNodeに対して自動的に一意な名前を生成して書き込むツールを作成しました。そもそもONNXのモデルが古すぎることが問題であって、現時点ではあまり問題とはならないシチュエーションへの対応です。
名前を自動生成するONNXファイルと出力するファイル名を指定するだけですので細かい説明は省略します。
|
1 2 3 |
sng4onnx \ --input_onnx_file_path emotion-ferplus-8.onnx \ --output_onnx_file_path emotion-ferplus-8_renamed.onnx |
結果は下図のとおりです。
7-24. doc_stringの自動クリーニング (sde4onnx)
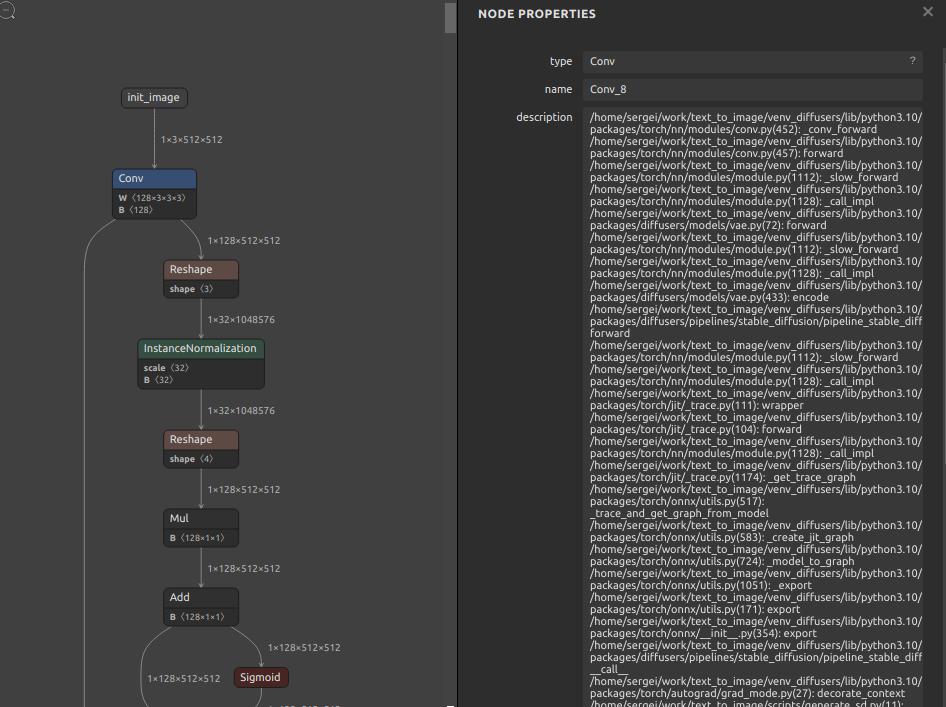
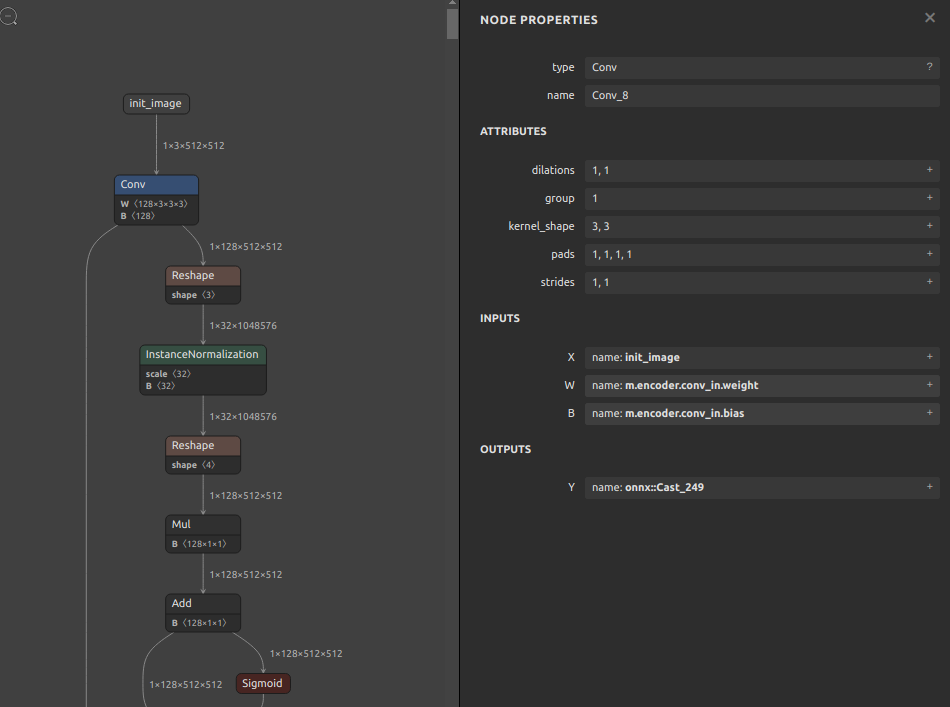
こちらもかなり限られたシチェーションのみを想定したツールです。Hugging Faceで公開されている Stable Diffusion の vae_encoder.onnx をターゲットに作成しました。どう見てもゴミとしか思えない文字列の羅列を除去します。sergei さんの環境情報にはあまり興味がありませんので削除します。
|
1 2 3 |
sde4onnx \ --input_onnx_file_path vae_encoder.onnx \ --output_onnx_file_path vae_encoder_erased.onnx |
7-25. GUIによるモデルのビジュアライズと加工 (OnnxGraphQt)
シェルやPythonのコードを書くことに抵抗を感じる方がいらっしゃるかもしれませんが、実はGUIで前述のツール群を組み合わせてモデル加工を行うためのOSSが誕生しています。 OnnxGraphQt というツールです。Netronを活用されている方々は多いと思いますが、このツールはビジュアライズをしたうえにモデル加工まで行うことができる点でアドバンテージがあります。バックエンドで私が作成したツール群をコールしていただいているため、私のツール群側のバグあるいはインタフェース不足にUI機能が制約されている可能性はあります。私のツール側、あるいは OnnxGraphQt へプルリクエストを発行してください。心よりお待ちしております。

前述でご紹介したようなシェルを実行する代わりにUIで直感的に操作することができるため馴染みやすいのではないかと思います。文字で説明するより画像で雰囲気をご覧ください。
- ONNXモデルの構造把握
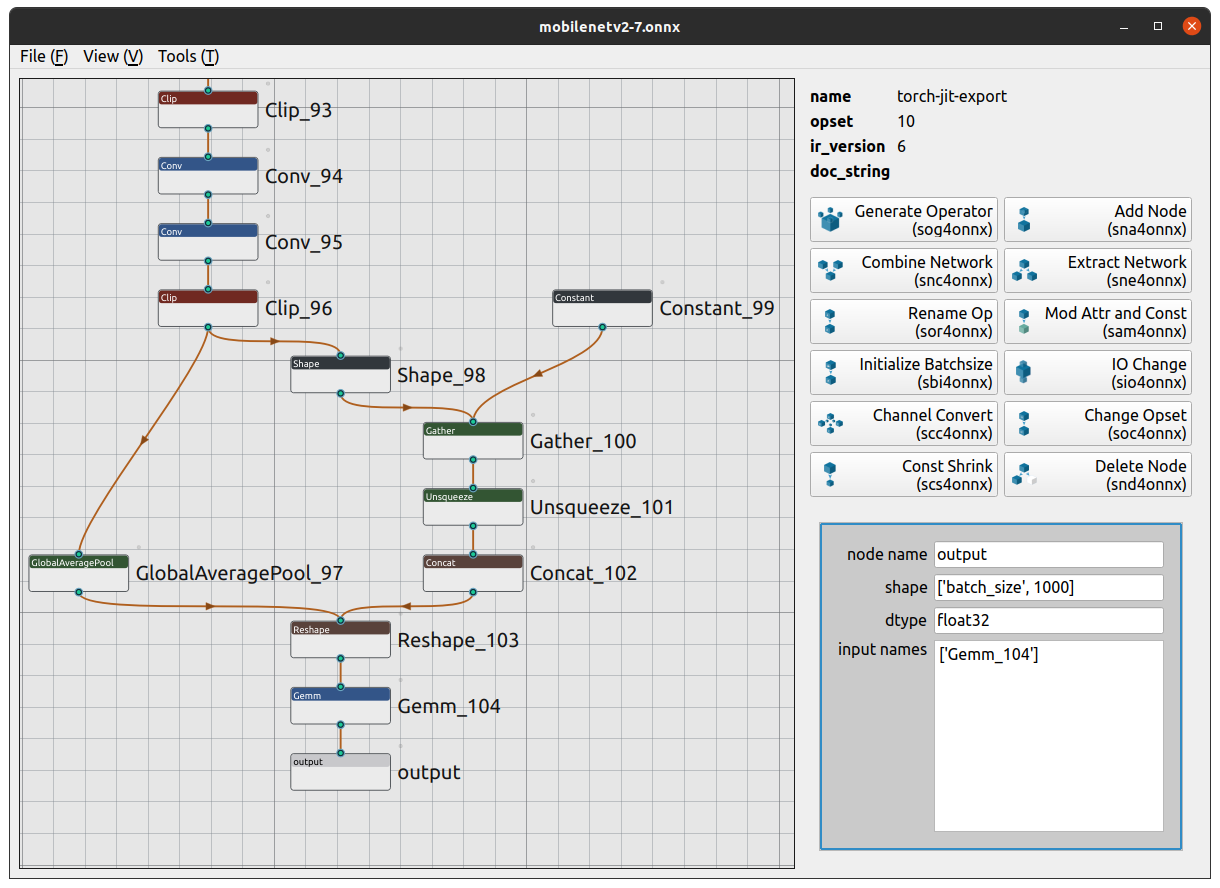
- ディテールの確認
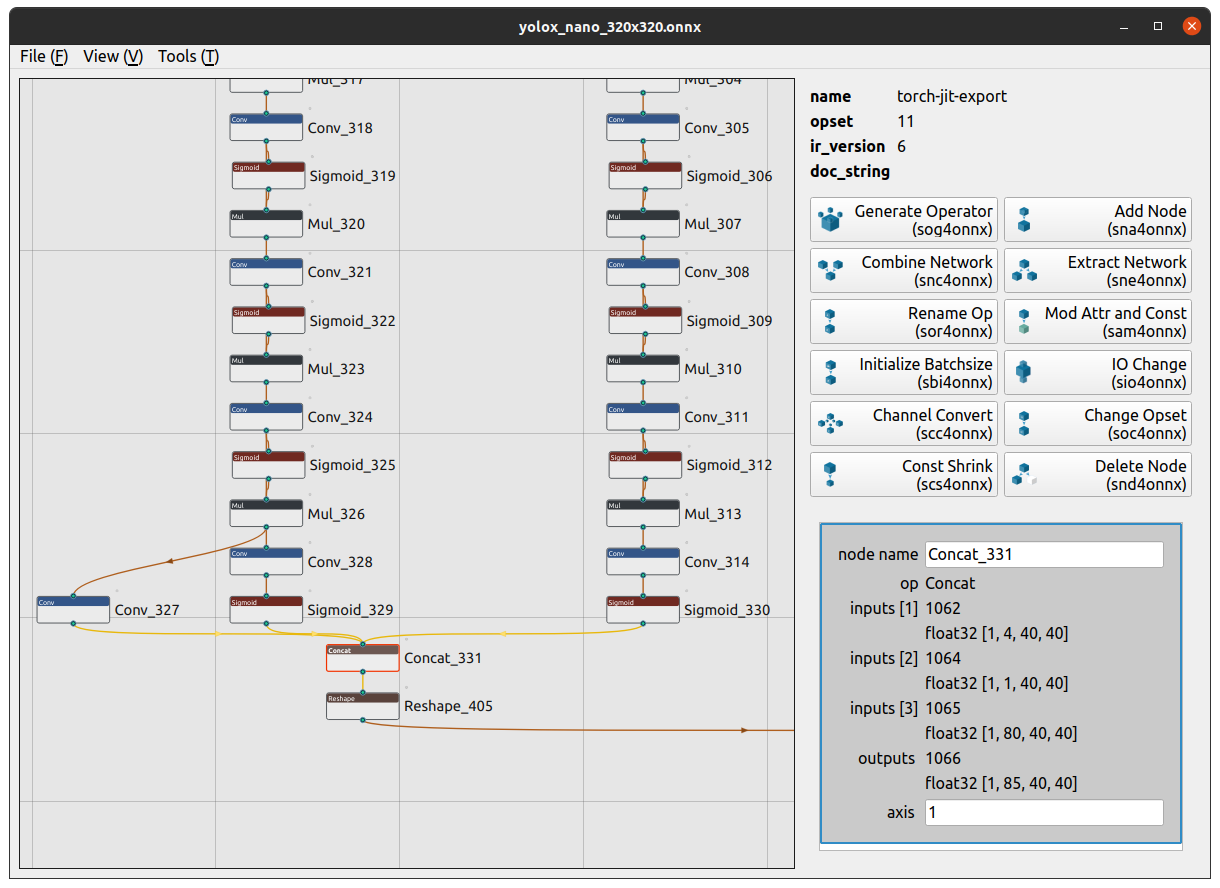
- Nodeの検索
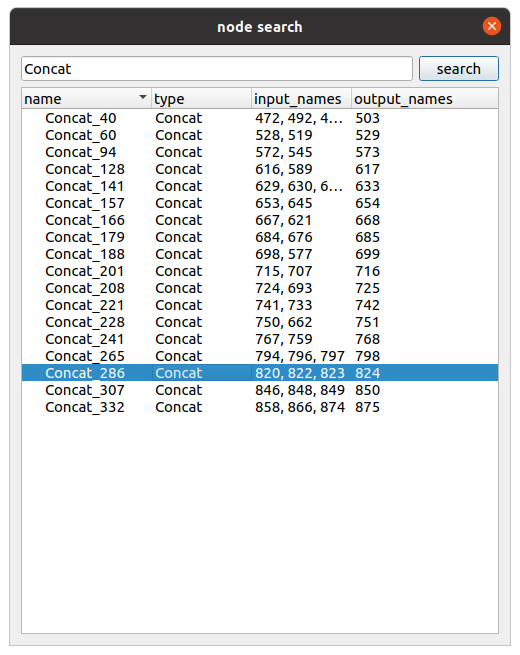
トップ画面の右側ペインに、モデル加工を行うための操作ボタンが配置されており、私が作成したCUIツールとは違って、どのような操作ができるのか がボタンに明示されています。遷移先の子画面では、モデル加工に必要なパラメータをリストから選択したり直接キーボードで入力するようになっており、モデル加工を行ううえではとてもユーザーフレンドリーな設計になっています。ご興味がある方は是非お試し下さい。
X. おわりに
長くなりましたが、ONNXのモデルチューニングテクニック (応用編1) は以上です。次回は 応用編2 として、今回1記事で書ききれなかったテクニックをご紹介したいと思います。なお、次回の章タイトルは変更する可能性があります。
-
各種PyTorchトリック
-
各種フレームワーク向けモデルへの変換
- TensorFlow
- TensorFlow.js
- TensorRT
- CoreML
- OpenVINO
Author