Blog
ONNXモデルのチューニングテクニック (応用編2)
サイバーエージェント AI Lab の Human Computer Interaction Team に所属している兵頭です。今回は私が半年ほど蓄積したONNXのチューニングテクニックを全てブログに残したいと思います。皆さんが既にご存知であろう基本的なことから、かなりトリッキーなチューニングまで幅広くご紹介したいと思います。長文になりますがご容赦願います。今回は応用編2です。
8. 各種トリック
PyTorchやTensorFlowを経由して生成されたONNXから他のフレームワークへモデルを転用する場合に有効な様々なトリック、ワークアラウンドをご紹介します。あまり真新しい知見ではありませんが、以下でご紹介するようなトリックが記事としてまとまっているものはあまり見かけませんのでご参考になれば幸いです。エンジニアよりもリサーチャーの方々に是非読んでいただきたい内容です。ほとんどの内容が地味で目立たないテクニックですが、実用まで見据えたうえではとても重要なものが一部含まれていると考えています。この最終回では実装の内容へ完全にフォーカスします。
8-1. GridSample (Bilinear no-loop only)
GridSample は ONNX の opset=16 から使用可能なオペレーションです。opset=16 が使用可能になるまで、古い PyTorch や onnxruntime では生成できませんでした。これは、PyTorchからONNXへエクスポートするときにバックエンドでコールしている onnx-optimizer、onnxruntime、PyTorchの onnx exporter の実装に依存しており、全てのランタイムが最新化されていなければ使用できないためです。しかし、アテンション系やステレオ画像をインプットとして扱うモデルでのアフィン変換で使用する必要があるなど、ニッチですが実は需要が高いオペレーションでもあります。
opset=16 では 下図のようにとてもシンプルな GridSample OP が生成されます。
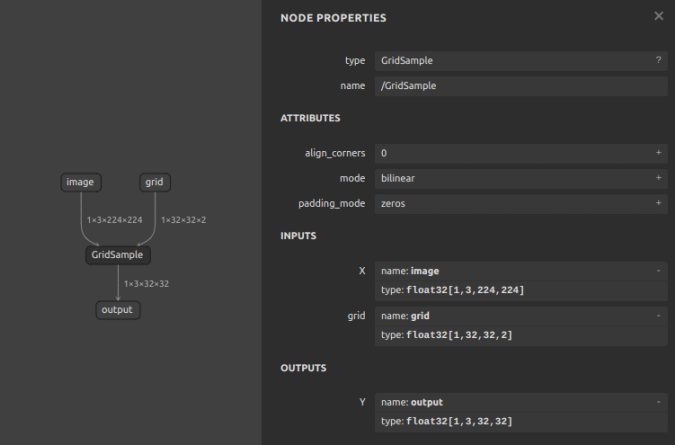
このまま opset=16 の設定のモデルで onnxruntime を使用する場合は特に問題になることはありません。しかし、ONNXの利用シーンは最も基本的な利用形態の ONNX + CPU や ONNX + CUDA に加えて ONNX + OpenVINO、ONNX + DirectML、ONNX + NNAPI、ONNX + CoreML、ONNX + TensorRT などの様々なハードウェアやフレームワークへ最適化された環境で利用することも多いと思います。その場合、転用先のフレームワークによっては GridSample のような最新のオペレータに対応しておらず、CPUやCUDAへフォールバックしてしまい、動作が遅くなったりすることが多いです。 特に TensorRT は Jetson などのエッジデバイスで高速に推論するために利用されている方が多いと思いますが、JetPack のバージョンによって利用できる TensorRT のバージョンが大きく異なるため、サポートされるオペレーションとサポートされないオペレーションの差が大きいです。
下記の Jetpack の概要を読むと、Jetson ORIN/NX で利用可能な JetPack 5.1 では TensorRT 8.5.2 が利用できるのに対して、Jetson Nano で利用可能な JetPack 4.6 では TensorRT 8.2.1 とあり、マイナーバージョンで 3 の差というのはかなり大きな差で、扱えるオペレーションの種類が大きく異なります。
https://developer.nvidia.com/embedded/jetpack
ご参考までに TensorRT 8.5 と TensorRT 8.4 の差分を下記の通りマイナーバージョン 1 つ分の差ではどれほど違うかが分かるURLを共有します。
TensorRT 8.5 で対応しているオペレータの一覧は下記のとおりです。
-
Supported ONNX Operators – TensorRT 8.5 supports operators up to Opset 17
https://github.com/onnx/onnx-tensorrt/blob/release/8.5-GA/docs/operators.md
TensorRT 8.4 で対応しているオペレータの一覧は下記のとおりです。
-
Supported ONNX Operators – TensorRT 8.4 supports operators up to Opset 17
https://github.com/onnx/onnx-tensorrt/blob/release/8.4-GA/docs/operators.md
TensorRT 8.2 で対応しているオペレータの一覧は下記の通りです。
-
Supported ONNX Operators – TensorRT 8.2 supports operators up to Opset 13
https://github.com/onnx/onnx-tensorrt/blob/release/8.2-GA/docs/operators.md
opset=17 まで対応しているバージョンでも GridSample に対応しているか、対応していないかの差分があります。また、バージョン差によるバグの内在などの問題によって、一見すると対応しているオペレーションに見えても正常に動作しないこともあります。したがって、最新のバージョンでモデルの構造を大きく最適化することだけが運用するうえでの最適な選択とは言えないため、ココではあえて GridSample をプリミティブなレイヤーへ分解して再実装します。
では、opset=16 の GridSample と opset=11 の GridSample (Bilinear no-loop only) を生成してみます。
make_GridSample.py
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103import torchimport torch.nn as nnclass Model16(nn.Module):def __init__(self):super(Model16, self).__init__()def forward(self, x, grid):ret = nn.functional.grid_sample(input=x, grid=grid)return retclass Model11(nn.Module):def __init__(self):super(Model11, self).__init__()def forward(self, x, grid):Nt, C, H, W = x.shapegrid_H = grid.shape[1]grid_W = grid.shape[2]xgrid, ygrid = torch.split(tensor=grid,split_size_or_sections=[1, 1],dim=-1,)mask = ((xgrid >= 0) & (ygrid >= 0) & (xgrid < W - 1) & (ygrid < H - 1)).float()x0 = torch.floor(xgrid)x1 = x0 + 1y0 = torch.floor(ygrid)y1 = y0 + 1wa = ((x1 - xgrid) * (y1 - ygrid)).permute(3, 0, 1, 2)wb = ((x1 - xgrid) * (ygrid - y0)).permute(3, 0, 1, 2)wc = ((xgrid - x0) * (y1 - ygrid)).permute(3, 0, 1, 2)wd = ((xgrid - x0) * (ygrid - y0)).permute(3, 0, 1, 2)x0 = (x0 * mask).view(Nt, grid_H, grid_W).long()y0 = (y0 * mask).view(Nt, grid_H, grid_W).long()x1 = (x1 * mask).view(Nt, grid_H, grid_W).long()y1 = (y1 * mask).view(Nt, grid_H, grid_W).long()ind = torch.arange(Nt)ind = ind\.view(Nt, 1)\.expand(-1, grid_H)\.view(Nt, grid_H, 1)\.expand(-1, -1, grid_W)\.long()x = x.permute(1, 0, 2, 3)output_tensor = (x[:, ind, y0, x0] * wa \+ x[:, ind, y1, x0] * wb \+ x[:, ind, y0, x1] * wc \+ x[:, ind, y1, x1] * wd).permute(1, 0, 2, 3)ret = output_tensor * mask.permute(0, 3, 1, 2).expand(-1, C, -1, -1)return retmodel = Model16()x = torch.randn([1,3,224,224])grid = torch.randn([1,32,32,2])onnx_file = f'GridSample_16.onnx'torch.onnx.export(model,args=(x, grid),f=onnx_file,opset_version=16,input_names=['image','grid',],output_names=['output',],)import onnxfrom onnxsim import simplifymodel_onnx2 = onnx.load(onnx_file)model_simp, check = simplify(model_onnx2)onnx.save(model_simp, onnx_file)model = Model11()x = torch.randn([1,3,224,224])grid = torch.randn([1,32,32,2])onnx_file = f'GridSample_11.onnx'torch.onnx.export(model,args=(x, grid),f=onnx_file,opset_version=11,input_names=['image','grid',],output_names=['output',],)import onnxfrom onnxsim import simplifymodel_onnx2 = onnx.load(onnx_file)model_simp, check = simplify(model_onnx2)onnx.save(model_simp, onnx_file)
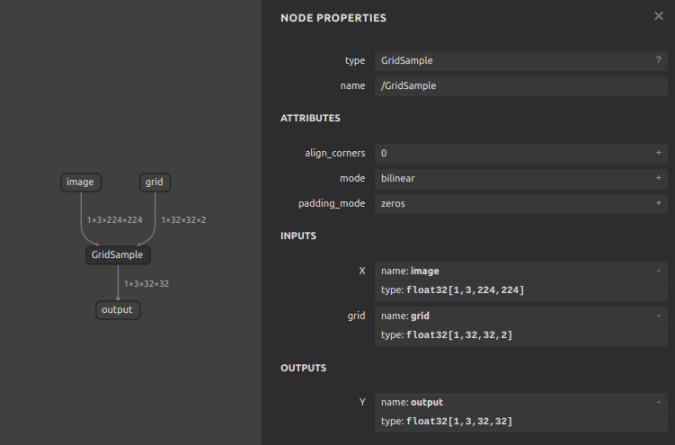
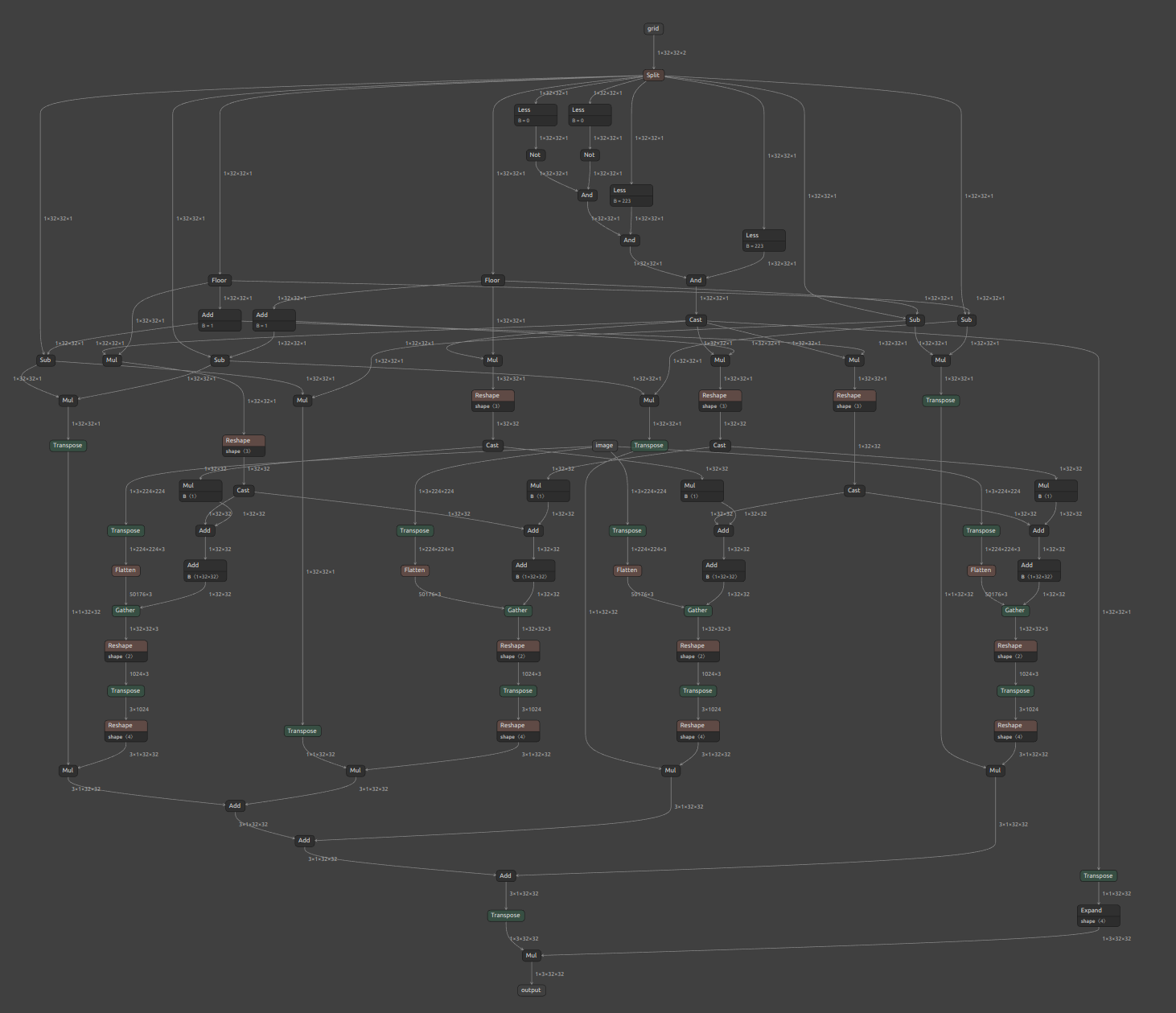
画像が小さく見づらいですが、下図のとおりの生成結果となりました。独自実装の opset=11 の GridSample はプリミティブなオペレーションのみで構成されているため、比較的古いバージョンのフレームワーク群でも実行可能な構成になっています。
-
opset=16で生成したGridSample(再掲)
-
opset=11で生成した自力実装のpseudo_GridSample
最適化と機能性のトレードオフのギリギリを攻めていますので、
Loopなどのファンクショナルなオペレーションを使用せずに無理やりリニアに実装していることと、4次元までのBilinearにしか対応していません。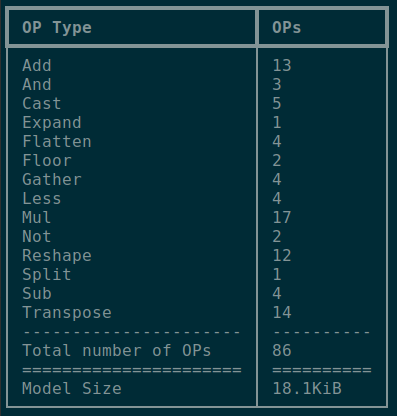
念の為、処理パフォーマンスにどれほど差が出るかを見てみます。手元の TensorRT バージョンは 8.5.3、CUDA バージョンは 11.6、cuDNN バージョンは 8.6.0、GPUは RTX3070、CPUは Corei9 Gen.10 です。1ms未満の世界の話ではありますが、CUDAあるいはCPUを選択すると独自実装では 5倍〜10倍程度 のパフォーマンス劣化が発生するようです。GridSample を使用できる環境の場合は素直に GridSample を使用したほうが良さそうですね。TensorRT以外のフレームワークではベンチマークしませんが、その他のフレームワークに GridSample と同じ動作をするオペレーションがある場合は問題にならないかもしれません。オペレーションが存在しない場合はいずれにせよプリミティブなオペレーションへ分解する必要はありそうです。
opset=16で生成したGridSample
12345678910sit4onnx -if GridSample_16.onnx -oep tensorrtINFO: file: GridSample_16.onnxINFO: providers: ['TensorrtExecutionProvider', 'CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 1.2667179107666016 msINFO: avg elapsed time per pred: 0.12667179107666016 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float32
12345678910sit4onnx -if GridSample_16.onnx -oep cudaINFO: file: GridSample_16.onnxINFO: providers: ['CUDAExecutionProvider', 'CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 0.5278587341308594 msINFO: avg elapsed time per pred: 0.05278587341308594 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float3
12345678910sit4onnx -if GridSample_16.onnx -oep cpuINFO: file: GridSample_16.onnxINFO: providers: ['CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 0.26607513427734375 msINFO: avg elapsed time per pred: 0.026607513427734375 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float32opset=11で生成した自力実装のpseudo_GridSample
12345678910sit4onnx -if GridSample_11.onnx -oep tensorrtINFO: file: GridSample_11.onnxINFO: providers: ['TensorrtExecutionProvider', 'CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 1.1916160583496094 msINFO: avg elapsed time per pred: 0.11916160583496094 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float32
12345678910sit4onnx -if GridSample_11.onnx -oep cudaINFO: file: GridSample_11.onnxINFO: providers: ['CUDAExecutionProvider', 'CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 2.634763717651367 msINFO: avg elapsed time per pred: 0.2634763717651367 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float32
12345678910sit4onnx -if GridSample_11.onnx -oep cpuINFO: file: GridSample_11.onnxINFO: providers: ['CPUExecutionProvider']INFO: input_name.1: image shape: [1, 3, 224, 224] dtype: float32INFO: input_name.2: grid shape: [1, 32, 32, 2] dtype: float32INFO: test_loop_count: 10INFO: total elapsed time: 3.2453536987304688 msINFO: avg elapsed time per pred: 0.3245353698730469 msINFO: output_name.1: output shape: [1, 3, 32, 32] dtype: float32
8-2. Mulit-Class Batched NonMaxSuppression
基礎編 で簡単にご紹介した Multi-Batch / Multi-Class の NonMaxSuppression (NMS) 実装の具体例をご紹介します。まずは PyTorch から正攻法で生成可能な NMS です。
torchvision.ops の nms を使用していますが、バッチサイズの指定に対応していないため N=10 (box数) と 4 (x1y1x2y2) だけを指定してオペレーションを生成しています。
-
NMS
https://pytorch.org/vision/main/generated/torchvision.ops.nms.html
123456789boxes (Tensor[N, 4]))boxes to perform NMS on.They are expected to be in (x1, y1, x2, y2) format with 0 <= x1 < x2 and 0 <= y1 < y2.scores (Tensor[N])scores for each one of the boxesiou_threshold (float)discards all overlapping boxes with IoU > iou_threshold -
生成サンプル
123456789101112131415161718192021222324252627282930313233343536373839import torchimport torch.nn as nnfrom torchvision.ops import nmsclass Model(nn.Module):def __init__(self, iou_threshold):super(Model, self).__init__()self.iou_threshold = iou_thresholddef forward(self, boxes, scores):return nms(boxes, scores, self.iou_threshold)########################################### TorchVision (No batch size)boxes = torch.randn([10,4]) # [N, 4]scores = torch.randn([10]) # [N]iou_threshold = 0.5model_size = Model(iou_threshold)onnx_file = f'nms_11.onnx'torch.onnx.export(model_size,args=(boxes, scores),f=onnx_file,opset_version=11,input_names=['boxes','scores',],output_names=['output',],)import onnxfrom onnxsim import simplifymodel_onnx2 = onnx.load(onnx_file)model_simp, check = simplify(model_onnx2)onnx.save(model_simp, onnx_file)一見すると問題が無いように見えますが、
nmsに指定可能なパラメータにバッチサイズやクラス数が存在しないため、ONNX生成時にバッチサイズ1、クラス数1が自動的に割り当てられています。したがって、Multi-BatchやMulti-Classの NMS を生成する場合は大量のNMSを生成する必要があります。また注意点として、PyTorch の NMS はX1Y1X2Y2の座標入力を期待しますが、ONNX の NMS はY1X1Y2X2の座標入力を期待します。PyTorch 単体で NMS を含めた後処理を構築する場合はあらかじめX1Y1X2Y2をY1X1Y2X2などに転置しておくことを忘れないようにしないといけません。また、このように必要機能を満たさないオペレーションを生成するぐらいなら、ロジック側で素直にNMSの処理を実装したほうが効率的です。
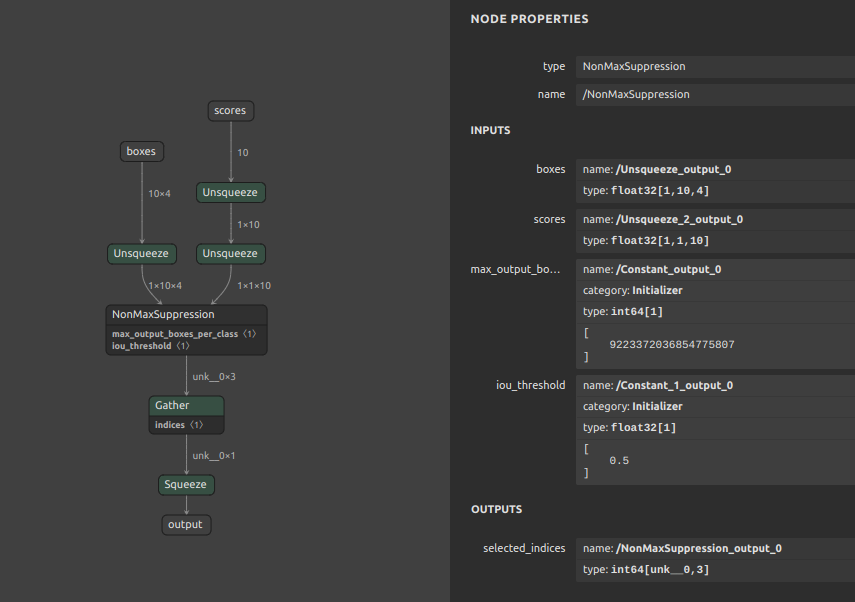
-
Mulit-Class Batched NonMaxSuppression の実装紹介
ONNX の NMS は
Mulit-ClassとMulit-Batchに対応しています。したがって、冗長な複数のNMSをPyTorchで生成するのではなく、ONNX の NMS を直接生成することでマルチクラス化とマルチバッチ化に対応します。Mulit-Class Batched NonMaxSuppressionを生成するサンプルスクリプトは下記のとおりですが、Pythonのコードを書かずに NMS を生成します。私の作業環境がUbuntuであるため、便宜上bashを利用して下記のスクリプトを実行することを想定しています。コマンドプロンプトやその他のシェルで実行する場合は、変数の宣言方法や参照方法、エスケープの記載方法が異なる点にご注意願います。1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859#!/bin/bashsog4onnx \--op_type Constant \--opset 11 \--op_name max_output_boxes_per_class_const \--output_variables max_output_boxes_per_class int64 [1] \--attributes value int64 [20] \--output_onnx_file_path Constant_max_output_boxes_per_class.onnxsog4onnx \--op_type Constant \--opset 11 \--op_name iou_threshold_const \--output_variables iou_threshold float32 [1] \--attributes value float32 [0.5] \--output_onnx_file_path Constant_iou_threshold.onnxsog4onnx \--op_type Constant \--opset 11 \--op_name score_threshold_const \--output_variables score_threshold float32 [1] \--attributes value float32 [-inf] \--output_onnx_file_path Constant_score_threshold.onnxOP=NonMaxSuppressionLOWEROP=${OP,,}NUM_BATCHES=5SPATIAL_DIMENSION=19248NUM_CLASSES=80OPSET=11sog4onnx \--op_type ${OP} \--opset ${OPSET} \--op_name ${LOWEROP}${OPSET} \--input_variables boxes_var float32 [${NUM_BATCHES},${SPATIAL_DIMENSION},4] \--input_variables scores_var float32 [${NUM_BATCHES},${NUM_CLASSES},${SPATIAL_DIMENSION}] \--input_variables max_output_boxes_per_class_var int64 [1] \--input_variables iou_threshold_var float32 [1] \--input_variables score_threshold_var float32 [1] \--output_variables selected_indices int64 [\'N\',3] \--attributes center_point_box int64 0 \--output_onnx_file_path ${OP}${OPSET}.onnxsnc4onnx \--input_onnx_file_paths Constant_max_output_boxes_per_class.onnx NonMaxSuppression11.onnx \--srcop_destop max_output_boxes_per_class max_output_boxes_per_class_var \--output_onnx_file_path NonMaxSuppression11.onnxsnc4onnx \--input_onnx_file_paths Constant_iou_threshold.onnx NonMaxSuppression11.onnx \--srcop_destop iou_threshold iou_threshold_var \--output_onnx_file_path NonMaxSuppression11.onnxsnc4onnx \--input_onnx_file_paths Constant_score_threshold.onnx NonMaxSuppression11.onnx \--srcop_destop score_threshold score_threshold_var \--output_onnx_file_path NonMaxSuppression11.onnx5 Batch、80 Class の NMS が生成されました。この NMS はクラスIDを横断的に見て閾値を判定してくれます。生成したNMS単体ではメリットがありませんので、この部品を生成したあとにモデル本体へマージする必要があります。モデルへの部品のマージは 応用編1 をご覧ください。
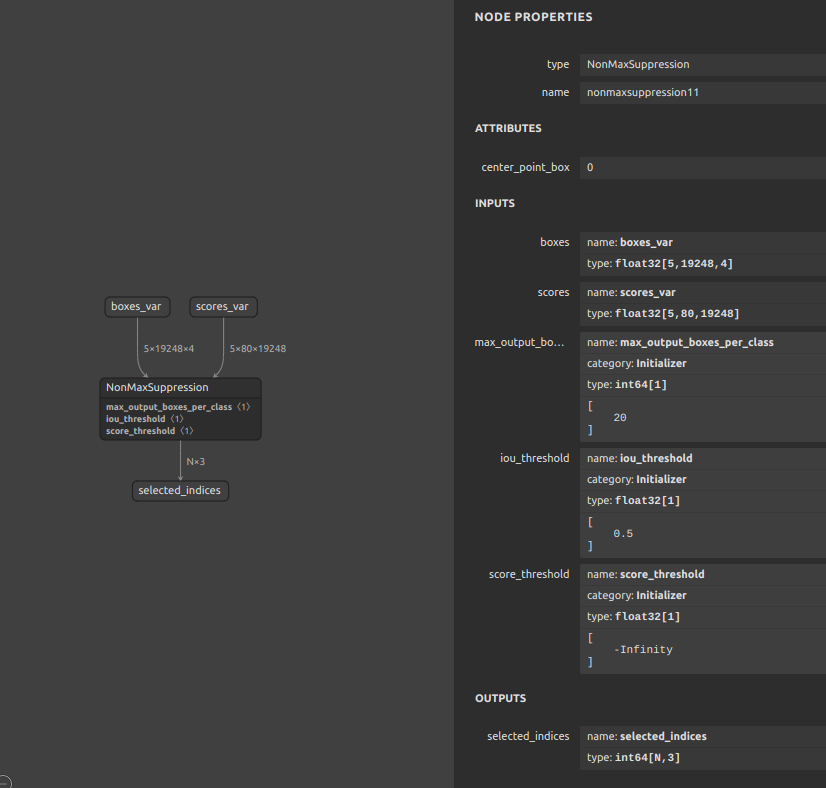
-
各フレームワークへ横展開するうえでのポイント (ArgMax / ReduceMax活用による次元圧縮)
昔から使用されている方法のため、テクニック、というほどのものではありませんが、バッチサイズとクラス数をNMSに入力する前の段階で
1にシュリンクする方法があります。この方法であれば最近のほぼどのフレームワークでも実行可能な後処理(NMS)が生成されます。なお、ここで言う NMS は、NonMaxSuppressionオペレーション単体を指すのではなく、下図画像のほぼ全体のオペレーション群全体を指します。オペレーションの数が多いためとても複雑なことをしているように見えるかもしれませんが、実はこの方法が最も多くのフレームワークで処理可能なシンプルな構造になっています。できるかぎりプリミティブなオペレーションを組み合わせると共にバッチサイズやクラス数を1に限定することで、ほとんどのフレームワークで実行可能なNMSになります。(1)ArgMaxでスコアが最大のクラスIDを抽出し、(2)ReduceMaxで最大スコアを抽出しています。(1) をバウンディングボックス群を特定のクラスIDひとつに絞り込むインデックスとして使用し、(2) の最大スコア (ひとつのクラスのスコア) とともにNonMaxSuppressionの入力に使用しています。これは YOLOv7 の後処理をそのまま引用しています。この実装の弱点は、不必要なFlattenやGatherを大量に使用することにより、バッチサイズを無視してしまう実装になっていることと、1クラスのみのNMSに限定してしまっていることです。ただ、フレームワーク間の横展開の柔軟性が最も高い実装ですので、運用上、複数クラスのNMSが不要な場合や1バッチのみで処理できれば良い場合は良い選択肢になると考えています。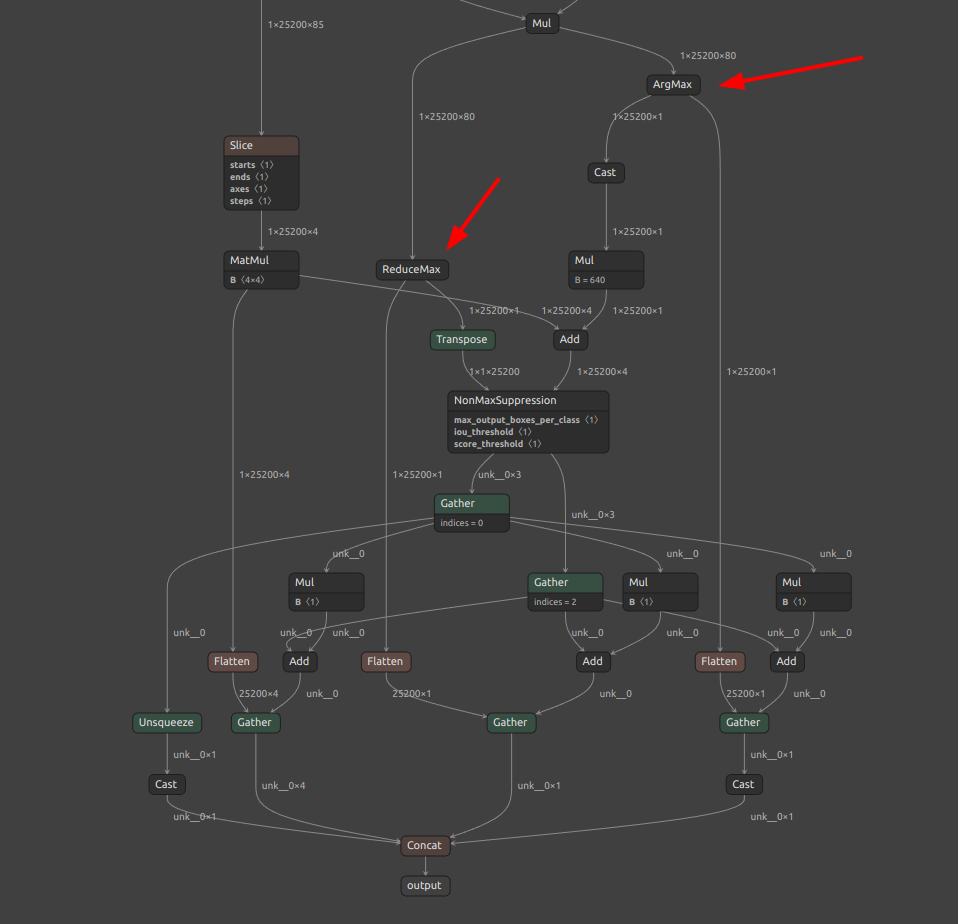
実装は下記のとおりです。YOLOv7の後処理の実装そのものです。感覚的に、YOLOv7の後処理はとても綺麗に実装されています。ポイントは
max_score, category_id = scores.max(2, keepdim=True)の部分でArgMaxとReduceMaxを同時に生成しているところのみです。123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354class ONNX_ORT(nn.Module):'''onnx module with ONNX-Runtime NMS operation.'''def __init__(self,max_obj=100,iou_thres=0.45,score_thres=0.25,max_wh=640,device=None,n_classes=80):super().__init__()self.device = device if device else torch.device("cpu")self.max_obj = torch.tensor([max_obj]).to(device)self.iou_threshold = torch.tensor([iou_thres]).to(device)self.score_threshold = torch.tensor([score_thres]).to(device)self.max_wh = max_wh # if max_wh != 0 : non-agnostic else : agnosticself.convert_matrix = torch.tensor([[1, 0, 1, 0], [0, 1, 0, 1], [-0.5, 0, 0.5, 0], [0, -0.5, 0, 0.5]],dtype=torch.float32,device=self.device)self.n_classes=n_classesdef forward(self, x):boxes = x[:, :, :4]conf = x[:, :, 4:5]scores = x[:, :, 5:]if self.n_classes == 1:# for models with one class, cls_loss is 0 and cls_conf is always 0.5,# so there is no need to multiplicate.scores = confelse:scores *= conf # conf = obj_conf * cls_confboxes @= self.convert_matrixmax_score, category_id = scores.max(2, keepdim=True)dis = category_id.float() * self.max_whnmsbox = boxes + dismax_score_tp = max_score.transpose(1, 2).contiguous()selected_indices = \ORT_NMS.apply(nmsbox,max_score_tp,self.max_obj,self.iou_threshold,self.score_threshold,)X, Y = selected_indices[:, 0], selected_indices[:, 2]selected_boxes = boxes[X, Y, :]selected_categories = category_id[X, Y, :].float()selected_scores = max_score[X, Y, :]X = X.unsqueeze(1).float()return torch.cat([X, selected_boxes, selected_categories, selected_scores], 1)1234567891011121314151617181920212223242526272829303132333435363738394041424344class ORT_NMS(torch.autograd.Function):'''ONNX-Runtime NMS operation'''@staticmethoddef forward(ctx,boxes,scores,max_output_boxes_per_class=torch.tensor([100]),iou_threshold=torch.tensor([0.45]),score_threshold=torch.tensor([0.25])):device = boxes.devicebatch = scores.shape[0]num_det = random.randint(0, 100)batches = torch.randint(0, batch, (num_det,)).sort()[0].to(device)idxs = torch.arange(100, 100 + num_det).to(device)zeros = torch.zeros((num_det,), dtype=torch.int64).to(device)selected_indices = torch.cat([batches[None],zeros[None],idxs[None]],0,).T.contiguous()selected_indices = selected_indices.to(torch.int64)return selected_indices@staticmethoddef symbolic(g,boxes,scores,max_output_boxes_per_class,iou_threshold,score_threshold):return g.op("NonMaxSuppression",boxes,scores,max_output_boxes_per_class,iou_threshold,score_threshold,)
8-3. Unity Barracuda用 GatherND
Barracuda は Unity がサポートしているデバイス上でONNXによる推論をサポートするためのパッケージです。2023年3月1日時点では v3.0.0 がリリースされているようです。私はあまりUnityを使用したことが無いのですが、VR/AR界隈で使用されているように見えます。Unityの他にも Unreal Engine というエンジンがあり、そちらでもONNXをサポートしているようです。CPU利用がメインのようですが、DirectMLを経由することでGPUを使うこともできるようです。このブログではそれぞれのエンジンの良し悪しを比較することが目的ではありませんので、ここでは Unity Barracuda での事例を取り上げます。
-
Unity Barracuda 3.0.0 でサポートされているONNXのオペレーション一覧
https://docs.unity3d.com/Packages/com.unity.barracuda@3.0/manual/SupportedOperators.html
-
OnnxRuntime-UnrealEngine
https://github.com/microsoft/OnnxRuntime-UnrealEngine
C++で扱うことを主としているようですが、PythonからコールするためのAPIも用意されているようです。
https://docs.unrealengine.com/5.0/en-US/PythonAPI/class/NeuralNetwork.html
Unity Barracuda を使用してUnityへONNXを取り込み、UnityにONNX推論を行わせることができます。先述のように、すでに Barracuda は多くのオペレーションに対応しているため、多くのONNXモデルを実行することができるように見えます。
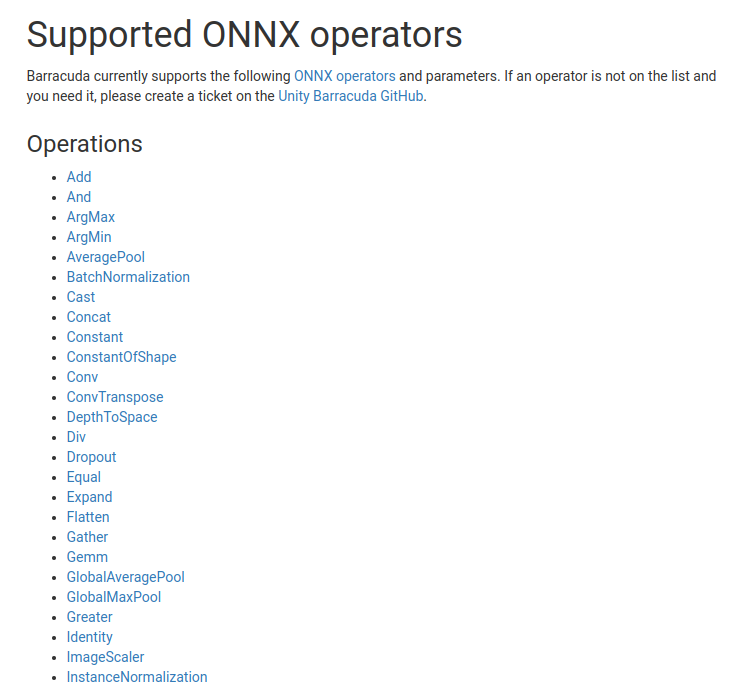
ここで「できるように見えます。」とあえて含みをもたせた表現をしたことには理由があり、仮に対応オペレーション一覧に記載があるオペレーションであったとしても、Barracuda内部の実装の問題で正常に動作しないことがあります。この点に関しては次の項でご紹介します。
さて本題に戻りますが、この項では対応オペレーション一覧に存在しないオペレーション GatherND を Unity Barracuda に対応させるためのワークアラウンドをご紹介します。GatherND を含むモデルを Unity Barracuda に読み込ませるとオペレーション非対応を示すエラーが表示されます。したがって、GatherND を Unity Barracuda に対応したオペレーションのみの組み合わせに置き換えることで無理やり対応させます。
ただし、PyTorchには GatherND が存在しません。自力で GatherND をシミュレートした処理をPyTorchで実装するか、PyTorch以外の手段で代替するか、のいずれかの方法を選択する必要があります。PyTorchの実装をアレコレと試しましたがなかなかうまくいきませんでした。今回は中間処理に TensorFlow を使用して GatherND を生成します。中間処理にわざわざ TensorFlow を使用することにはあまりメリットを感じないかもしれませんが、GatherND は重みを持たない単純なインデクシングのオペレーションですので PyTorch にこだわる必要もありません。最終的な目的がONNXを使用すること、である場合は、TensorFlow を使用して生成した GatherND を tf2onnx を介してONNXへ変換することでONNXの GatherND を生成します。このブログ自体がかなりトリッキーなノウハウを共有することを目的としているため難解な点がある場合はご容赦願います。
TensorFlow GatherND -> tf2onnx -> ONNX GatherND
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 |
#! /usr/bin/env python import os os.environ['CUDA_VISIBLE_DEVICES'] = '-1' os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' import logging import warnings warnings.simplefilter(action='ignore', category=FutureWarning) warnings.simplefilter(action='ignore', category=Warning) warnings.simplefilter(action='ignore', category=DeprecationWarning) warnings.simplefilter(action='ignore', category=RuntimeWarning) import numpy as np np.random.seed(0) import onnx import tf2onnx import tensorflow as tf tf.random.set_seed(0) tf.keras.utils.set_random_seed(0) tf.config.experimental.enable_op_determinism() tf.get_logger().setLevel('INFO') tf.autograph.set_verbosity(0) tf.get_logger().setLevel(logging.FATAL) from sor4onnx import rename from ast import literal_eval from argparse import ArgumentParser def barracuda_gather_nd(params, indices): idx_shape = indices.shape params_shape = params.shape idx_dims = idx_shape[-1] gather_shape = params_shape[idx_dims:] params_flat = tf.reshape( params, tf.concat([[-1], gather_shape], axis=0), ) axis_step = tf.math.cumprod( params_shape[:idx_dims], exclusive=True, reverse=True, ) mul = tf.math.multiply( indices, axis_step, ) indices_flat = tf.reduce_sum( mul, axis=-1, ) result_flat = tf.gather( params_flat, indices_flat, ) return tf.reshape( result_flat, tf.concat([idx_shape[:-1], gather_shape], axis=0), ) def normal_gather_nd(params, indices): return tf.gather_nd(params, indices) if __name__ == "__main__": """ python make_gathernd_replace.py \ --data_shape 1 48 64 17 \ --indices_shape 6 3 \ --opset 11 """ parser = ArgumentParser() parser.add_argument( '-ds', '--data_shape', type=str, nargs='+', required=True, help='Shape of input data "data"', ) parser.add_argument( '-is', '--indices_shape', type=str, nargs='+', required=True, help='Shape of input data "indices"', ) parser.add_argument( '-o', '--opset', type=int, default=11, help='onnx opset' ) args = parser.parse_args() data_shape = [] for s in args.data_shape: try: val = literal_eval(s) if isinstance(val, int) and val >= 0: data_shape.append(val) else: data_shape.append(s) except: data_shape.append(s) data_shape = np.asarray(data_shape, dtype=np.int32) indices_shape = [] for s in args.indices_shape: try: val = literal_eval(s) if isinstance(val, int) and val >= 0: indices_shape.append(val) else: indices_shape.append(s) except: indices_shape.append(s) indices_shape = np.asarray(indices_shape, dtype=np.int32) opset = args.opset ############################################# normal gather_nd output_path = 'gather_nd_normal' model_name = output_path # Create a model - TFLite data = tf.keras.layers.Input( shape=data_shape[1:], batch_size=data_shape[0], dtype=tf.float32, ) indices = tf.keras.layers.Input( shape=indices_shape[1:], batch_size=indices_shape[0], dtype=tf.int64, ) output = normal_gather_nd(data, indices) model = tf.keras.models.Model( inputs=[data, indices], outputs=[output], ) tf.saved_model.save(model, output_path) converter = tf.lite.TFLiteConverter.from_keras_model(model) converter.target_spec.supported_ops = [ tf.lite.OpsSet.TFLITE_BUILTINS, tf.lite.OpsSet.SELECT_TF_OPS ] tflite_model = converter.convert() open(f"{output_path}/{model_name}.tflite", "wb").write(tflite_model) # Create a model - ONNX model_proto, external_tensor_storage = \ tf2onnx.convert.from_tflite( tflite_path=f"{output_path}/{model_name}.tflite", opset=opset, output_path=f"{output_path}/{model_name}.onnx", inputs_as_nchw=['serving_default_input_1:0'] ) # Optimization - ONNX model_onnx = onnx.load(f"{output_path}/{model_name}.onnx") model_onnx = onnx.shape_inference.infer_shapes(model_onnx) onnx.save(model_onnx, f"{output_path}/{model_name}.onnx") # Rename renamed_onnx = rename( old_new=[ 'serving_default_input_1:0','data' ], onnx_graph=model_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_2:0','indices' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'PartitionedCall:0','output' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_1:0__5:0','data_transpose_output' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_1:0__5','data_transpose' ], onnx_graph=renamed_onnx, non_verbose=True, ) onnx.save(renamed_onnx, f"{output_path}/{model_name}.onnx") ############################################# barracuda gather_nd output_path = 'gather_nd_barracuda' model_name = output_path # Create a model - TFLite data = tf.keras.layers.Input( shape=data_shape[1:], batch_size=data_shape[0], dtype=tf.float32, ) indices = tf.keras.layers.Input( shape=indices_shape[1:], batch_size=indices_shape[0], dtype=tf.int32, ) output = barracuda_gather_nd(data, indices) model = tf.keras.models.Model( inputs=[data, indices], outputs=[output], ) tf.saved_model.save(model, output_path) converter = tf.lite.TFLiteConverter.from_keras_model(model) converter.target_spec.supported_ops = [ tf.lite.OpsSet.TFLITE_BUILTINS, tf.lite.OpsSet.SELECT_TF_OPS ] tflite_model = converter.convert() open(f"{output_path}/{model_name}.tflite", "wb").write(tflite_model) # Create a model - ONNX model_proto, external_tensor_storage = \ tf2onnx.convert.from_tflite( tflite_path=f"{output_path}/{model_name}.tflite", opset=opset, output_path=f"{output_path}/{model_name}.onnx", inputs_as_nchw=['serving_default_input_3:0'] ) # Optimization - ONNX model_onnx = onnx.load(f"{output_path}/{model_name}.onnx") model_onnx = onnx.shape_inference.infer_shapes(model_onnx) onnx.save(model_onnx, f"{output_path}/{model_name}.onnx") # Rename renamed_onnx = rename( old_new=[ 'serving_default_input_3:0','data' ], onnx_graph=model_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_4:0','indices' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'PartitionedCall:0','output' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_3:0__9:0','data_transpose_output' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'serving_default_input_3:0__9','data_transpose' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'model_1/tf.reshape/Reshape','data_reshape' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'model_1/tf.math.multiply/Mul','indices_mul' ], onnx_graph=renamed_onnx, non_verbose=True, ) renamed_onnx = rename( old_new=[ 'model_1/tf.math.reduce_sum/Sum','indices_sum' ], onnx_graph=renamed_onnx, non_verbose=True, ) onnx.save(renamed_onnx, f"{output_path}/{model_name}.onnx") |
-
通常の
GatherND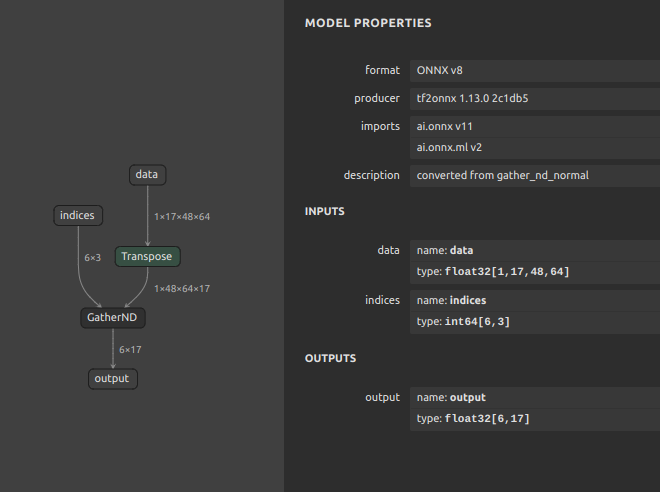
-
Unity Barracuda対応の
GatherND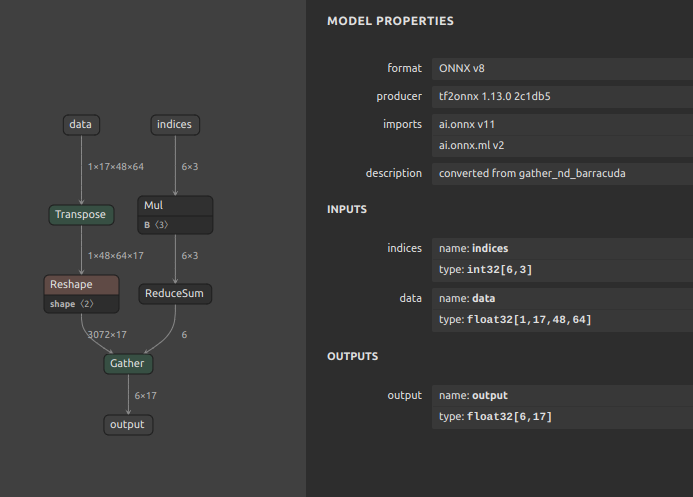
GatherND を生成するためだけにこれほど多くのロジックを書くこと自体がコストに見合わない、という判断があるのはごもっともですが、最小限のオペレーション数で GatherND の処理を実現することができます。また、ここでご紹介したオペレーションの作例は一例です。応用編1 でご紹介したテクニックを使用して直接 GatherND を生成してしまったほうが圧倒的に早いと思います。このテクニックはモデルの実装が公開されていないシチュエーションで主に使用します。
8-4. Unity Barracuda用 Unsqueeze
Unity Barracuda の Unsqueeze オペレーションのハンドリングには致命的なバグがあり、誤った位置に次元が追加されてテンソルが壊れる問題があります。したがって、PyTorchで生成したモデルを最終的に Unity Barracuda へ転用して運用する想定がある場合は、あらかじめ Unsqueeze を別のオペレーションへ置き換えてモデルを生成しておく必要があります。具体的には、次元を外挿したあとのテンソルの形状が自明な場合に最も安全な置き換え方法は Reshape です。
単純に Unsqueeze を Reshape へ置き換えるだけではありますが、このワークアラウンドを適用してモデルの構造をできるだけ最適化するにあたってのポイントは3つです。
- 外挿する次元を指定する
axis (dim)のパラメータの定数化が可能な場合はできるだけ定数化してからオペレーションを生成する。 torch.Tensorのshapeパラメータはモデルによってはx.shapeのまま利用するとPyTorchのonnx exporterが型推定に失敗してエラーになることがあるため、shapeが自明で定数化が可能な場合はあえてループの内包表記で Python の int型 へキャストしてからリストを再生成する。Reshapeのshapeパラメータには-1を使用しない。
2.に関しては具体的にどういうモデルで発生する事象かまでは言及しませんが、モデルの中間構造が可変形状になるテンソルを持たない場合はできるだけ定数化したほうがオプティマイザの最適化が有効に働きます。3.に関しては、運用フェーズに入ったときに意外とインパクトが出ます。ONNXの形状を書き換えたくなったときに -1 が含まれた形状を shape に指定していると操作不能になります。分かりやすい状況としては、バッチサイズを可変形状に書き換える場合にこの Reshape の -1 が邪魔になります。また -1 が含まれている場合、各種フレームワークのバグを誘発しやすくなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
import torch import torch.nn as nn ############################################# normal Unsqueeze class Model_Unsqueeze(nn.Module): def forward(self, x, axis): axis = int(axis.detach().numpy()) return torch.unsqueeze(input=x, dim=axis) ############################################# replace Reshape class Model_pseudo_Unsqueeze(nn.Module): def forward(self, x, axis): axis = int(axis.detach().numpy()) unsqueezed_shape = [ int(dim) for dim in x.shape ] unsqueezed_shape.insert(axis, 1) return torch.reshape(input=x, shape=tuple(unsqueezed_shape)) input_shape = [1,3,224,224] expand_axis = 2 x = torch.randn(input_shape) model = Model_Unsqueeze() onnx_file = f'unsqueeze_normal_11.onnx' torch.onnx.export( model, args=(x, expand_axis), f=onnx_file, opset_version=11, input_names=[ 'input', ], output_names=[ 'output', ], ) import onnx from onnxsim import simplify model_onnx2 = onnx.load(onnx_file) model_simp, check = simplify(model_onnx2) onnx.save(model_simp, onnx_file) model = Model_pseudo_Unsqueeze() onnx_file = f'unsqueeze_pseudo_11.onnx' torch.onnx.export( model, args=(x, expand_axis), f=onnx_file, opset_version=11, input_names=[ 'input', ], output_names=[ 'output', ], ) import onnx from onnxsim import simplify model_onnx2 = onnx.load(onnx_file) model_simp, check = simplify(model_onnx2) onnx.save(model_simp, onnx_file) |
-
通常の
Unsqueeze (opset=11)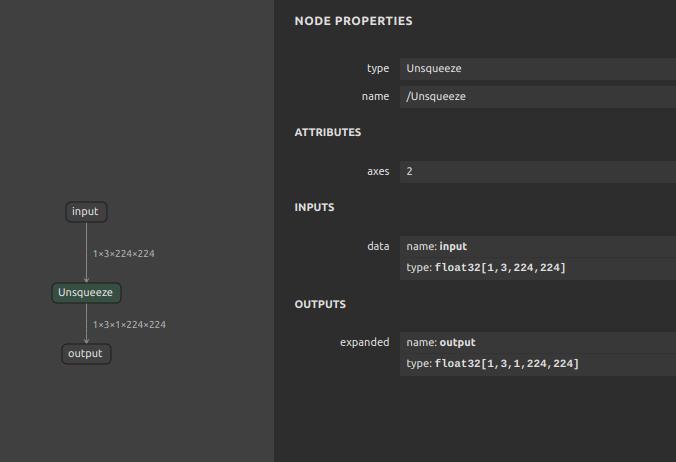
-
Unity Barracuda へ最適化した
Reshape(Unsqueeze) (opset=11)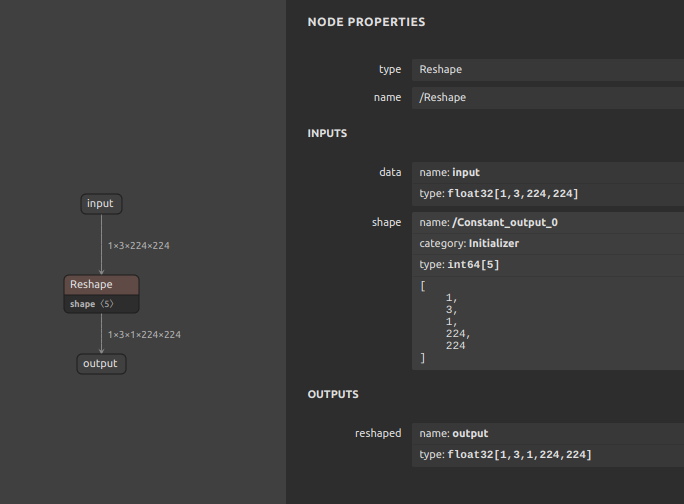
データベースの正規化と同じように、状況によってあえてほんの少しだけコードに冗長性を持たせるだけで、モデル全体の実用性が大幅に向上する例です。
8-5. onnx.onnx_cpp2py_export.shape_inference.InferenceError の回避
PyTorchからONNXを生成するときに、一見すると意味不明なエラー(コード上の表現が正しくPyTorchで正常に動作するもの)が発生することがあります。PyTorchあるいはONNXのバグなのか仕様なのかを判断することが難しいエラーです。例えば下記のようなエラーです。読みやすいように改行を加えています。
|
1 2 3 |
onnx.onnx_cpp2py_export.shape_inference.InferenceError: [ShapeInferenceError] (op_type:ReduceMax, node name: ReduceMax_4449): [ShapeInferenceError] Inferred shape and existing shape differ in rank: (4) vs (0) |
エラーが発生する箇所のコードは下記のとおりです。x には4次元のテンソルが入力されてくる想定です。特にこのエラー発生の原因になっている箇所は torch.max(input=x, dim=1)[0].unsqueeze(1) の部分なのですが一見すると意味合いの整合はとれています。指定された次元(dim)を軸にして最大値を抽出し、[0]でスライスして1つ目の出力を取得し、さらに1次元目を拡張する、というだけの処理です。注意点は、torch.max は2つの出力を得るという点で、戻り値が values と indicies のタプルになるということです。[0] は戻り値のタプルから values を抽出しています。
|
1 2 3 4 5 6 7 8 9 |
class ChannelPool(nn.Module): def forward(self, x): return torch.cat( ( torch.max(input=x, dim=1)[0].unsqueeze(1), torch.mean(input=x, dim=1).unsqueeze(1), ), dim=1, ) |
しかし、下記はエラーになりません。最終的な結果は上記の処理と全く同じですが、次元圧縮と次元展開の処理順序が異なるだけです。torch.max(x, dim=1, keepdim=True) の部分で keepdim=True を指定することで torch.max による次元圧縮を抑止したうえでスライスを施している点がことなります。つまり、Unsqueeze(1) を処理から排除しただけです。おそらく ONNX側の内部実装に問題があるではないか、と推察しています。
|
1 2 3 4 5 6 7 8 9 |
class ChannelPool(nn.Module): def forward(self, x): return torch.cat( ( torch.max(x, dim=1, keepdim=True)[0], torch.mean(x, dim=1, keepdim=True) ), dim=1, ) |
ここでご紹介したエラーはめったに発生しないからこそ、いざ発生したときに全く意味が分からなくて解消までに時間が掛かることがある特殊な問題です。onnx の内部実装を解析してプルリクエストを送ったほうが良いかもしれません。実際に気付いている人が居るのかどうかも分かりません。
8-6. PyTorch の Atan2 をONNXにエクスポートするワークアラウンド
ONNXには Atan の実装はありますが Atan2の実装がありません。
https://github.com/onnx/onnx/blob/main/docs/Operators.md#operator-schemas
したがって、Atan2 を使用している一部のモデルは何も手を加えない限りONNXへエクスポートすることができません。余談ですが、TensorFlow Lite には Atan2 の実装はありますが Atan の実装がありません。おそらく、少し手を加えるだけでオペレーションを表現できるためだとは思いますが、何故かどちらか一方しか実装されていないことがあります。本項では、PyTorchの Atan2 をONNXで表現します。
この実装は nikola-j/atan2.py をほぼそのまま引用させていただきました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
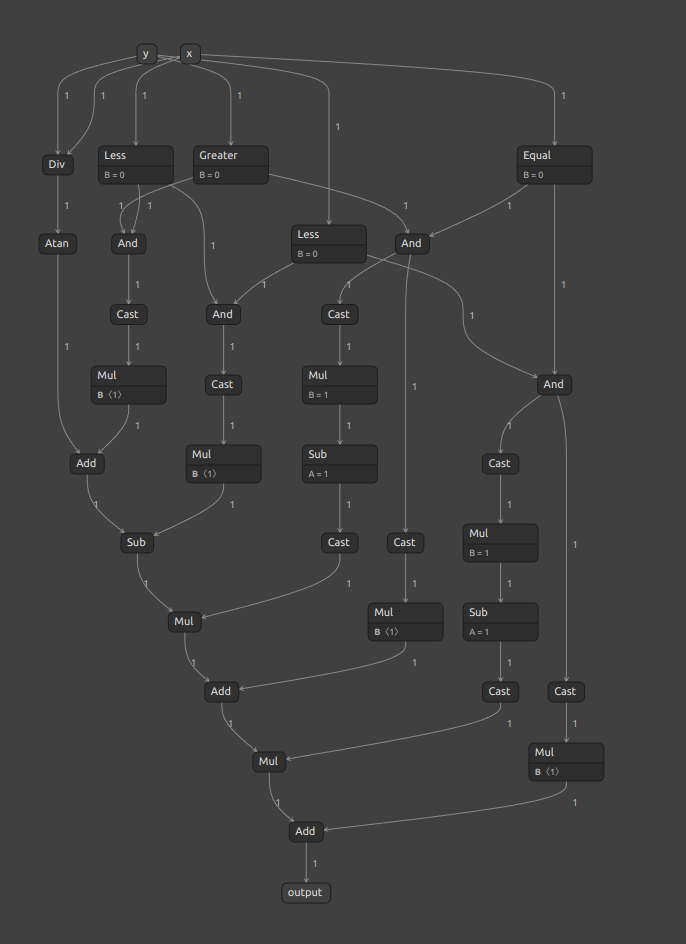
import torch import torch.nn as nn import numpy as np class Model(nn.Module): def __init__(self): super(Model, self).__init__() # cited: https://gist.github.com/nikola-j/b5bb6b141b8d9920318677e1bba70466 def forward(self, y, x): pi = torch.from_numpy(np.array([np.pi])).to(y.device, y.dtype) ret = torch.atan(y / x) ret += ((y > 0) & (x < 0)) * pi ret -= ((y < 0) & (x < 0)) * pi ret *= (1 - ((y > 0) & (x == 0)) * 1.0) ret += ((y > 0) & (x == 0)) * (pi / 2) ret *= (1 - ((y < 0) & (x == 0)) * 1.0) ret += ((y < 0) & (x == 0)) * (-pi / 2) return ret model = Model() x = torch.from_numpy(np.array([1.0])) y = torch.from_numpy(np.array([5.0])) onnx_file = f'Atan2_11.onnx' torch.onnx.export( model, args=(y, x), f=onnx_file, opset_version=11, input_names=[ 'y', 'x', ], output_names=[ 'output', ], ) import onnx from onnxsim import simplify model_onnx2 = onnx.load(onnx_file) model_simp, check = simplify(model_onnx2) onnx.save(model_simp, onnx_file) |
少々冗長ですが、下図のとおり Atan2 を表現できます。
8-7. PyTorch の torch.inverse をONNXにエクスポートするワークアラウンド
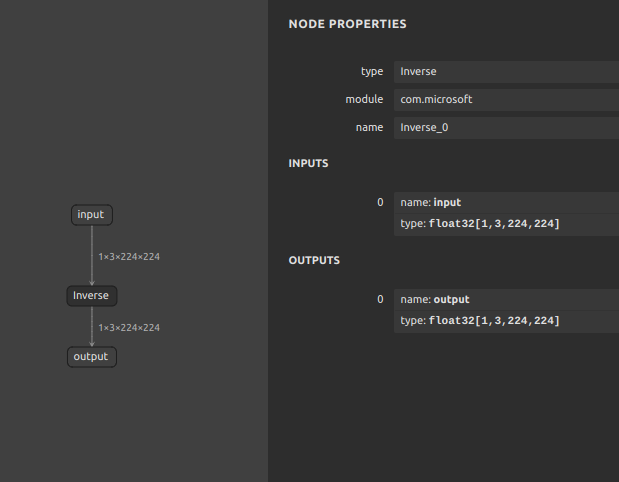
Transformer などのモデルで affine_grid が使用されているとき、何らかの方法で affine_grid を代替して再実装する必要があるのですが、計算を組み合わせていく過程で torch.linalg.inv あるいは torch.inverse を使用して逆行列を求めたいことがあります。しかし、ONNXの標準ランタイムには inverse が実装されていないため、inverse そのものをプリミティブなオペレーションへ分解して表現します。
先にお伝えしておくと、inverse が全く使えないわけではなくて、実際には com.microsoft という拡張モジュールを取り込めば利用できます。標準のランタイムにこだわる必要が無い場合は拡張モジュールを利用したほうが早いです。
-
https://pytorch.org/docs/stable/generated/torch.linalg.inv.html#torch.linalg.inv
-
正方行列になるまで再帰処理でひたすらテンソル分解して逆行列を求めるワークアラウンド
-
torch.linalg.detが正方行列にしか対応していない -
かなり冗長
参考:https://github.com/pytorch/pytorch/issues/30563
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768import torchimport torch.nn as nnfrom torch.linalg import detclass Model(nn.Module):def __init__(self):super(Model, self).__init__()def cof1(self, M, index):zs = M[:index[0]-1,:index[1]-1]ys = M[:index[0]-1,index[1]:]zx = M[index[0]:,:index[1]-1]yx = M[index[0]:,index[1]:]s = torch.cat((zs,ys),dim=1)x = torch.cat((zx,yx),dim=1)return det(torch.cat((s,x),dim=0))def alcof(self, M, index):return pow(-1, index[0]+index[1])*self.cof1(M, index)def adj(self, M):result = torch.zeros((M.shape[0], M.shape[1]))for i in range(1, M.shape[0]+1):for j in range(1, M.shape[1]+1):result[j-1][i-1] = self.alcof(M, [i,j])return resultdef forward(self, x):def _inverse_matrix_recursion(x):x_shape = x.shapex_rank = len(x_shape)if x_rank == 2:return torch.unsqueeze(1.0/det(x)*self.adj(x), dim=0)batched_tensor = []for splitted_tensor in x:batched_tensor.append(_inverse_matrix_recursion(splitted_tensor))return \torch.unsqueeze(torch.cat(batched_tensor,dim=0),dim=0,)return \torch.squeeze(_inverse_matrix_recursion(x), dim=0)model = Model()x = torch.randn([1,3,4,4], dtype=torch.float32)onnx_file = f'pseudo_invert_11_rank{len(x.shape)}.onnx'torch.onnx.export(model,args=(x),f=onnx_file,opset_version=11,input_names=['input'],output_names=['output'],)import onnxfrom onnxsim import simplifymodel_onnx2 = onnx.load(onnx_file)model_simp, check = simplify(model_onnx2)onnx.save(model_simp, onnx_file)もっと冗長性を排除したクリーンな実装方法があるかもしれませんが、
torch.linalg.detを使用した結果です。正方行列になるまで高次元を分解しますので、実質何次元でも逆行列化できますが、ロジックがとても単調なためOP数が増えてモデルが肥大化します。
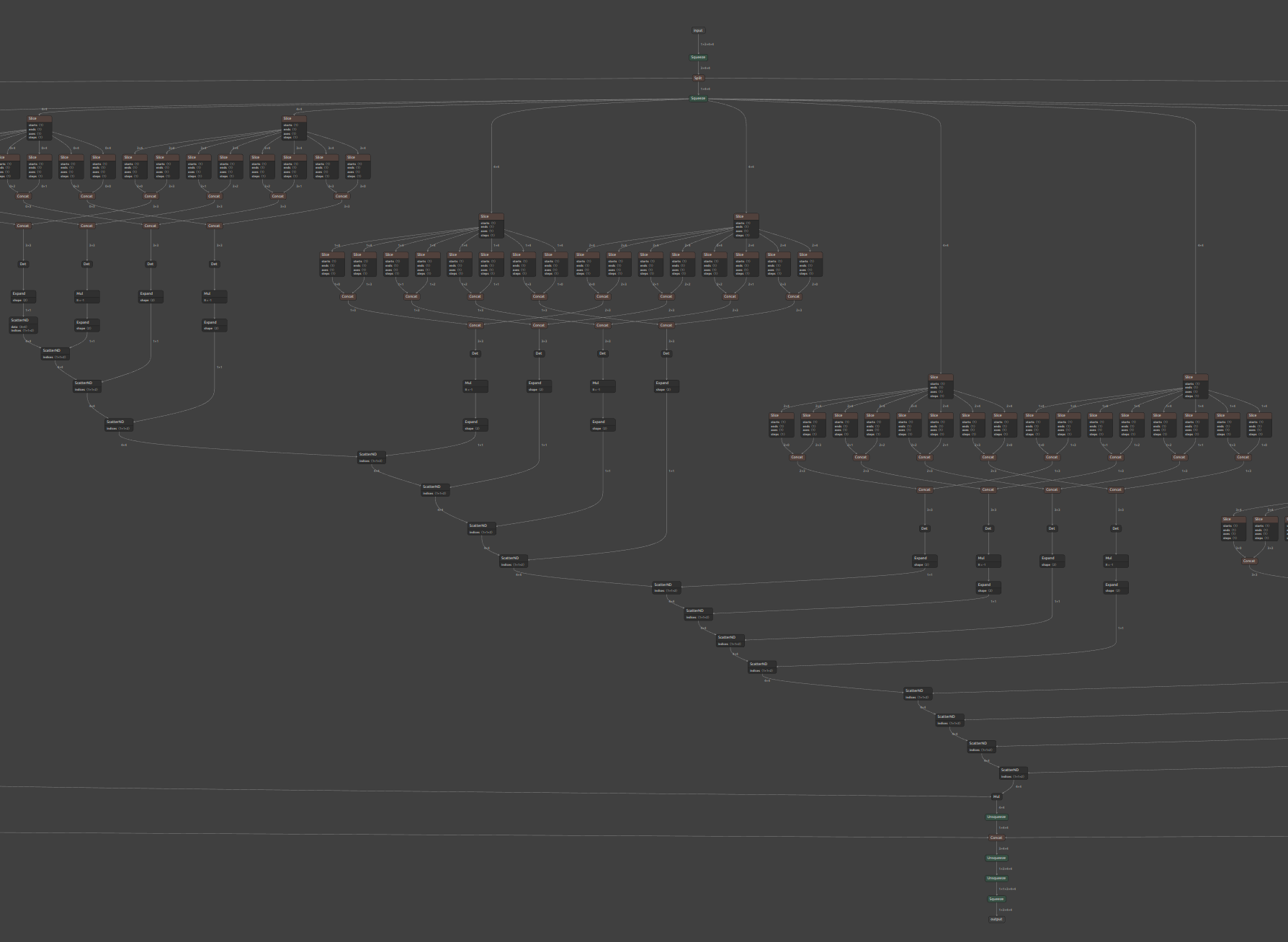
8-8. PyTorch の torch.median をONNXにエクスポートするワークアラウンド
PyTorchにはテンソルの中央値を求めるための torch.median というオペレーションが存在しますがONNXには実装されていません。したがって、torch.median を含むモデルをそのままONNXへエクスポートしようとすると下記のようなエラーが発生します。
|
1 2 3 4 5 6 7 8 9 |
Exporting the operator 'aten::median' to ONNX opset version 11 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues File "/home/xxxx/work/test/.vscode/make_median.py", line 31, in <module> torch.onnx.export( torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::median' to ONNX opset version 11 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues |
動作検証が不十分ですのでバグがあるかもしれませんが、torch.median をONNXへエクスポート可能なオペレーションの組み合わせに置き換えて下記のように表現します。テスト用のコードはあえて中央値を求める次元を偶数の次元にしていますので、中央値の判定の仕方に少しクセがあります。実装上は、mode を切り替えることで、ちょうど境目にある2つの要素のうち、大きい方を選択するか、小さい方を選択するか、2つの要素の平均を計算するか、を切り替えできるようにしているつもりです。
mode='ceil': 境目の2つの要素のうち大きいほうを選択mode='floor': 境目の2つの要素のうち小さいほうを選択mode='mean': 境目の2つの要素の平均値を計算
かなり回りくどい書き方をしていますが、なるべく Tensor型 で定数を保持しないようにしていることと、形状指定に -1 をできるだけ使用しないテクニックを再現しています。定数を再計算する箇所では torch.xxx() を使用せず、np.xxx() あるいは PythonのList型 を使用して Tensor型 に変換されないようにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 |
import random import torch import torch.nn as nn import numpy as np import onnxruntime as ort random.seed(0) np.random.seed(0) torch.manual_seed(0) class Model_normal_median(nn.Module): def __init__(self, dim): super(Model_normal_median, self).__init__() self.dim = dim def forward(self, x): values, indices = torch.median( input=x, dim=self.dim, keepdim=True, ) return values class Model_pseudo_median(nn.Module): def __init__(self, dim, mode): super(Model_pseudo_median, self).__init__() self.dim = dim self.mode = mode def forward(self, x): x_shape = [int(d) for d in x.shape] transpose_perm = None reverse_transpose_perm = None if len(x_shape) >= 2: transpose_perm = [ idx for idx in range(len(x_shape)) if idx != self.dim ] + [self.dim] reverse_transpose_perm = [ transpose_perm.index(idx) \ for idx in range(len(transpose_perm)) ] shape_before_compression = None shape_after_compression = None if len(transpose_perm) >= 2: transposed_x = x.permute(transpose_perm) transposed_x_shape = [ int(d) for d in transposed_x.shape ] shape_before_compression = \ transposed_x_shape[:-1] + [transposed_x_shape[-1]] shape_after_compression = [ np.prod(transposed_x_shape[:-1]) ] + [transposed_x_shape[-1]] else: transposed_x = x shape_before_compression = [ int(d) for d in transposed_x.shape ] shape_after_compression = [ int(d) for d in transposed_x.shape ] transposed_reshaped_x = torch.reshape( input=transposed_x, shape=shape_after_compression, ) l = transposed_reshaped_x.shape[-1] mid = l // 2 + 1 values, indices = torch.topk( input=transposed_reshaped_x, k=mid, dim=len(transposed_reshaped_x.shape) - 1, ) last_dim = [int(d) for d in values.shape][-1] median_1_idx = last_dim - 1 if last_dim >= 2 else last_dim median_2_idx = last_dim if last_dim >= 2 else last_dim if l % 2 == 1: median_values = values[:, median_1_idx:median_1_idx + 1] else: if self.mode == 'floor': median_values = values[:, median_1_idx - 1:median_1_idx] elif self.mode == 'ceil': median_values = values[:, median_2_idx - 1:median_2_idx] elif self.mode == 'mean': median_values = 0.5 * ( values[:, median_1_idx - 1:median_1_idx] \ + values[:, median_2_idx - 1:median_2_idx] ) reshaped_median_values = torch.reshape( input=median_values, shape=shape_before_compression[:-1] + [1], ) result = reshaped_median_values.permute(reverse_transpose_perm) else: x = torch.reshape(x, [-1]) l = x.shape[0] mid = l // 2 + 1 values, indices = torch.topk(x, mid) result = None if l % 2 == 1: result = values[-1] else: if self.mode == 'floor': result = values[-1] elif self.mode == 'ceil': result = values[-2] elif self.mode == 'mean': result = 0.5 * (values[-1] + values[-2]) return result x = torch.randn([4,5,6]) dim = 2 mode = 'ceil' normal_model = Model_normal_median(dim=dim) normal_output = normal_model.forward(x).numpy() pseudo_model = Model_pseudo_median(dim=dim, mode=mode) onnx_file = f'median_11_pseudo.onnx' torch.onnx.export( pseudo_model, args=(x), f=onnx_file, opset_version=11, input_names=[ 'input', ], output_names=[ 'output', ], ) import onnx from onnxsim import simplify model_onnx2 = onnx.load(onnx_file) model_simp, check = simplify(model_onnx2) onnx.save(model_simp, onnx_file) onnx_session = ort.InferenceSession( path_or_bytes=onnx_file, providers={ 'CUDAExecutionProvider', 'CPUExecutionProvider', }, ) pseudo_result = \ onnx_session.run( None, {'input': x.numpy()}, )[0] print( f'torch.median == pseudo_median: {np.allclose(normal_output, pseudo_result)}' |
最終次元で中央値を比較すると、PyTorchとONNXの出力値が一致しました。
|
1 |
torch.median == pseudo_median: True |
ONNXの形状は下図のとおりです。ArgMax で値の降順にソートしたテンソルを 要素数 // 2 + 1 個抽出し、抽出したテンソルからさらに末尾の要素、あるいは末尾からひとつ前の要素を抽出することで中央値を取得しています。6 // 2 + 1 = 4個。+1個を余分に抽出しているのは、mode='mean' のときに、境目にある2つの要素の平均を算出するために、境界をまたいだ2つ分の要素を抽出するためです。あえて回りくどい書き方をしたおかげで、Unsqueeze や Squeeze、Gather などの各種フレームワーク側で推論時に問題となるオペレーションを含めずに torch.median を表現できました。
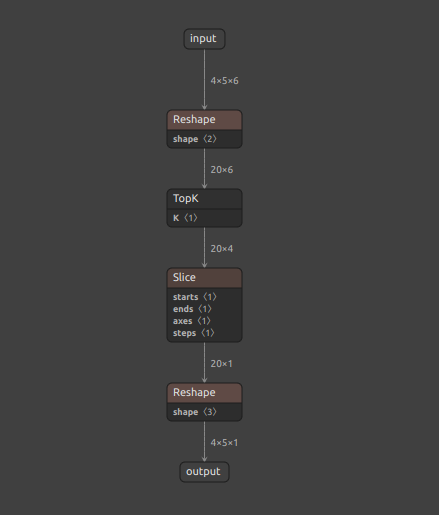
8-9. MVN (MeanVarianceNormalization) のワークアラウンド
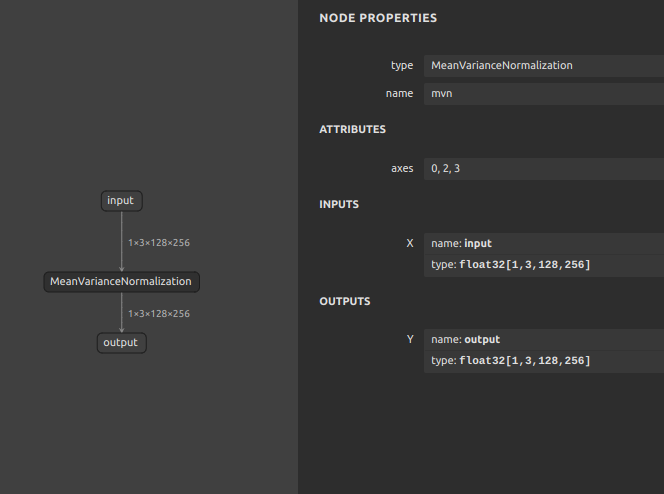
MeanVarianceNormalization は入力テンソルの平均-分散正規化を計算します。PyTorchそのものには MeanVarianceNormalization がオペレーションとして実装されていないように見えますが私の調査が足りていないだけかもしれません。少なくともONNXには MeanVarianceNormalization が実装されており、数式で表現してもあまり難しいものではありませんので、オペレーションそのものを利用することにあまり固執する必要は無いかもしれません。
https://github.com/onnx/onnx/blob/main/docs/Changelog.md#MeanVarianceNormalization-13
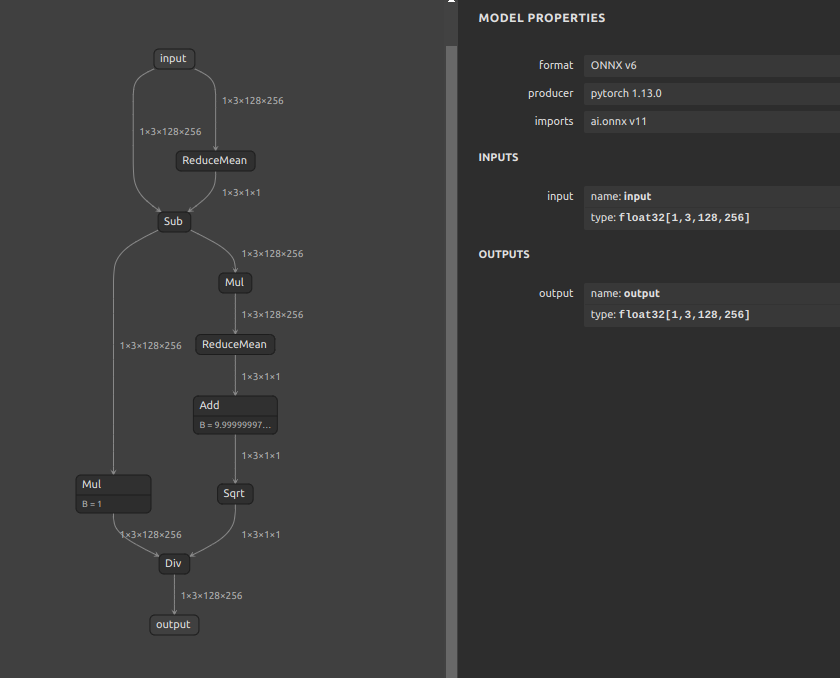
下記のように実装しました。今回もとても回りくどい実装をしています。PyTorchのひとつのオペレーションで処理できる部分をあえて分解して個別に実装しています。特に意味が無いことをすぐに見つけることができる部分は (reduce_sub * 1.0) の * 1.0 の箇所だと思いますが、実はこれには意味があります。まず、MeanVarianceNormalization が実装されているフレームワーク上でしか MeanVarianceNormalization を持つモデルを実行できないことは当然ですが、あえて MeanVarianceNormalization をプリミティブに近いオペレーションの組み合わせに分解して再実装することでほとんどのフレームワーク上で実行可能になります。また、仮にONNXのモデルに MeanVarianceNormalization が含まれているときにそのまま他のフレームワークへ変換すると MVN という名前の等価なオペレーションへそのまま変換されることが多いです。たとえば、ONNXからOpenVINOへ変換するとモデルオプティマイザが自動的に MVN へ置き換えて処理を最適化してくれます。ただ、MeanVarianceNormalization に対応していないフレームワークがその先の変換作業の工程にひとつでも存在するとその時点でモデルの汎用性が著しく低下します。したがって、各種フレームワークのモデルオプティマイザが優秀な最適化性能を持つことを逆手に取って、無意味な演算(計算値に影響を与えない演算)を加えて MeanVarianceNormalization が自動生成されないようにフォローしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
import torch import torch.nn as nn import numpy as np import onnxruntime as ort from sog4onnx import generate onnx_file1 = f'mvn_13_single_op.onnx' single_op_graph = generate( op_type = 'MeanVarianceNormalization', opset = 13, op_name = "mvn", input_variables = { "input": [np.float32, data_shape], }, output_variables = { "output": [np.float32, data_shape], }, attributes = { "axes": [0,2,3], }, non_verbose = True, output_onnx_file_path = onnx_file1 ) class Model(nn.Module): def __init__(self, dim, epsilon): super(Model, self).__init__() self.dim = dim self.epsilon = epsilon def forward(self, x): reduce_mean = torch.mean( input=x, dim=self.dim, keepdim=True, ) reduce_sub = x - reduce_mean reduce_varriance = torch.mean( torch.square(reduce_sub), dim=self.dim, keepdim=True, ) return (reduce_sub * 1.0) / torch.sqrt(reduce_varriance + self.epsilon) data_shape = [1,3,128,256] x = torch.randn(data_shape) mvn_model = Model(dim=[0,2,3], epsilon=1e-6) onnx_file2 = f'mvn_11.onnx' torch.onnx.export( mvn_model, args=(x), f=onnx_file2, opset_version=11, input_names=[ 'input', ], output_names=[ 'output', ], ) import onnx from onnxsim import simplify model_onnx2 = onnx.load(onnx_file2) model_simp, check = simplify(model_onnx2) onnx.save(model_simp, onnx_file2) onnx_session1 = ort.InferenceSession( path_or_bytes=onnx_file1, providers={ 'CUDAExecutionProvider', 'CPUExecutionProvider', }, ) mvn_single_op_result = \ onnx_session1.run( None, {'input': x.numpy()}, )[0] onnx_session2 = ort.InferenceSession( path_or_bytes=onnx_file2, providers={ 'CUDAExecutionProvider', 'CPUExecutionProvider', }, ) mvn_result = \ onnx_session2.run( None, {'input': x.numpy()}, )[0] print( f'torch.median == pseudo_median: {np.allclose(mvn_result, mvn_single_op_result)}' ) |
通常の MeanVarianceNormalization です。
左側の分岐の Mul が各フレームワークへ横展開するうえで有効になるワークアラウンドの * 1 の箇所です。これだけでフレームワークの推論エラーを一部回避できるようになります。全体の動作は MeanVarianceNormalization と同じです。出力値は一致します。
念の為それぞれの実装でベンチマークしてみます。結果は下記のとおりです。MeanVarianceNormalization 単体の実装のほうが推論速度が数倍速いですがフレームワーク間の汎用性は低いです。
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_13_single_op.onnx -oep tensorrt INFO: file: mvn_13_single_op.onnx INFO: providers: ['TensorrtExecutionProvider', 'CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 0.6437301635742188 ms INFO: avg elapsed time per pred: 0.06437301635742188 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_13_single_op.onnx -oep cuda INFO: file: mvn_13_single_op.onnx INFO: providers: ['CUDAExecutionProvider', 'CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 0.6847381591796875 ms INFO: avg elapsed time per pred: 0.06847381591796875 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_13_single_op.onnx -oep cpu INFO: file: mvn_13_single_op.onnx INFO: providers: ['CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 0.9531974792480469 ms INFO: avg elapsed time per pred: 0.09531974792480469 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
分解した MeanVarianceNormalization のベンチマーク結果です。何故か TensorRT による推論が異様に遅いです。また、CPU推論が異様に速いです。なお、フレームワーク間での汎用性は高めです。
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_11.onnx -oep tensorrt INFO: file: mvn_11.onnx INFO: providers: ['TensorrtExecutionProvider', 'CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 3.3321380615234375 ms INFO: avg elapsed time per pred: 0.33321380615234375 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_11.onnx -oep cuda INFO: file: mvn_11.onnx INFO: providers: ['CUDAExecutionProvider', 'CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 1.9333362579345703 ms INFO: avg elapsed time per pred: 0.19333362579345703 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
|
1 2 3 4 5 6 7 8 9 |
sit4onnx -if mvn_11.onnx -oep cpu INFO: file: mvn_11.onnx INFO: providers: ['CPUExecutionProvider'] INFO: input_name.1: input shape: [1, 3, 128, 256] dtype: float32 INFO: test_loop_count: 10 INFO: total elapsed time: 1.5482902526855469 ms INFO: avg elapsed time per pred: 0.1548290252685547 ms INFO: output_name.1: output shape: [1, 3, 128, 256] dtype: float32 |
8-10. TopDown 骨格推定モデルのバッチ処理化ワークアラウンド
TopDown アプローチの骨格推定モデルに関するワークアラウンドです。TopDownの骨格推定モデルは、まず1段階目で物体検出モデルなどを使用して人物のエリアをクロップし、2段階目でクロップした人物エリアの画像に対して骨格推定を行うアプローチです。つまり、ひとつの画角に10人の人物が映っている場合は、物体検出された人物画像10人分を TopDown アプローチの骨格推定モデルに入力して利用します。特に難しいアプローチではなく、人物の身体特徴に合わせて Batch x Channel x Height x Width = 1 x 3 x 256 x 128 のような縦長の入力解像度が設定されていることが多いモデル群です。
モデル設計のアプローチ自体には問題がありません。しかし先述したとおり、物体検出で複数人、なおかつ撮影する映像によっては何人検出されるかが分からない状況でバッチサイズを予め固定したモデルを使用すると、無意味なゼロ埋めデータでパディングして推論する必要があるため推論パフォーマンスを最大化できないばかりか、無用なパディングロジックを記述する必要が生じるため処理が少しだけ冗長になります。例えば、最大10人を検出できるように 10 x 3 x 256 x 128 としてしまった場合、画角内に1人の人物しか映っていなくても不足する9人分の無意味なゼロパディングデータを追加して推論する必要がありますのでとても非効率です。フレームワーク側が可変バッチサイズによる推論に対応している場合(一部のエッジデバイス向けフレームワークを除いて直近の1年でほとんどのフレームワークが対応しました)はバッチサイズを可変サイズのままにしてモデルを生成しておき、必要な画像枚数だけを推論に掛けたいです。
一例として、こちらでプルリクエストを取り込んで頂き、MMPose の動作を変更しました。実装上、とても特別な配慮が必要な内容ではありません。
https://github.com/open-mmlab/mmpose/pull/1242
PyTorchからONNXへモデルをエクスポートする時点で動的サイズを指定できることはご存知だと思いますが、バッチサイズを可変にするにあたって注意しなければいけないポイントがあります。それは、モデルの中間部分のオペレーションにバッチサイズ以外の次元に -1 で形状指定された Reshape が含まれる場合に多くのフレームワークで可変バッチによる推論ができなくなることです。正確には、1次元目のバッチサイズにあたる部分に可変形状を指定できなくなるため、無理やりバッチサイズを可変形状に書き換えるとモデルが破損します。例えば、[-1, -1, 64, 48] のような状況になることを指します。下図は、バッチサイズを可変形状に書き換える前の Reshape の動作を示していますが、仮にこのバッチサイズにあたる1次元目を -1 に書き換えた場合、[-1, -1, 64, 48] となり、推論時にテンソルの形状を正しく推定できなくなりランタイムがAbortします。これはどのフレームワークでも共通の動作です。
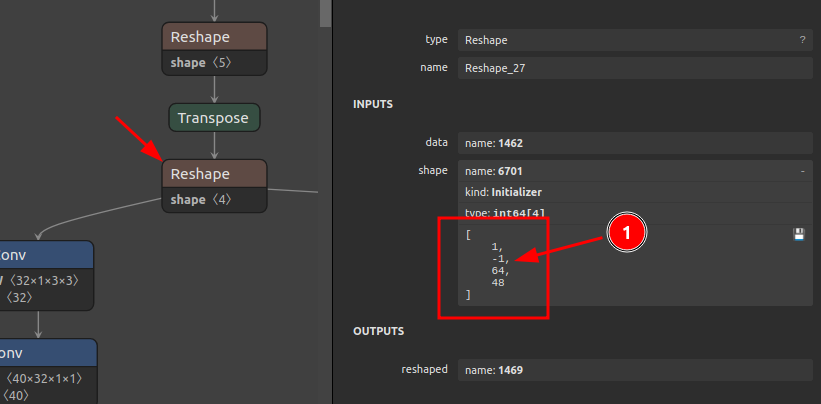
したがって、下図のとおり Reshape の動作を変更します。これは、PyTorchでモデルを設計する時点で実用性を向上させる観点での配慮が必要な事項です。
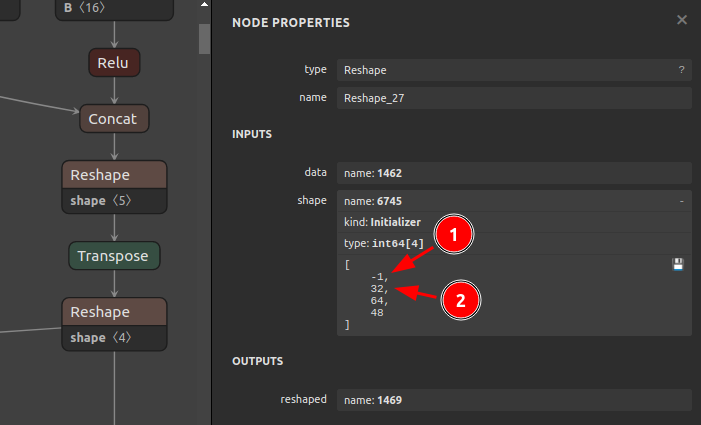
モデル設計上の修正点は下記のとおりで承認いただけました。
-
From:
12345channels_per_group = num_channels // groupsx = x.view(batch_size, groups, channels_per_group, height, width)x = torch.transpose(x, 1, 2).contiguous()x = x.view(batch_size, -1, height, width)To:
12345channels_per_group = num_channels // groupsx = x.view(batch_size, groups, channels_per_group, height, width)x = torch.transpose(x, 1, 2).contiguous()x = x.view(batch_size, groups * channels_per_group, height, width)
モデルを実際に実戦投入して利用することを想定する場合は、サイズが自明な次元には必ず定数値でサイズ指定していただくようにしたほうが良いと感じています。
8-11. 入力テンソルのサイズが大きめの ArgMax のEdgeTPU対応とTensorRT対応と推論速度向上のワークアラウンド
背景透過などの用途でセグメンテーションモデルを利用されている方々がいらっしゃるかもしれません。世の中に出回っているセグメンテーション系のモデルはどんどん高性能化しており、最近ではかなり綺麗に背景透過ができるようになってきています。ただ、セグメンテーションモデルは全体的に処理負荷が高いものが多く、スペックが高めのマシンを使用することを前提として設計されていることが多いです。仮に、セグメンテーションモデルをロースペックなデバイスで利用しようとした場合に課題・問題となる点は下記のとおりです。
- セグメンテーションモデルの後処理をモデルの最後尾にマージしてピクセル単位でクラス分類が終わった状態で最終出力を得たい
- クラス分類をするとなると
ArgMaxを使用したいが、ArgMaxの処理負荷が高く推論速度が非常に遅い - バッファが小さいデバイスでは
ArgMaxを内部処理しきれず Abort してしまうことがある
そもそも、ArgMax の処理が遅いという話は昔からある内容ですので、これからご紹介するようなトリックを使用しない限りは上記の問題をクリアできません。では、どのように問題を小さくするかという点を以下にご紹介します。
FusedArgMax という仕組みをモデルに導入します。ArgMax に入力するテンソルのサイズをできる限り小さく押さえて演算し、ArgMax から出力されたテンソルをもともと必要としていたサイズへリサイズします。ものすごく単純ですね。
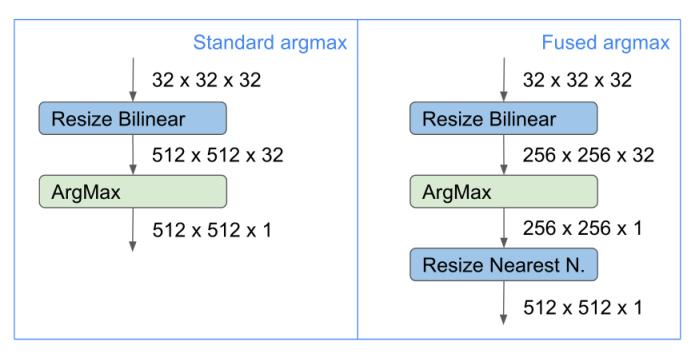
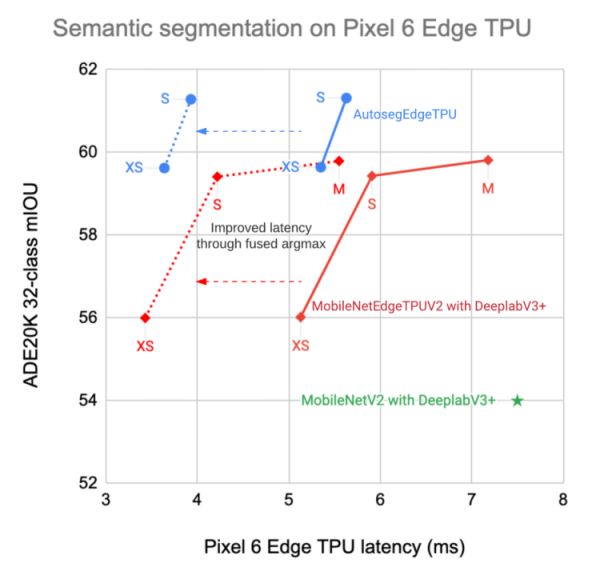
ArgMax にテンソルを入力する時にフルサイズの解像度で入力するのではなく、一定比率のスケールへ縮小した状態で処理したあとに、ふたたび本来のスケールへリサイズしています。元の入力解像度が 512x512 でリスケール後の解像度が 256x256 だとした場合、要素数にして 2,097,152 個分の要素の演算を削減できます。スマートフォンの Pixel6 での推論パフォーマンスがおよそ2倍に向上しています。実装上は例えば、torch.nn.functional.interpolate の拡大率を調整するだけの簡単なカスタマイズでパフォーマンスを向上できます。
8-12. Korniaの最適化(rgb_to_ycbcr, ycbcr_to_rgb)
Kornia にはPyTorchで利用可能な便利なオペレーションが多数用意されています。その中でも画像処理で利用されることのある YCbCr 変換に関する処理を取り上げたいと思います。なお、モデルの精度向上などの観点ではなく色変換をする際の処理の書き方による汎用性の変化についてのみフォーカスします。
まずは、Kornia の公式実装の ycbcr_to_rgb です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
y: Tensor = image[..., 0, :, :] cb: Tensor = image[..., 1, :, :] cr: Tensor = image[..., 2, :, :] delta: float = 0.5 cb_shifted: Tensor = cb - delta cr_shifted: Tensor = cr - delta r: Tensor = y + 1.403 * cr_shifted g: Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted b: Tensor = y + 1.773 * cb_shifted return torch.stack([r, g, b], -3) |
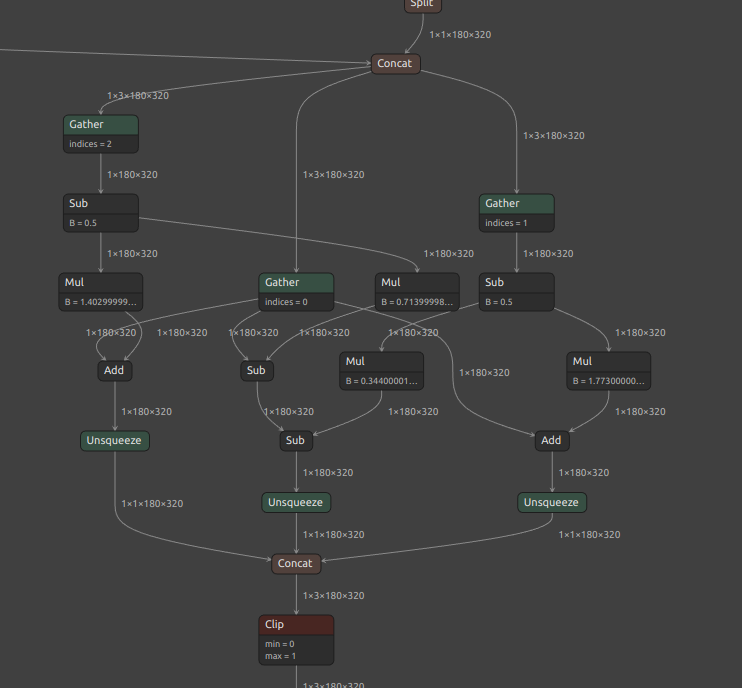
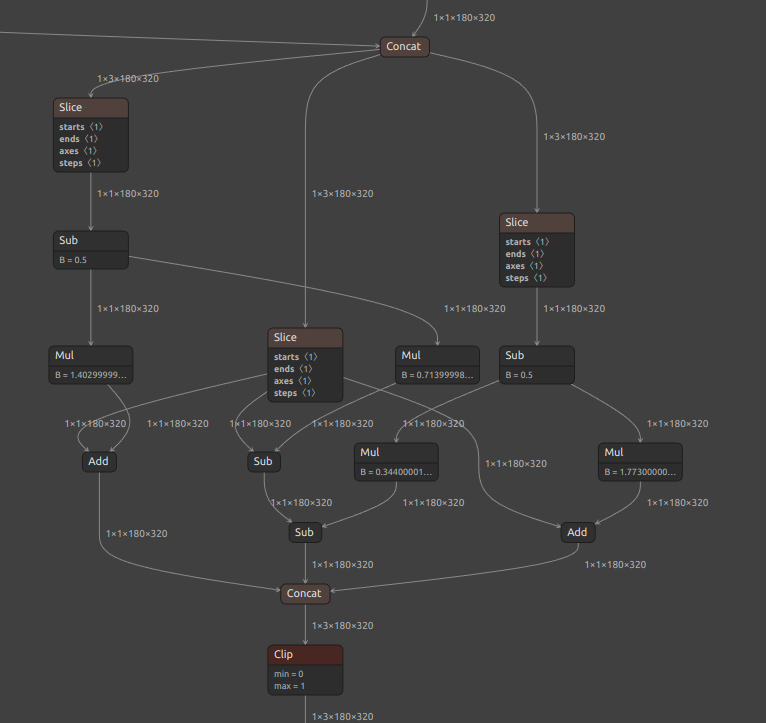
次に、少しだけ Kornia の実装を改造した ycbcr_to_rgb です。ほとんど公式実装と差がありませんので無意味な修正に感じるかもしれません。公式実装の Gather が Slice に置き換わり、スライスしたチャンネルの次元が保持されています。また、公式実装のモデルの最後方の Unsqueeze が全て消失しています。つまりたったこれだけで、Unsqueeze が無くなったことでフレームワーク間の転用がしやすくなったということです。ちなみに、モデル最後尾の ycbcr_to_rgb の部分のみをクローズアップしていますが、モデルの入口の部分には逆の変換の rgb_to_ycbcr が存在するため、合計で6個の Unsqueeze を消失させることができます。モデルを設計・変換する際には、できるだけ次元の圧縮を伴う Gather を使用するのではなく、次元の圧縮を伴わない Slice を使用したほうがモデル全体の構造を綺麗にすることができます。これは、モデルの構造が大きくなればなるほどインパクトが大きくなります。Korniaにプルリクエストをすればいいじゃないか、と思う方がいらっしゃるかもしれませんが、しません。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
y: torch.Tensor = image[..., 0:1, :, :] cb: torch.Tensor = image[..., 1:2, :, :] cr: torch.Tensor = image[..., 2:3, :, :] delta: float = 0.5 cb_shifted: torch.Tensor = cb - delta cr_shifted: torch.Tensor = cr - delta r: torch.Tensor = y + 1.403 * cr_shifted g: torch.Tensor = y - 0.714 * cr_shifted - 0.344 * cb_shifted b: torch.Tensor = y + 1.773 * cb_shifted return torch.cat([r, g, b], 1) |
他にもまだ様々なトリックがありますが、終わらなくなるためここで止めます。
9. ONNXから各種フレームワーク向けモデルへの変換
PyTorchからONNXを生成できてさえいれば、あとはどのフレームワークへも期待通りの形式で簡単に変換することができます。主要な機械学習フレームワーク用、ランタイム用のモデルフォーマットへの変換方法を簡単にご紹介します。既出の情報を含みますが、あらためて一気通貫で全部記載します。
9-1. TensorFlow
onnx2tf を使用します。2022年09月に開発を始めた自作ツールですが、最初から他のフレームワークへモデルを転用することを想定した設計にしていますので、現時点ではRNNに対応していないことを除いて最も変換効率が高いです。基本構文は下記です。オプションを何も指定せずに変換すると、 TFLite のモデルが生成されます。
|
1 2 3 4 |
docker run --rm -it \ -v `pwd`:/workdir \ -w /workdir \ ghcr.io/pinto0309/onnx2tf:1.7.21 |
|
1 |
onnx2tf -i xxxx.onnx |
メタデータなども含めて saved_model を出力する場合は下記の通りです。主に saved_model を他のフレームワーク向けに変換するために使用します。
|
1 |
onnx2tf -i xxxx.onnx -osd |
Keras の .h5 形式で出力する場合は下記のとおりです。
|
1 |
onnx2tf -i xxxx.onnx -oh5 |
Keras の keras_v3 形式で出力する場合は下記のとおりです。
|
1 |
onnx2tf -i xxxx.onnx -okv3 |
MS-COCO データセットのサンプルデータ 20件 を使用して自動キャリブレーションとINT8量子化を行う場合は下記のとおりです。デフォルト動作は per-channel の量子化です。
|
1 |
onnx2tf -i xxxx.onnx -oiqt |
per-tensor の量子化を行う場合は下記のとおりです。
|
1 |
onnx2tf -i xxxx.onnx -oiqt -qt per-tensor |
オペレーションごとの変換前後の推論誤差を計測する場合は下記の通りです。
|
1 |
onnx2tf -i xxxx.onnx -cotof -cotoa 1e-3 |
下図GIFのように、全てのオペレーションに対してONNXと変換後のTensorFlowの推論誤差を計測して表示します。主にモデル変換時のデバッグに使用します。

TFLite のバイナリを書き換えて、ONNXの入出力名と入出力オーダーにTFLiteの入出力名と入出力オーダーを合わせることができます。ただし、私が独自にカスタマイズした flatbuffers-compiler を導入する必要があります。上記のDocker環境内にはすでに導入済みです。
https://github.com/PINTO0309/onnx2tf#environment
|
1 |
onnx2tf -i xxxx.onnx -coion |
flatbuffers-compiler の改造内容を知りたい方はこちらをご覧ください。コンパイラが生成する量子化値の算術精度不足を一部だけ解消しています。
https://github.com/PINTO0309/onnx2tf/issues/196
その他にも、FlexOP を無効化するオプションや疑似オペレーションを生成するオプション、 Transpose を指定した次元数まで分解するオプションやこのブログでご紹介した Fused ArgMax を組み込むオプションなど、様々なオプションが用意されていますので気になる方は README をご覧ください。
9-2. TensorFlow.js
昔からある方法ですので今更細かくはご紹介しません。上記の onnx2tf で -osd を指定して生成した saved_model を使用して生成可能です。
|
1 |
pip install tensorflowjs |
|
1 2 3 4 5 |
tensorflowjs_converter \ --input_format tf_saved_model \ --output_format tfjs_graph_model \ saved_model \ tfjs_model |
9-3. TensorRT
trtexec というTensorRTに付属するコンバーターを使用するか、ONNX の TensorRT ExecutionProvider で推論開始時に自動変換します。匠要素は少ないですが後者のほうが簡単です。手抜きをするならば、sit4onnx という本ブログのベンチマークで使用していたツールを実行するだけで trtengine を自動生成することができます。
|
1 2 3 |
docker run --rm -it --gpus all \ -v $PWD:/home/user/workdir \ pinto0309/ubuntu2004-cuda11.6-cudnn8.6-tensorrt8.5.3:latest |
|
1 |
sit4onnx -if xxxx.onnx -oep tensorrt |
推論コードは下記です。Dockerの中で実行すれば TensorRT で動作確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import onnxruntime providers = [ ( 'TensorrtExecutionProvider', { 'trt_engine_cache_enable': True, 'trt_engine_cache_path': '.', 'trt_fp16_enable': True, } ), 'CUDAExecutionProvider', 'CPUExecutionProvider', ] onnx_session = onnxruntime.InferenceSession( path_or_bytes='xxxx.onnx', providers=providers, ) input_name = onnx_session.get_inputs()[0].name input_shape = onnx_session.get_inputs()[0].shape results = \ onnx_session.run( None, {input_name: np.ones(input_shape, dtype=np.float32)}, ) print(f'results[0].shape: {results[0].shape}') |
9-4. CoreML
私は iPhone ユーザーではありませんので生成された CoreML モデルの動作確認をすることができませんが、下記でモデルを変換可能です。
|
1 |
pip install coremltools |
https://coremltools.readme.io/docs/unified-conversion-api
|
1 2 3 4 5 6 7 8 9 10 |
import coremltools as ct # Convert saved_model to Core ML FOLDER_PATH = 'saved_model' model = ct.convert( model=FOLDER_PATH, source='tensorflow', ) model.save(f'{FOLDER_PATH}/model.mlmodel') |
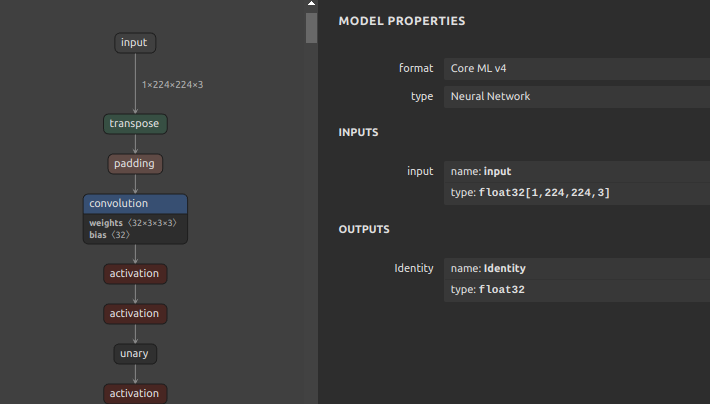
なお、NCHW形式のCoreMLモデルを生成したい場合は onnx2tf を実行する際に -k オプションを使用して下記のとおり処理します。
|
1 |
curl -LO https://github.com/PINTO0309/onnx2tf/releases/download/1.1.28/mobilenetv2-12.onnx |
-
ONNX
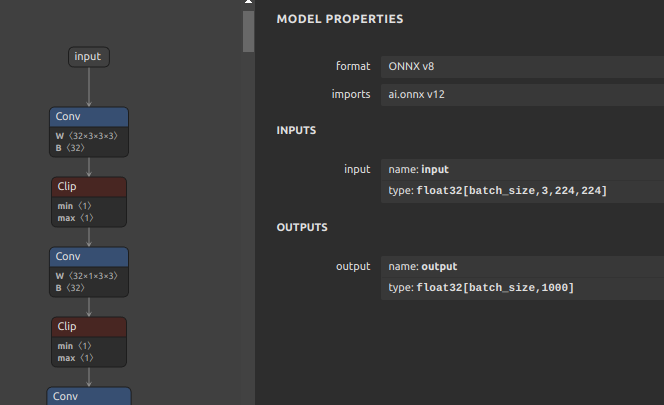
-k オプションはONNXの入力OPの形状を維持するようにツール動作を変更します。-ois オプションは入力形状を指定した静的形状へ上書きします。
|
1 |
onnx2tf -i mobilenetv2-12.onnx -k input -ois input:1,3,224,224 -osd |
|
1 2 3 4 5 6 7 8 9 10 |
import coremltools as ct # Convert saved_model to Core ML FOLDER_PATH = 'saved_model' model = ct.convert( model=FOLDER_PATH, source='tensorflow', ) model.save(f'{FOLDER_PATH}/model.mlmodel') |
-
CoreML
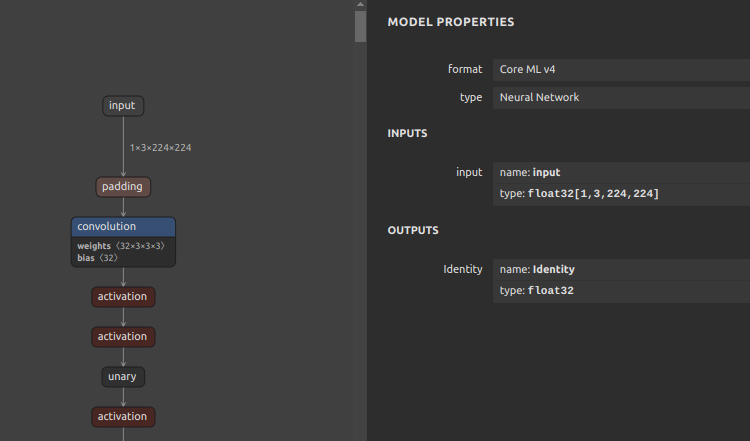
9-5. OpenVINO
OpenVINO 2022.3 が手元の環境にインストールされている前提での変換コマンドは下記です。つまづく要素がありません。なお、さらに OAK-D (Myriad) に対応した形式へコンバートする場合は、ONNXの生成時点でMyriad用の多くのワークアラウンドが必要となることがあります。
|
1 |
mo --input_model xxxx.onnx |
X. おわりに
少々長くなりましたが、ONNXのモデルチューニングテクニック (応用編2) は以上です。これでチューニングテクニックシリーズは完結とします。
Author