Blog
GraphDBを検証してみたら予想よりも辛かった
アドテク本部の成尾です。
今回、GraphDBについて検証したので少しでも参考になればと思い公開してみます。
経緯
とあるプロダクトでOrientDBのCommunity Editionを利用しているのですが
Writeの性能が予想よりも出ていない事、新しい製品も数多く出てきている事から
検証をしてほしいという声があがり検証する事となりました。
GraphDB
Graphとは、VertexとEdgeで構成されます。
多くのGraphDBは、上記のVertex, EdgeにPropertyを保持できるProperty Graphを扱います。
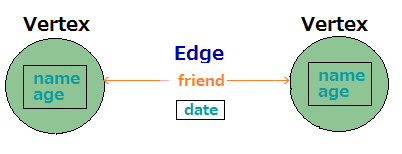
例えば
Vertexとして人
VertexのPropertyとしてその人の名前や年齢を持ち
それぞれの人がfriendという関係のEdgeで相互につながっていて
EdgeのPropertyとして知り合った日を持っているという関係性を保持する場合以下のようになります。
GraphDBの詳しい説明については
検索して頂くと詳しくスライドを公開されている方もいるのでそちらを参考にして頂ければと思います。
検証候補
・Dgraph https://dgraph.io/
・JanusGraph http://janusgraph.org/
・GRAKN.AI https://grakn.ai/
・CAYLEY https://cayley.io/
候補絞込
まず最近出ていている製品、注目度が高いものを含めて出したのが候補です。
ここで性能を比較するための負荷テストツールを探していったのですが、全くもって見つかりません。
それぞれが独自仕様で作らている事が多く、汎用的に使えるものを見つける事ができませんでした。
そこでまずは上がっていた各製品をインストールし触ってみると共に
それぞれのアーキテクチャに注目しました。
Dgraph
・クエリ言語: GraphQL+- (FacebookのGraphQLベースの独自言語)
・ストレージ: Badger(Go言語製のKVS)を利用(過去のVersionではRocksDBを採用していた)
・その他: スキーマフリー
JanusGraph
・クエリ言語: Gremlin
・ストレージ: Cassandra, HBase, Google Cloud Bigtable, BerkeleyDB, In-memory
・その他: CacheとしてElasticSearchが利用可能
GRAKN.AI
・クエリ言語: Graql
・ストレージ: Cassandra
・その他: kafka, zookpeerが使われている
CAYLEY
・クエリ言語: JavaScript (gremlin-inspired), MQL
・ストレージ: LevelDB, Bolt, PostgreSQL, MongoDB, In-memory, ephemeral
・その他: 公式では上記ストレージが書かれているが、github側ではCockroachDB, MySQLも利用できると書かれている
まず、最近出てきたものはDashboardがあり、ちょっとしたクエリを流す時など使いやすい反面
独自のクエリ言語を利用しているところが多い印象があります。
また、これは私達の都合でもりますが、Badger(KVS)やCockroachDBなど、運用経験がないものもあり不安がありました。
過去安定して動作し、スレーラビリティを考えるとCassandraが利用できる点
現在利用しているOrientDBと同じくTinkerpopフレームワークを採用している点
Titanの後継にあたりJanusGraphとしては新しいが信頼性は高そうという事もあり
JanusGraphに絞って現在のOrientDBとの比較を行うことになりました。
(GRAKN.AIもTinkerpopを採用しCassandraが利用できるのですがクエリ言語の面等含め見送りました)
テスト方法
ここでGremlin言語が使える事から何かいい方法がないか探したところ
Tinkerpop version3系ではbenchmark関数が使える事からこちらを利用したCPU実行時間を元に比較する事にしました。
http://tinkerpop.apache.org/docs/current/reference/#benchmarking-and-profiling
検証環境
弊社ではプライベートクラウドとしてOpenStackを採用しているので
そちらの環境を利用して以下のインスタンスタイプで環境を作成しました。
また、OrientDBはストレージを内包している分動かす台数に差を付け
最終的なコア数が近くなるよう調整しています。
OrientDB
CPU: 8core x 5
Memory: 28GB
OS: CentOS Linux release 7.3.1611
OrientDB Version: orientdb-community-tp3-3.0.0m2
OrientDBでTinkerpop version3以降を使えるVersionが3.0.0系しかなく
Stableではないのですが今回比較用に採用しました。
Janus Graph
CPU: 8core x 3
Memory: 28GB
OS: CentOS Linux release 7.3.1611
JanusGraph Version: janusgraph-0.1.1-hadoop2
Cassandra
CPU: 4core x 3
Memory: 14GB
OS: CentOS Linux release 7.3.1611
JanusGraph Version: cassandra20-2.0.17-1.noarch
ストレージにCassandraが利用できますが
Version3系では動かないため、Version2系を利用しました。
ElasticSearch
CPU: 2core x 3
Memory: 7GB
OS: CentOS Linux release 7.3.1611
JanusGraph Version: elasticsearch-1.5.2-1.noarch
ElasticSearchは新しいVersionでは動かないため
動くVersionのうち最新のものを利用しました。
テストデータ
現在OrientDBを利用しているステージング環境(Tinkerpop 2系)のテストデータを利用して動かす事にしました。
OrientDB
ここでは軽くコマンド例だけの紹介になりますが
以下のようにTinkerpop 2系のデータをExportして単純にImportするだけでは
データの形式やLabelまわり、INDEXなどで問題があったので
実際には、2系でExport, 3系でImport、3系でExport、rubyで書いたScriptで書き換え、
事前のClass定義と3系でImportなど色々処理をしています。
コードに関しては一部 – でマスクし、一部のみ抜粋して載せています。
Tinkerpop 2系でのExport
|
1 2 |
graph = new OrientGraph("remote:localhost:12424/--------", "----", "---------------"); GraphSONWriter.outputGraph(graph,'/tmp/--------.json',GraphSONMode.EXTENDED) |
Tinkerpop 3系でのTinkerpop2形式データのImport
|
1 2 3 |
graph = OrientGraph.open("remote:localhost/poc"); r = LegacyGraphSONReader.build().create() r.readGraph(new FileInputStream('/tmp/-----------.json'), graph) |
Tinkerpop 3系でのExport
|
1 2 |
graph = OrientGraph.open("remote:localhost/poc"); graph.io(IoCore.graphml()).writeGraph("/tmp/------------.json"); |
JanusGraph
こちらは上記検証用のOrientDBにデータを利用し、Exportしたデータを以下のようにImportして完了です。
Tinkerpop 3系でのImport
|
1 2 |
graph = JanusGraphFactory.open('/root/janusgraph-0.1.1-hadoop2/conf/poc.properties') graph.io(IoCore.graphson()).readGraph("/tmp/--------.json"); |
JanusGraphでのINDEX作成
|
1 2 3 4 5 6 7 |
graph = JanusGraphFactory.open('/root/janusgraph-0.1.1-hadoop2/conf/poc.properties') graph.tx().rollback() mgmt = graph.openManagement() type = mgmt.getPropertyKey('type') uid = mgmt.getPropertyKey('uid') mgmt.buildIndex('type_uid', Vertex.class).addKey(type).addKey(uid).buildCompositeIndex() mgmt.commit() |
これはどのGraphDBにも言える事だと思いますが、Indexを作らないと遅くて実用には耐えません。
また上記Indexの定義をしたらImportしてある過去データを含めてINDEXの再構築が必要になります。
JanusGraphでのINDEX再構築
|
1 2 3 |
mgmt = graph.openManagement() mgmt.updateIndex(mgmt.getGraphIndex("type_uid"), SchemaAction.REINDEX).get() mgmt.commit() |
JanusGraphでのINDEX確認
|
1 2 3 |
mgmt = graph.openManagement() mgmt.awaitGraphIndexStatus(graph, 'type_uid').call() mgmt.commit(); |
INDEXまわりについては、公式ドキュメントにも色々載っています。
http://docs.janusgraph.org/latest/indexes.html
UNIQUE制限のある複合INDEXを作成した時に、新規Vertexの追加が出来なくなり
調べたらINDEXが破損していて、かつ消せないという状況になった事がありました。
検索したところ同じ症状になった人もいるようですが、解決策が書かれておらず
現状ではUNIQUE制限をJanusGraph側で持たせる事はリスクがあるかもしれませんので、実際に利用する際はご注意ください。
ベンチマーク
前述した通り benchmark関数を利用しました。
コードに関しては一部 – でマスクし、一部のみ抜粋して載せています。
Read
|
1 2 3 4 5 6 7 |
benchmark{ g.V().hasLabel('UID').has('type', '---').has('uid', "---").next(); g.V("---").in().next(); g.V("---").values().next(); g.V("---").out().next(); } |
上記のようにtypeやuidのpropertyを元にVertexを検索
検索結果のIDを元にEdgeがつながっているVertexを探す
Propertyを参照
といった実際に行うようなクエリを事前に用意しておき
10件~50件まで10件区切りで実施しました。
また1台から実行、複数台から同時実行なども試しています。
Write
|
1 2 3 4 5 6 7 |
benchmark{ v1 = graph.addVertex(T.label, "UID", "type", "---", "created_at", "---", "updated_at", "---", "uid", "---"); v2 = g.V("---").next() v1.addEdge("Mapping", v2) graph.tx().commit() } |
新規でVertexを追加
既存のVertexを取得
両者にEdgeを作成
といった実際に行うようなクエリを事前に用意しておき
10件~50件まで10件区切りで実施しました。
また1台から実行、複数台から同時実行なども試しています。
結果
CPU実行時間での比較になるので数値が低い方がより高速に処理出来ていることになります。
Read
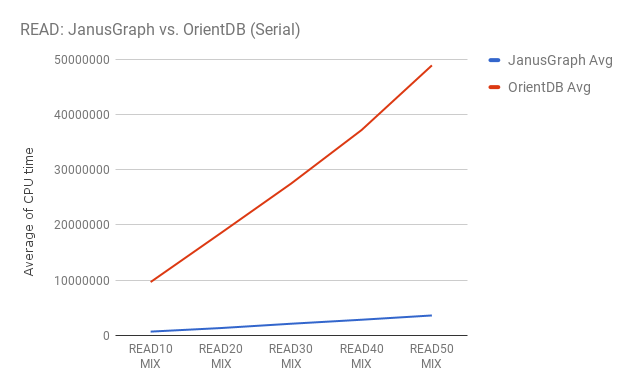
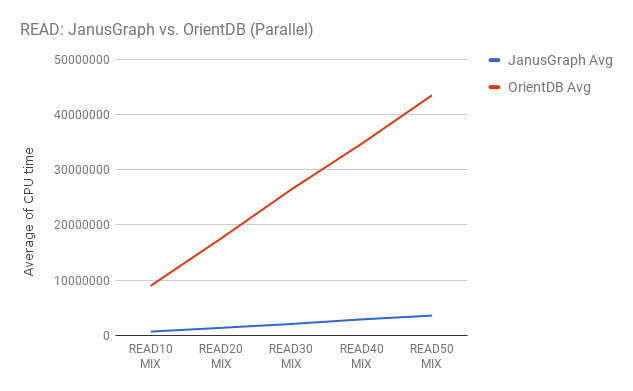
OrientDBもJanusGraphも検索する件数が増えていくときれいにデータ量に比例して時間がかかる
性能比ではJanusGraphが約 12~13倍 高速
Write
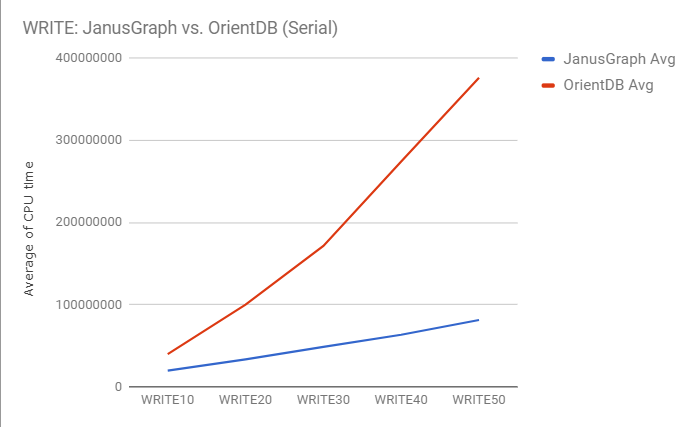
OrientDBのparallelがLockかかるのでSerialで比べてみると
性能比ではJanusGraphが約 2~4倍 高速
JanusGraphの同時実行とシングル実行の差

JanusGraphでの同時実行に関しては、ほとんど変わらない速度で書き込めている
最後に
GraphDBの概念の理解、それぞれの独自の仕様、Tinkerpopのversionの差など
実際に検証してみると詰まってしまうようなポイントが多々ありました。
今回検討にあがらなかった他のGraphDBも多数ありますし、
今後の開発によってはまた状況も変わってくるとは思いますが少しでも参考になれば幸いです。
Author