Blog
AWS SageMakerのハンズオンを実施していただきました!
こんにちは!
AI事業本部 小売DXセンター AirTrackの宗政 一舟(ムネマサ イッシュウ)です。
先月6月18日(木)にSagemakerハンズオンをAWS様にオンラインで開催していただきました。
AirTrack用にカスタマイズされたハンズオンで、チームのデータサイエンティスト・サーバーサイドエンジニア皆で参加しました!
当日の様子と内容をブログにさせていただきます☆
はじめに
機械学習は実世界のサービスで広く活用されるようになってきました。
しかし、データサイエンティストやMLエンジニアの開発した学習モデルをいざサービスに導入しようとした時に
機械学習特有の課題に直面することがあると思います。
学習に用いたデータによって出力される値が変化するため、学習モデルのテストをすることが難しい点や
出力値に異常が存在したことが分かってもデータ、学習アルゴリズム、前処理等のプログラムの
どこに問題があったのかを突き止めることはとても大変です。
リリース時だけでなく、サービスで正常に動作させる運用面の課題もあります。
例えば
時間の経過とともに性能劣化する可能性のある学習モデルを定期的に更新できる状態にしておくこと
オフラインでの評価が良くても本番環境で暴走してしまう恐れがあるため、学習モデルの出力値をモニタリングできるようにしておくこと
などなど。。。
ここ数年で「MLOps」という言葉がでてきたように
機械学習の開発/運用は多くの企業で取り組まれるようになっています。
今回のハンズオンでは、そんな機械学習システムの開発/運用をしていく上で大事な要素の一つである
学習モデルの性能劣化への対応を題材に行っていただきました!
テーマ
AirTrackは位置情報を用いた来訪計測や広告配信を行うことのできるプロダクトです。
来訪見込みの高さを考慮して広告を配信するサービスがAirTrackにはあり、来訪を予測する機械学習モデルを採用しています。
このモデルの性能の劣化が確認されたときに、更新を行える機械学習パイプラインの作成を目指しました。
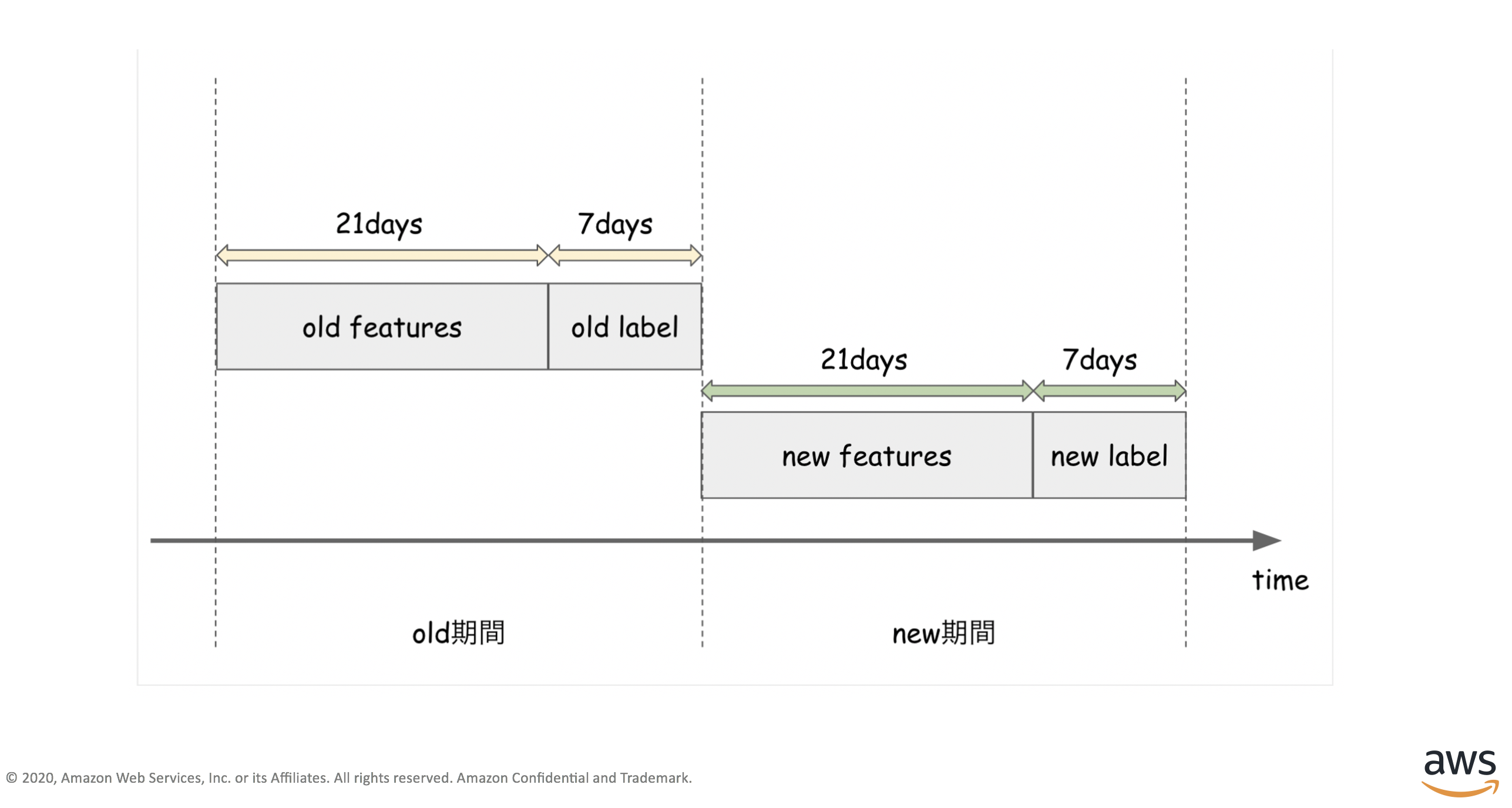
このハンズオンで想定している状況としては
「old期間中のデータ」で作成した来訪予測モデルが現在本番環境で動いているものとして
「new期間中のデータ」が揃っタイミングで、new期間のモデルとold期間のモデルとの性能を比較し
劣化が確認されたとき本番で動作しているモデルを入れ替えるものになります。
AirTrackサービスに基づいたハンズオンを用意していただいたので、実務を意識して取り組むことができました。
ハンズオンのダイジェスト
作成した機械学習パイプラインのアーキテクチャになります。
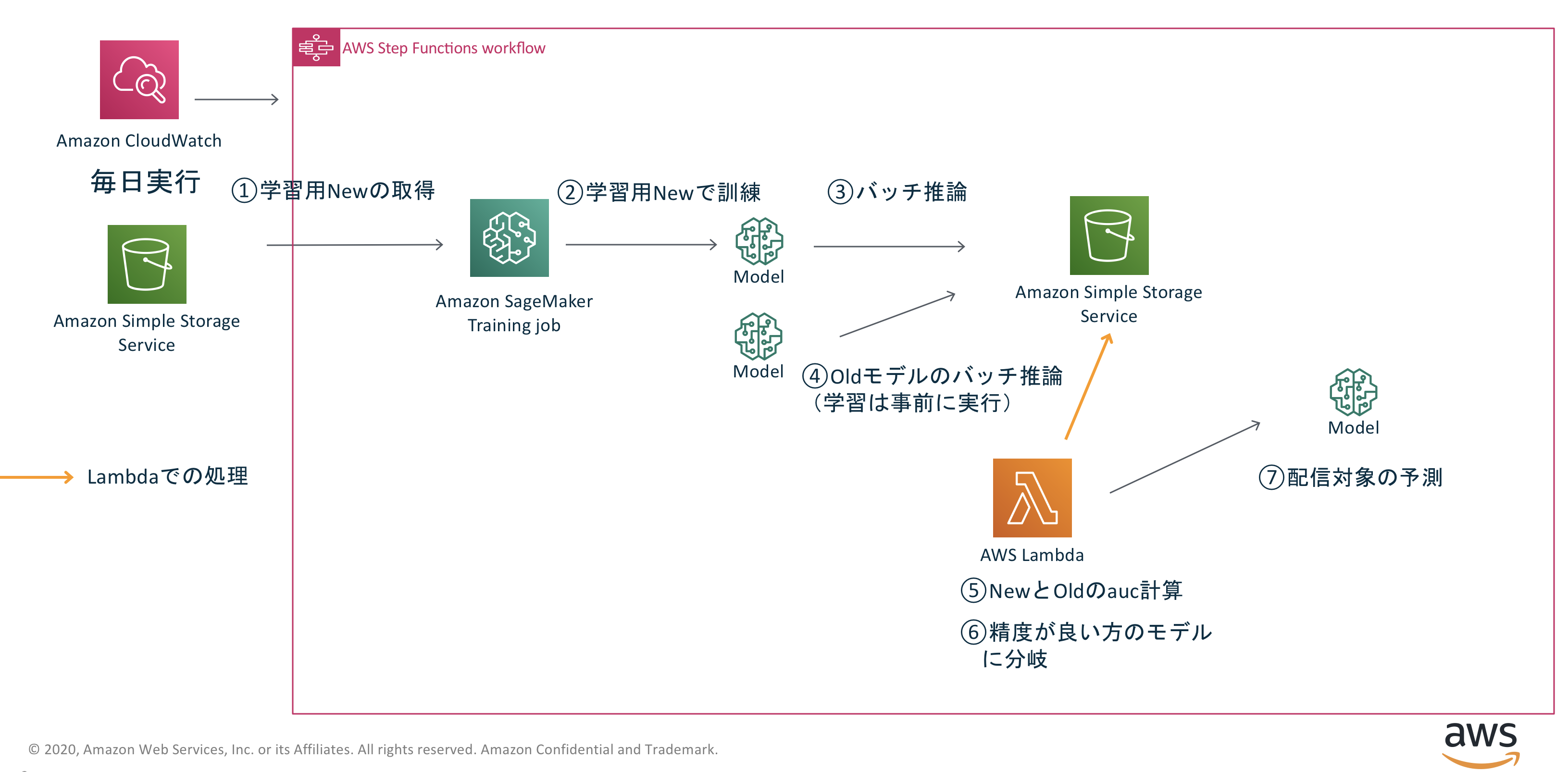
「モデルの学習」や「推論の部分」は Amazon SageMakerで作成し
old期間中で作成したモデルとnew期間中で作成したモデルの性能比較をAWS Lambdaで行うような構成で
ワークフローの作成にはStep Functionsを使っています。
開発環境の準備
Amazon SageMakerのコンソールからノートブックインスタンスを作成しました。
起動したいインスタンスタイプを設定すると、JupyterまたはJupyterLabで開けるようになります。
ノートブックの環境構築が簡単なことに加えて、必要なリソースを選択して開発者が各々で起動できるのは便利ですね☆
学習モデルの開発
来訪予測モデル作成にXGBoostを用いました。
AWS Sagemakerでは組み込みのアルゴリズムや独自のアルゴリズムを使うものなど、モデルのトレーニングを定義するのにいくつか方法があるみたいですが
今回はAWS Sagemakerが提供しているXGBoostのフレームワークを利用しました。
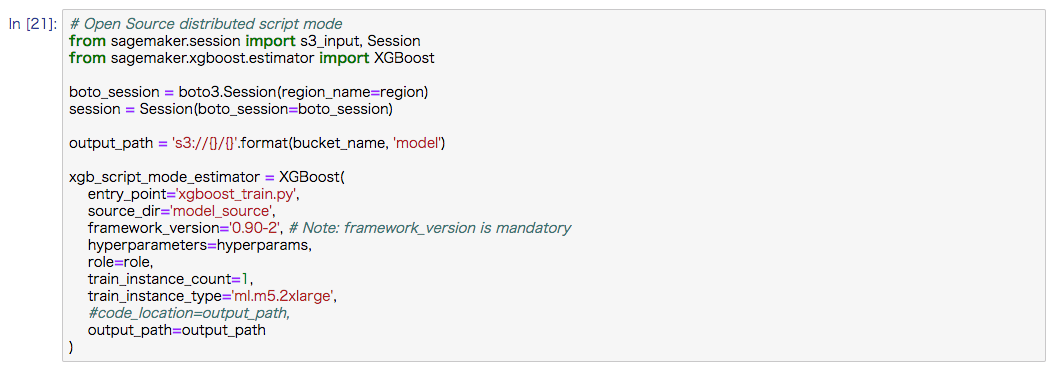
以下の xgb_script_mode_estimator の部分で
- 学習用のpythonのスクリプト
- 学習が動作するインスタンスサイズ、インスタンスの数
- ハイパーパラメータ
- 作成された学習モデルの保存先(S3のパス)
を渡してあげるとXGBoostが使用できるコンテナが呼び出されます。
続いてfit関数で学習の実行します。
この時、train用のデータやvalidation用のデータが置いてあるS3のパスを引数で渡すと
置いてあるデータを読み込みモデルのトレーニングをしてくれます。
![]()
学習の状況については
ノートブックインスタンスのセルや
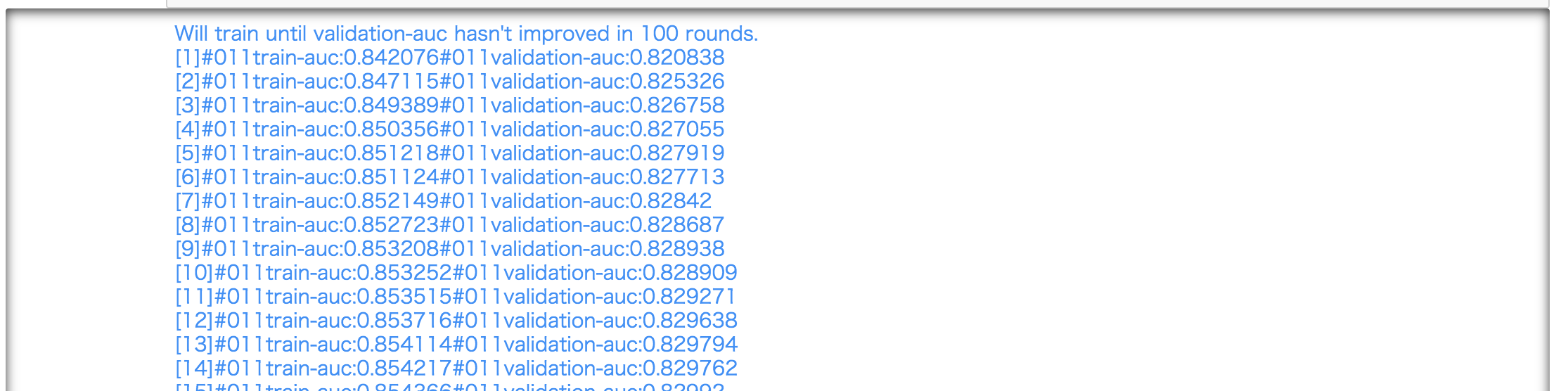
CloudWatch Logsから確認できました。

モデルの開発者は「学習用のデータ」と「学習用のコード」を準備すれば
ノートブックからインスンタンスサイズと数を指定してモデルのトレーニングを実行できるようになるので、本番同様の環境での動作確認がかなりラクになると思いました。
また立ち上がったインスタンスはジョブが終了したら勝手に落ちてくれるので、お金まわりでも嬉しさがあるかもしれません☆
実行フローの作成
StepFunctionsに各処理を実行するためのワークフローを定義していきます。
以下のようなワークフローを目指しました。
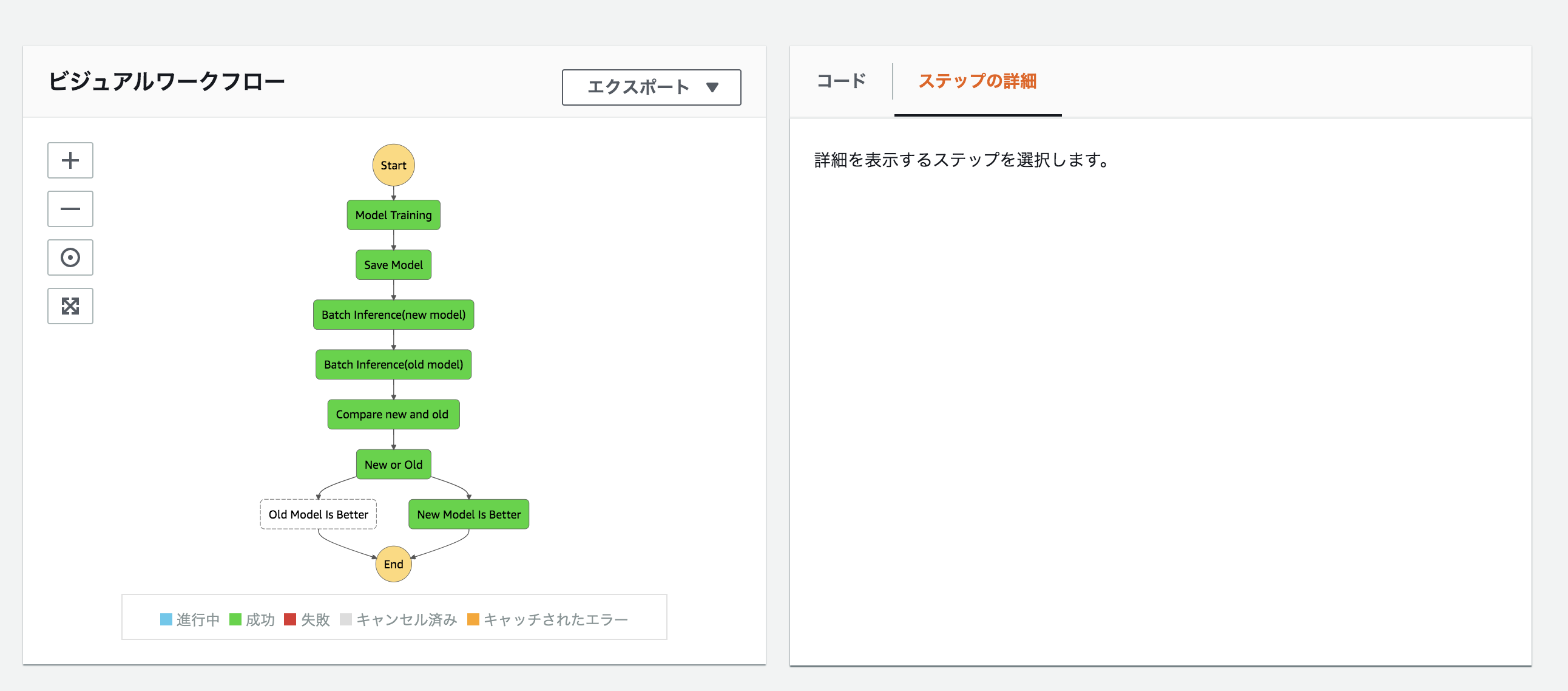
StepFunctionsでの実行の流れとしては
まず新しいデータに対してモデルのトレーニングジョブ行います。
続いてnew期間中で作成された学習モデルでバッチ推論ジョブold期間中で作成された学習モデルでバッチ推論ジョブの実行。
最後にnew学習モデルとold学習モデルをAUCで評価して、良かった方を採用といったものになります。
StepFunctionsの各プロセス(step)の作成
StepFunctionsのビジュアルワークフローのModel Trainingの部分の例です。

trainining_stepにプロセスの名前やestimator、学習に用いるデータのS3パスを渡してTrainingStepを定義します。
ステートマシン図を書かなくてもpythonのSDKからプロセスを定義できるみたいです。
またノートブック上で動作の確認ができていればStepFunctionsのワークフローに乗せられるので、モデル開発者が本番環境のリソースやパッケージのバージョンを気にする負担は減らせるのかなと思いました。
StepFunctionsの各プロセス(step)を連結
training_stepのように、その他のプロセスについても定義した後
独立して定義されたプロセスを連結させてあげます。

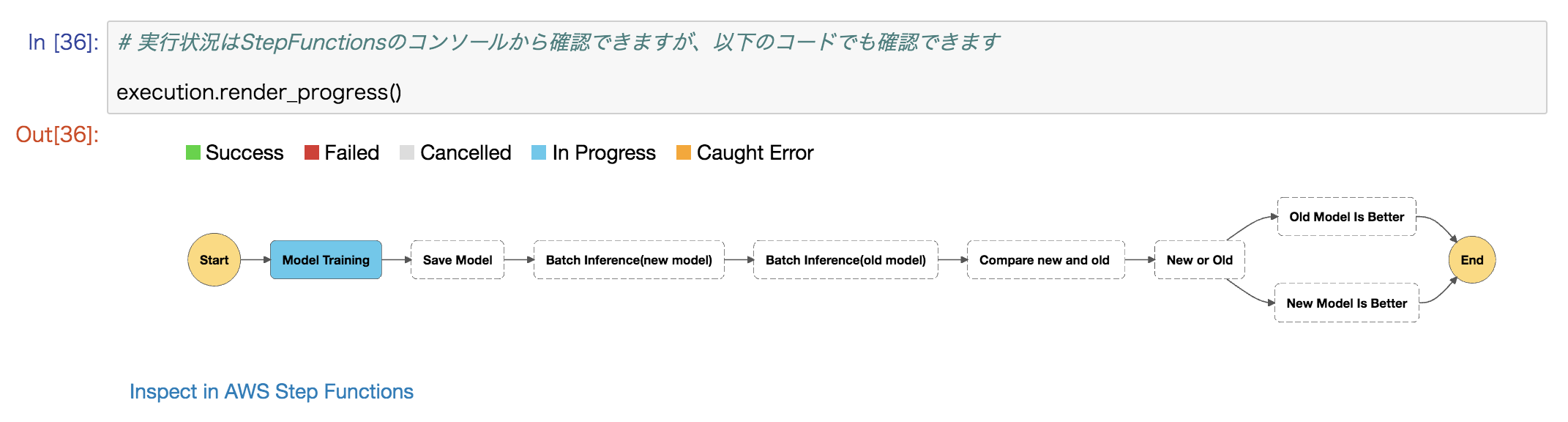
作成したワークフローはノートブック上で可視化して確認することができます。
 またノートブック上からStepFuncsionsをキックし、その実行状況もセルに出力することができました。
またノートブック上からStepFuncsionsをキックし、その実行状況もセルに出力することができました。
 ノートブックインスタンス環境から色々なAWSのサービスを使えるようにするためのIAMの設定が必要になりますが
ノートブックインスタンス環境から色々なAWSのサービスを使えるようにするためのIAMの設定が必要になりますが
今回のハンズオンで作成した「SageMakerとStepFunctionsを用いた更新フロー」の開発はノートブック上で完結するものになっていました☆
3時間という短い時間で開発環境構築から機械学習パイプライン作成までできてしまうのは衝撃的でした。
最後に
実際のAirTrackサービスを意識した機械学習のパイプラインを作成するハンズオンをAWS様に開催していただきました。
機械学習サービスに携わったことのあるメンバーだけでなく初めて触れるメンバーも参加し、とても良い機会だったと思います。
また早速今回の知見を業務内で活かせる場面もあったりと、収穫の多いハンズオンでした。
オフライン開催の厳しい時世の中、急遽オンライン開催で対応していただき本当にありがとうございました!
ハンズオンの様子です☆
会社に来ていたメンバーで自席以外で作業したいメンバーは少し広めの部屋から参加しました☆

最後まで読んでいただきありがとうございます!
Author