Blog
MLflowをGoogle Kubernetes Engineで動かす快適な実験管理ハンズオン
AI Labの岩崎(@chck)です、こんにちは。今回は前記事よりも実践的な、AI Labにおける実験管理システムの話をしたいと思います。ここでいう実験とは、データを収集・加工し、統計や機械学習を用い、設定したタスクや仮説を明らかにすることです。実験管理とはその評価や使ったパラメータ及び実験コードを再現できる形で保管することを指します。
対象読者
- 個人や大学、企業所属でJupyterLab上の実験管理に苦労している方
- チームでKaggle等のデータ分析コンペに参加している方
- Kubernetes、GCP、Terraformといったキーワードに興味のある方
tl;dr
MLflowをGKEに載せることで、高可用でユーザ認証を持つMLflow Tracking Serverを作りました。更にTerraformによる1command構築を目指しました。中規模以上の研究室を想定し、Load Balancingにより各ユーザで独立した実験管理を実現しました。個人や少人数チームな場合は、GKEよりもManagedなコンテナサービングサービスであるCloud RunでCloud IAPというユーザ認証が使えるようになったので、本記事をベースにそちらの構成で試すとシンプルで良いでしょう。
はじめに
皆さんは普段どのように実験管理していますか。AI Labには現在30名弱のResearcherが在籍しており、各人が大学のゼミのようにメインテーマを持って日々R&Dに励んでいます。実験のための計算リソースやデータ管理にGCP・AWS・オンプレが用意されており、個々が自由に使えるようになっています。ありがたいことにLabメンバーの増加に伴い、実験やデータ管理を各々が1から行うことで、似た構成のインフラが複数立ち、ノウハウの不透明化やメンテコストが目立つようになりました。そこで今回はResearcherが共通で使えるMLflow Clusterを構築してみます。
2021年現在、実験管理サービスといえばどんなものが思い浮かぶでしょうか。OSSであるMLflowやTensorBoard・Keepsakeの他、SaaSであるNeptune.ai、Comet.ml、Weights & Biases [1]あたりが有名ですね。ワンマンプロジェクトであればSaaSで十分事足りると思いますが、複数人での実験結果の共有や無料版での制限以上のことをやろうとするとMLflow等を自前で立てようと検討するはずです。そしてサーバーを立て、依存するDBやStorageを用意し、PublicにHostingするのであればユーザ認証を行い、HTTPS対応も一緒に…と予想以上に準備が大変なことに気づくでしょう。本来やりたいのはインフラのメンテではなく実験管理なのに、と。そう、各人がインフラ構築やメンテをする必要はなく、共通で1つの実験管理サービスをチームやゼミで使い回せたらそれでいいのです。早速始めましょう。
Architecture
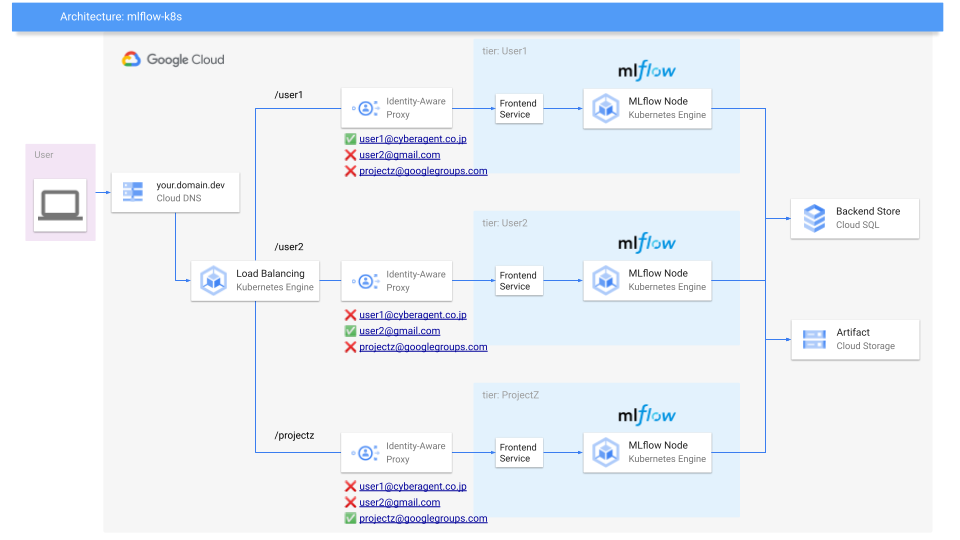
今回はGCPを想定し、その全体構成図がこちらです。MLflowをGKE上に展開し、ユーザからのアクセスはCloud Identity Aware Proxyを通すことで、Whitelist形式のユーザ認証を実現します。更にIngressによるLoad BalancingによりUserやProject単位でMLflow Serviceごと分離します。依存するDBとStorageのInstanceとBucketは共通で持ちますが、DatabaseやStorage pathは前述したUserごとに分けます。これによりインフラリソースを必要最小限に保ちつつ、ユーザの実験管理スペースが干渉しない形を目指しています。これはEconomicsやCV、NLP、HCIと研究領域が多岐にわたるAI Labをベースにしているため、読者の皆さんの環境ではこの限りではなく、Userごとに分離しないシンプルな1 MLflow Serviceも良いと思います。
ハンズオン
ここからはTerraformの実コードを通じて、GCP上に前述した実験管理クラスタを立ててみます。コストの概算ですが、ベースがGKEとStorage、Cloud SQLで$76/month、ユーザ1人増えるたびに、+$10です。
https://cloud.google.com/products/calculator#id=5bffe958-d86b-43d7-844f-162bae9675fe
利用人数によっては可用性を下げ、Cloud SQLをServerのPersistent Diskに変更することで$76/month → $14/monthくらいに落とすことができます。
https://cloud.google.com/products/calculator#id=90e6e7bf-2b6b-48e0-964c-90c6e8e4eda5
値段感もわかったところで、GCPのProjectを用意しましょう。このハンズオンに使ってもらうのはおこがましいですが、初GCPの方は$300の無料トライアルクレジットが付与されるのでそれを利用しても良いでしょう。ここからはGithubのコードを使って進めますので適宜cloneして参照してください。
https://github.com/chck/mlflow-k8s
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
[mlflow-k8s] tree . . ├── Dockerfile ├── Makefile ├── README.md ├── docker-compose.yml ├── infra │ ├── 01_setting.tf │ ├── 02_serviceaccount.tf │ ├── 03_gke.tf │ ├── 04_deployment.tf │ ├── 05_network.tf │ ├── 06_iap.tf │ ├── 07_storage.tf │ ├── 08_database.tf │ ├── manifests │ │ ├── backend_config.yaml │ │ └── managed_certificate.yaml │ └── secrets ├── poetry.lock ├── pyproject.toml └── scripts ├── Makefile ├── poetry.lock ├── pyproject.toml └── tracking_sample.py |
依存ツールのインストール
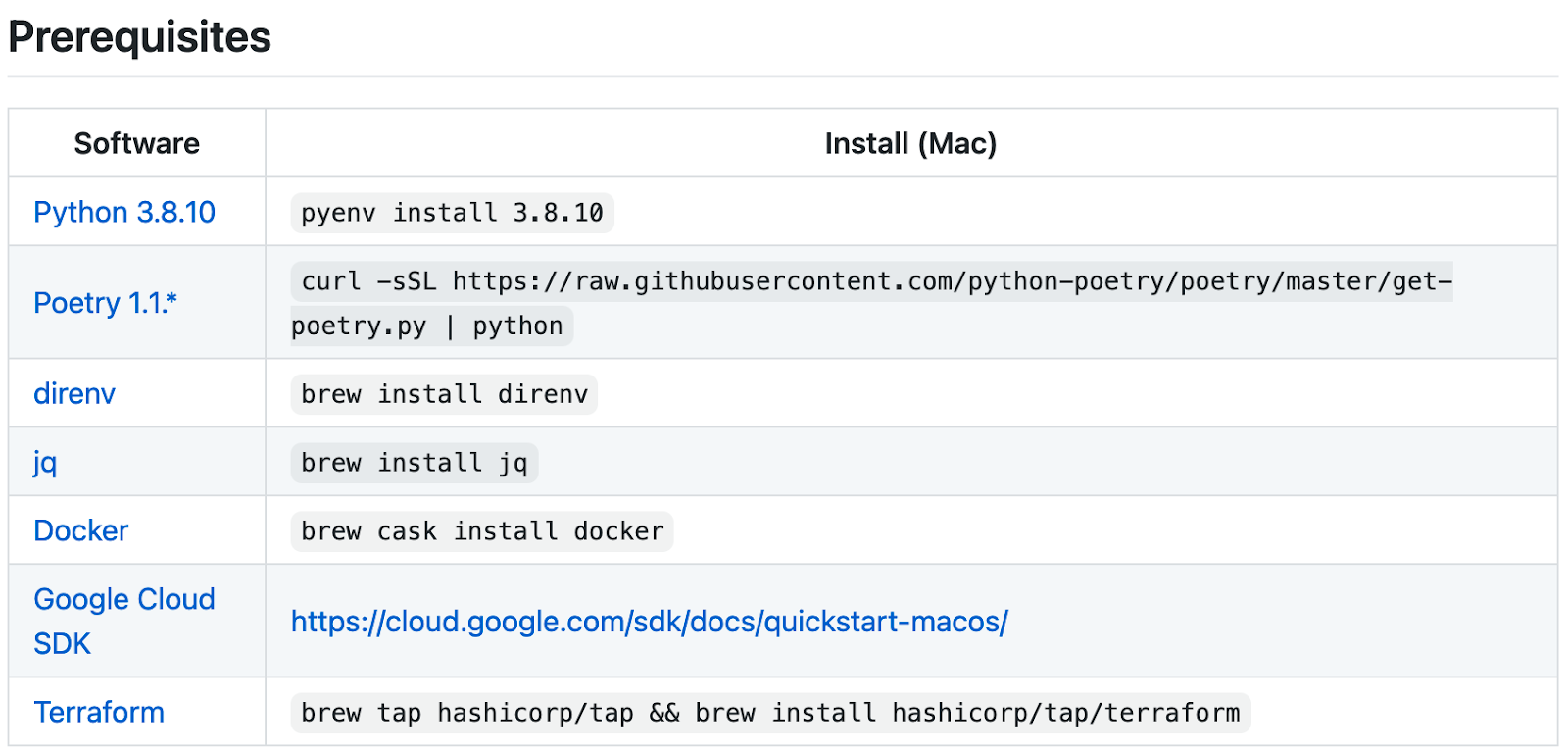
まずはREADME.mdにあるように、必要な依存をインストールしましょう。Macの例で申し訳ありませんが、LinuxやWindowsでも似たような方法で揃えられるはずです。
OAuthの設定
Architectureの説明で、「ユーザからのアクセスはCloud Identity Aware Proxyを通すことで、Whitelist形式のユーザ認証を実現」とあったと思いますが、その前提のOAuthの設定です。Cloud IAPは、GCPが用意しているOAuth認可によるProxyで、そのhostへアクセスした際にGoogle Loginが求められ、許可されたGoogle Accountでない限りはアクセスできないという仕組みです。
まずはOAuth同意画面を設定します。GCP Projectで1つなので、既に設定してある場合は飛ばしてもらって構いません。https://console.cloud.google.com/apis/credentials/consent から、EmailやApplication nameを入力し、保存すればOKです。なお、ここで設定した情報がApplicationの認証ページに表示されるため、公開情報のみ入力してください。
OAuth Credentialsのページに移動します。
Create credentials → OAuth Client ID → Application type → Web applicationから、名前をmlflowとし、Createをクリックします。OAuth Client ID とClient Secretが生成され、OAuth Clientの画面に表示されます。
OK をクリックし、作成したClientを選択します。Client ID をクリップボードにコピーします。
Authorised redirect URIs フィールドに次の形式でリダイレクト URL を追加します。
https://iap.googleapis.com/v1/oauth/clientIds/CLIENT_ID:handleRedirect
ここで、CLIENT_ID は先程コピーした OAuth Client ID です。
ページの上部にある DOWNLOAD JSON ないしダウンロードアイコンをクリックし、JSONをダウンロードします。
このJSONはIAPの設定時にTerraformから参照するため、infra/secrets フォルダに oauth_client_secret.json という名前で置いておきましょう。なお、このフォルダは.gitignoreに指定しているので、mlflow-k8s repoで試す場合にcredentialsがgit remoteに上がる心配はありません。
ドメインの準備
Cloud IAPによるユーザ認証にはSSL/TLSが必要なので、任意のドメイン取得サービスから独自ドメインを取っておきましょう。会社や研究室でドメインが割り当てられている場合や既にドメインを持っている方は、そちらを使えば大丈夫です。本稿では仮にmlflow.sandbox.devとします。
Terraformの設定
次に、Terraformを介してGCPを操作するためのService Accountを作成します。TerraformとはGCPやAWSといったインフラの構築をコードで管理できるHashiCorp社製のOSSです。ポチポチで構築した場合と比べ、構築手順の再現性や設定の可視性という点で優位なため、今回はこちらを利用していきます。用意していただいたGCPの画面の左側のメニューからIAM & Admin → Service Accountsと進み、Create service accountから、Terraform用のService Accountを作成しましょう。本稿では mlflow-terraform と名付けますが、目的や所属によってxxx-terraformなど、何を司るaccountなのかがわかる名前にすると良いでしょう。
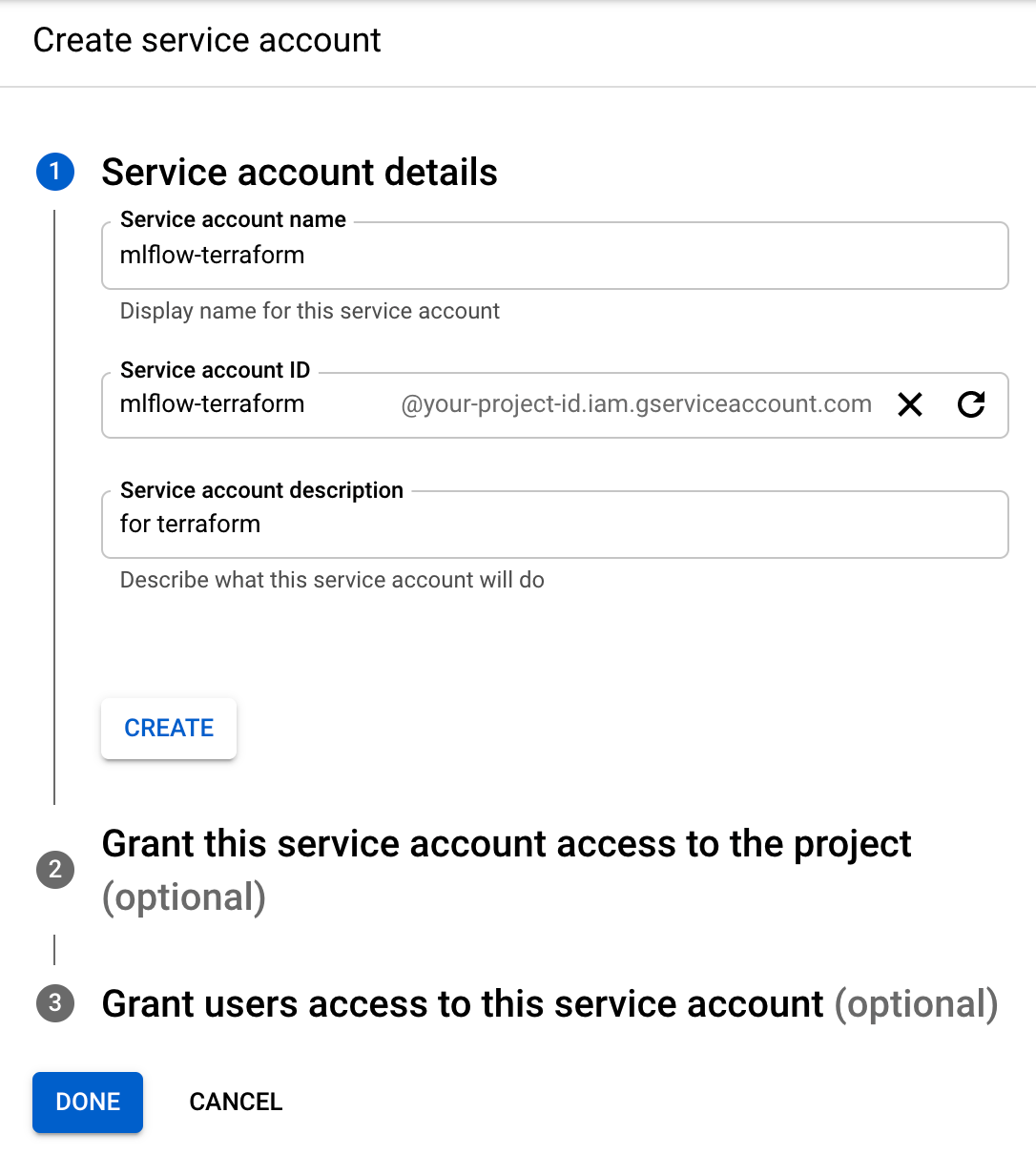
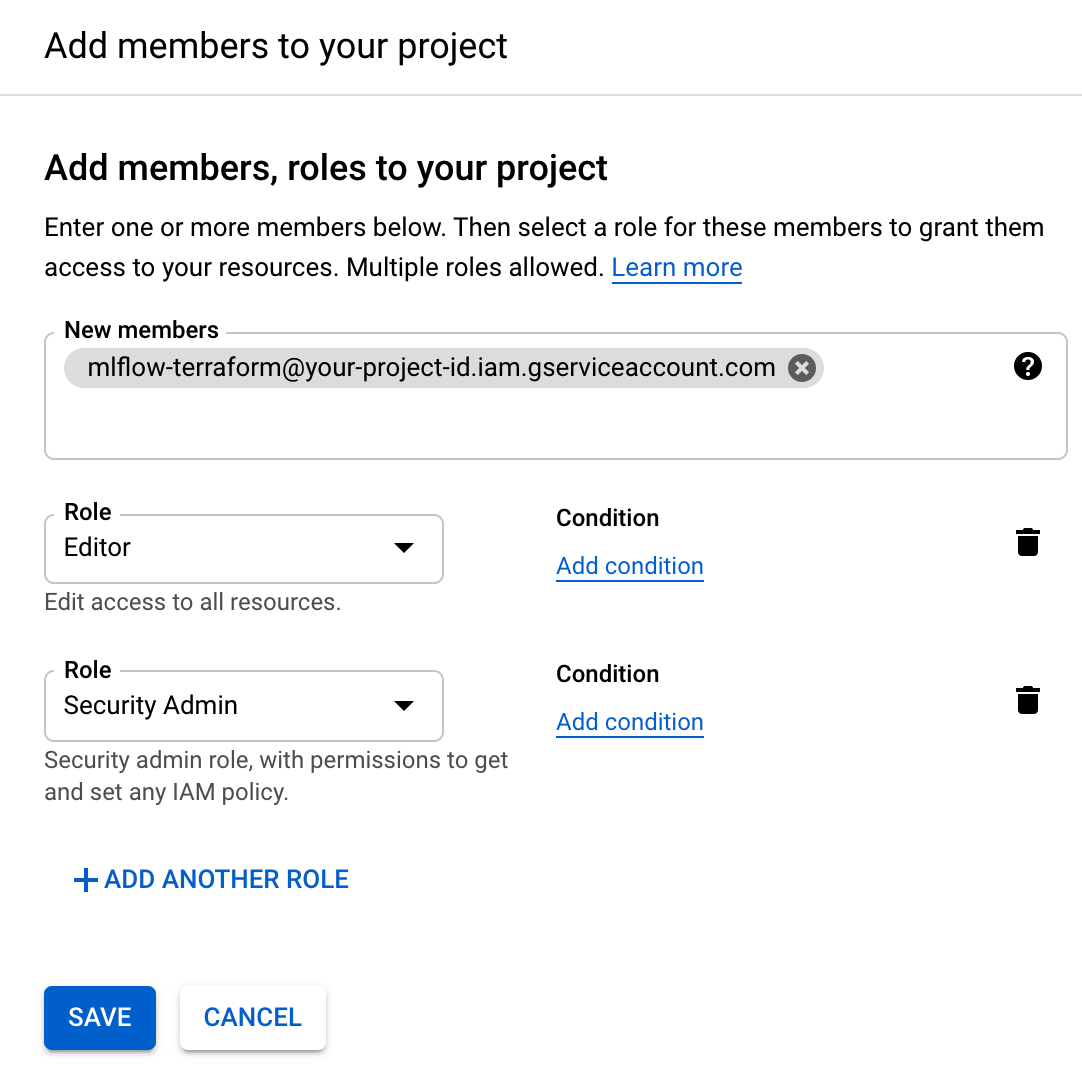
無事に作成できたらService Account 一覧に出てくるので、右の︙からManage keys → Add key → Create new keyからJSON形式のPrivate keyをDownloadします。

これをTerraformから参照することで、GCPの各サービスへのアクセスを可能にします。Privateとあるように、GCPへのアクセス権のあるKeyなのでPublicには上げないようにしましょう。このService Accountにはまだ何のRoleも付与していないので、Terraformが期待するRoleをIAMとして付与します。Service Accountとして発行されたEmail(mlflow-terraform@your-project-id.iam.gserviceaccount.com)に、IAM → Add から EditorとSecurity Admin の 2 Roleを付与します。ハンズオン的に簡単のため、この2つを付与していますが、Roleは必要最小限が基本なので、強すぎると思った方は適宜調整してください。
ここでREADME.mdに戻ります。Get Startedという項の通りに、.env.exampleをcopyして.envを編集します。
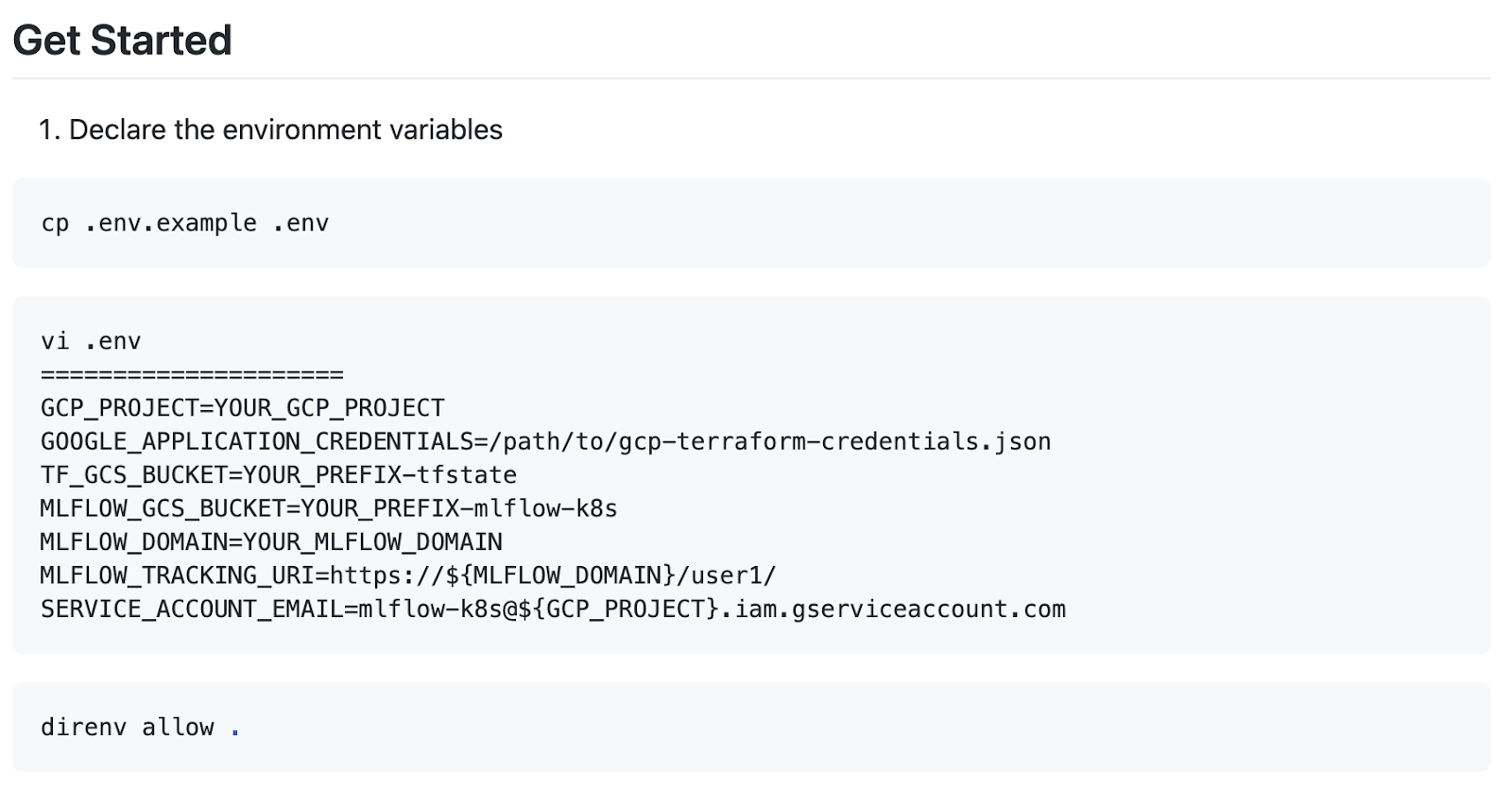
まずYOUR_GCP_PROJECTは自身のGCPのProject IDに置き換えます。
GCPのProject IDは、https://console.cloud.google.com/home/preview?project=your-project-id のproject=以下の部分のように、GCP ProjectのURLやGCPのDashboardから確認することができます。GOOGLE_APPLICATION_CREDENTIALS=/path/to/gcp-terraform-credentials.jsonには先程ダウンロードしたJSONの絶対パスを記述します。
TF_GCS_BUCKETについて、Terraformでは管理下のインフラの状態をstateとして持ち、構築時にはstateとの差分更新という戦略を取るのですが、今回そのstateの置き場所にGCSを使います。Bucketは何でもいいのですが、慣習的にbucketには-tfstateというsuffixをつけ、YOUR_PREFIXの部分はmlflowなり、mlflow-k8sなりに置き換えてください。(TF_GCS_BUCKET=YOUR_PREFIX-tfstate)
MLFLOW_GCS_BUCKETは、Terraformのstateが置かれるTF_GCS_BUCKETとは異なり、MLflowで実験管理する上でArtitectと呼ばれる画像などのバイナリ置き場になります。別のバケット名を命名しましょう。
MLFLOW_DOMAINには、ドメインの準備の項で用意した各々のドメインを記述します。本稿ではmlflow.sandbox.devとしています。
ここまで変更できたらREADMEで入れたdirenvの direnv allow . コマンドによって.envに定義した環境変数をそのディレクトリ下にいる間、自動で読み込むことができます。export要らずで便利ですね。
次に、Terraformの実体であるtfファイルに皆さんに用意して頂いた環境変数依存な部分があるので、以下のコマンドで置換します。Makefile内にmake tfコマンドの実体がありますが、内部で使っているsedのsyntaxはGNU sedではなくMac sedなので、お手元の環境によっては差し替えてください。
|
1 |
make tf |
make tf までできたらTerraformを動かす前に、前述したterraformのstateを管理するために、GCSのBucketを作ります。Makefileに作成処理をまとめているので次のコマンドを叩きましょう(依存ツールのインストール項、要Google Cloud SDK)。
|
1 |
make bucket |
無事にBucketが作られたら、infraフォルダに移動し、Terraform コマンドを叩いてみましょう。Terraformの依存packageとstateファイルの準備が行われます。
|
1 2 |
cd infra terraform init |
stateファイルができたところで、インフラ構築の実行計画を以下のDry-Runコマンドで確認します。
|
1 |
terraform plan |
30近いリソースがAddされることがわかります。これらはinfra以下の各tfファイルを参照しており、各リソースの設定が記述されています。あとは以下の実行コマンドを叩いて内容を確認後console上でyesを入力し、数十分待つだけで実験管理クラスタが立ち上がります。
|
1 |
terraform apply |
初回実行時に、以下のようにAPIが無効なエラーが出た場合は、ログで案内されているURLから有効化し、再度applyコマンドを実行してください。おそらくCloud DNS、Cloud SQLあたりで出ると思います。
|
1 |
Error: Error, failed to create instance mlflow-k8s: googleapi: Error 403: Cloud SQL Admin API has not been used in project xxx before or it is disabled. Enable it by visiting https://console.developers.google.com/apis/api/sqladmin.googleapis.com/overview?project=xxx then retry. If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry., accessNotConfigured |
また、GKEクラスタが立ち上がったら Makefileのあるdirectoryで make creds を叩くとローカルにGKEクラスタの設定を読み込んでくれるので、kubernetesに面識がある方はkubectlコマンドからdebugも可能です。ネットワーク周りが怪しい場合はGKEに割り振られたPublic IPとDNSの紐付けなど、用意したドメインのDNS周りの設定を見直してみましょう。Timeoutになった場合は、インフラが立ち上がりきっていない可能性があるので、数十分待ってから再度applyコマンドを実行してみてください。
Terraformによるインフラ構築を待っている間、各リソースごとにポイントを紹介します。はじめに、Terraformファイルの読み方を簡単に説明します。.tf拡張子が対象で、ファイルの分け方に厳密なルールはありませんが、今回はわかりやすくするためにGCPのサービスごとに分けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[mlflow-k8s] tree infra infra ├── 01_setting.tf ├── 02_serviceaccount.tf ├── 03_gke.tf ├── 04_deployment.tf ├── 05_network.tf ├── 06_iap.tf ├── 07_storage.tf ├── 08_database.tf ├── manifests │ ├── backend_config.yaml │ └── managed_certificate.yaml └── secrets └── oauth_client_secret.json |
01_settings.tfを開いてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
terraform { required_version = "~> 1.0.0" required_providers { google = { source = "hashicorp/google" version = "~> 3.77.0" } google-beta = { source = "hashicorp/google-beta" version = "~> 3.77.0" } local = { source = "hashicorp/local" version = "~> 2.1.0" } random = { source = "hashicorp/random" version = "~> 3.1.0" } kubectl = { source = "gavinbunney/kubectl" version = "~> 1.11.1" } postgresql = { source = "cyrilgdn/postgresql" version = "~> 1.13.0" } } backend "gcs" { bucket = "_YOUR_BUCKET" prefix = "mlflow-k8s" } } variable "common" { type = map(string) default = { project = "_YOUR_PROJECT" region = "asia-northeast1" zone = "asia-northeast1-c" } } locals { common = var.common users = var.users } variable "users" { type = set(string) default = [ "user1", "user2", "projectz", ] } provider "google-beta" { project = local.common.project } provider "google" { project = local.common.project } |
JSONのような構文で、terraformやvariable、locals、providerといったkeyのようなものがterraformの予約語です。01_settings.tfでは、その名の通りTerraformの設定や依存、全体で使いそうな変数をまとめて定義しています。terraform句で操作したいリソースに必要なパッケージをVersion付きで指定します(requirements.txtのようなもの)。今回はGCPでMLflowを動かしたいという目的なので、googleやkubectl、postgresqlといった依存を加えています。backend “gcs” という部分は、Get Startedで説明したterraformのstateファイルの置き場所を指定しています(AWSでやるならbackend ”s3”ですね)。
variable句はterraform内で参照できる変数の定義で、typeによってhashmap型だったりset型など自由に記述できます。ここではGCPのProject IDやregionの他、複数人でのMLflowを想定しているので、そのUser IDをまとめています。参照するときにはvar.common等で呼べる他、locals句を挟むことでaliasのように、local.commonで呼べるようになります。今回の例ではlocalsの恩恵は少ないのですが、例えばdevとprdで変数だけ一部変更して同じインフラ構成にしたい場合、以下のように記述すると、TerraformのWorkspace機能を利用して1つのterraformファイルで挙動を変えることができるようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
variable "common" { type = map(map(string)) default = { dev = { project = "_YOUR_DEV_PROJECT" machine_type = “e2-micro” # コスパ重視 } dev = { project = "_YOUR_PRD_PROJECT" machine_type = “e2-highmem-2” # 性能重視 } } } locals { common = var.common[terraform.workspace] users = var.users } |
次に、07_storage.tfを開いてみましょう。
|
1 2 3 4 5 |
resource "google_storage_bucket" "artifact" { name = "_YOUR_MLFLOW_BUCKET" location = "ASIA" storage_class = "MULTI_REGIONAL" } |
このresource句が実際に操作を行う構文で、Terraform側で用意されている “google_storage_bucket” resourceに対して、”artifact” という任意の名前をつけています。このresourceが必要とする引数(name、location、storage_classなど)を元に、Storageが作成されます。GCPのストレージ作成画面から必要項目を入力するようなイメージです(基本的にフォーム入力とGCloud SDK、Terraform Resource間の引数が対応しているはず)。
tfファイルには01_から08_とprefixをつけているものの、Terraform的には01から逐次的に実行されるわけではなく、terraform planやterraform apply時に配下のtfファイルをまとめて読み込んだ上で実行順を決定してくれます。
Terraformの概要が説明できたところで、ポイントを端折りつつ内容の解説に入ります。まずは02_serviceaccount.tfの resource “google_service_account_iam_binding” “wi” の roles/iam.workloadIdentityUser についてです。
|
1 2 3 4 5 |
resource "google_service_account_iam_binding" "wi" { service_account_id = google_service_account.sa.name role = "roles/iam.workloadIdentityUser" members = formatlist("serviceAccount:${local.common.project}.svc.id.goog[%s]", ["${var.deployment.k8s_namespace}/${var.deployment.ksa_name}"]) } |
GKE上のNodeからManaged DBなどの他のGCP Serviceにアクセスするためには、a)対象Instanceを同一VPCネットワークに置く方法、b)Service AccountのCredentialをNodeに置いて認証、c)Workload Identityによる認証、の大きく3パターンがあります。設定の煩雑さやセキュリティ上の観点から、Googleはc)Workload Identityを推奨しているため、本稿ではその方法を取ります。Workload Identity自体の説明は本稿の目的と離れてしまうため割愛します。
次に、03_gke.tfの resource “google_container_node_pool” “preemptible_nodes” のnode_config内、preemptible = trueです。
|
1 2 3 4 5 |
node_config { preemptible = true machine_type = var.gke.machine_type disk_size_gb = var.gke.disk_size_gb ... |
GCPのPreemptible Instanceとは、従来のinstanceと比べ24時間以内に1度は落ちる等、可用性を落とすことで最大8割OFFという格安で利用できるinstanceです。安定性が求められるようなProduction Serviceでの利用は向いていませんが、今回のような用途ではコスパ最強です。GCPのマネージドサーバーにはGKEの他にApp EngineやCloud Runがありますが、唯一このpreemptibleが利用できるGKEを選ぶ利点の一つにこれがあります。[2]
04_deployments.tfの resource “kubernetes_deployment” “mlflow” です。Kubernetes Clusterを構成するMLflow Containerの実体を定義しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
resource "kubernetes_deployment" "mlflow" { for_each = local.users depends_on = [ google_container_cluster.primary, kubectl_manifest.backend_config, kubernetes_service.internal, ] metadata { name = "mlflow-${each.value}" } spec { selector { match_labels = { tier = "mlflow-${each.value}" } } template { metadata { labels = { tier = "mlflow-${each.value}" } } spec { service_account_name = kubernetes_service_account.ksa.metadata[0].name node_selector = { "iam.gke.io/gke-metadata-server-enabled" = "true" "cloud.google.com/gke-nodepool" = google_container_node_pool.preemptible_nodes.name } container { name = "mlflow" image = "chck/mlflow:1.17.0-patch1" args = [ "--static-prefix=/${each.value}", "--backend-store-uri=postgresql://$(DB_USER):$(DB_PASS)@$(DB_HOST)/u_${each.value}", "--default-artifact-root=gs://${google_storage_bucket.artifact.name}/${each.value}/mlruns", "--gunicorn-opts=--worker-class=gevent --access-logfile=- --timeout=180 --log-level=debug", ] port { container_port = 5000 } env_from { secret_ref { name = kubernetes_secret.mlflow_secret.metadata[0].name } } readiness_probe { http_get { path = "/health" port = 5000 } } } container { name = "cloud-sql-proxy" image = "gcr.io/cloudsql-docker/gce-proxy:1.23.1-alpine" command = ["/cloud_sql_proxy", "-instances=${var.common.project}:${var.common.region}:${var.database.instance_name}=tcp:5432"] security_context { run_as_non_root = true } } } } } } |
2行目の for_each = local.users により、for_eachのついたresourceはlocal.usersの分だけ繰り返され、結果的に各user(今回はuser1, user2, projectz)のresource “kubernetes_deployment”を1度に作成できます。
参照するdocker imageは、MLflow Tracking Serverにstatic-prefixというserver rootを変更するoptionを付けて立ち上げた場合に、mlflow clientからapiが届かない問題を解消するpatchを当てたものです。–static-prefix=/user1 という引数がuser毎に切り分ける実験管理クラスタの実験スペースの1pathを示します。backend-store-uriとdefault-artifact-rootはMLflowの依存middlewareを指定していて、DB_USERなど環境変数化されている部分は、env_from.secret_ref 項のkubernetes_secretからセキュアに参照されます。
同deployment上にもう一つ、cloud-sql-proxyというcontainerも定義されています。
|
1 2 3 4 5 6 7 8 |
container { name = "cloud-sql-proxy" image = "gcr.io/cloudsql-docker/gce-proxy:1.23.1-alpine" command = ["/cloud_sql_proxy", "-instances=${var.common.project}:${var.common.region}:${var.database.instance_name}=tcp:5432"] security_context { run_as_non_root = true } } |
これはMLflowのbackend-store-uri、DBとして利用するCloud SQLへの接続を、Workload Identityとこのproxyによって実現しています。[3]
次に 05_network.tfの resource “kubernetes_ingress” “mlflow” です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
resource "kubernetes_ingress" "mlflow" { depends_on = [ google_container_cluster.primary, google_compute_global_address.mlflow_ip, kubectl_manifest.managed_certificate, ] metadata { name = "mlflow-ingress" annotations = { "kubernetes.io/ingress.allow-http" = "false" "kubernetes.io/ingress.global-static-ip-name" = google_compute_global_address.mlflow_ip.name "networking.gke.io/managed-certificates" = var.network.certificate_name } } spec { rule { http { dynamic "path" { for_each = local.users content { path = "/${path.value}" backend { service_name = "service-${path.value}" service_port = 5000 } } } dynamic "path" { for_each = local.users content { path = "/${path.value}/*" backend { service_name = "service-${path.value}" service_port = 5000 } } } } } } } |
Architectureの説明に、「ユーザからのアクセスはCloud Identity Aware Proxyを通すことで、Whitelist形式のユーザ認証を実現」とあったと思いますが、その定義がこちらです。再度の説明になりますがIAPは、GCPが用意しているOAuth認可によるProxyで、許可されたGoogle Accountでない限りはアクセスできないという仕組みです。GKEクラスタの管理側はUI上でアクセス可能なUserないしGoogle GroupsによるメーリスをIAP-secured Web App Userとして適宜追加することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
data "kubectl_path_documents" "backend_config" { pattern = "./manifests/backend_config.yaml" vars = { backend_config_name = var.iap.backend_config_name secret_name = var.iap.secret_name } } resource "kubectl_manifest" "backend_config" { depends_on = [ google_container_cluster.primary, ] count = length(data.kubectl_path_documents.backend_config.documents) yaml_body = element(data.kubectl_path_documents.backend_config.documents, count.index) } |
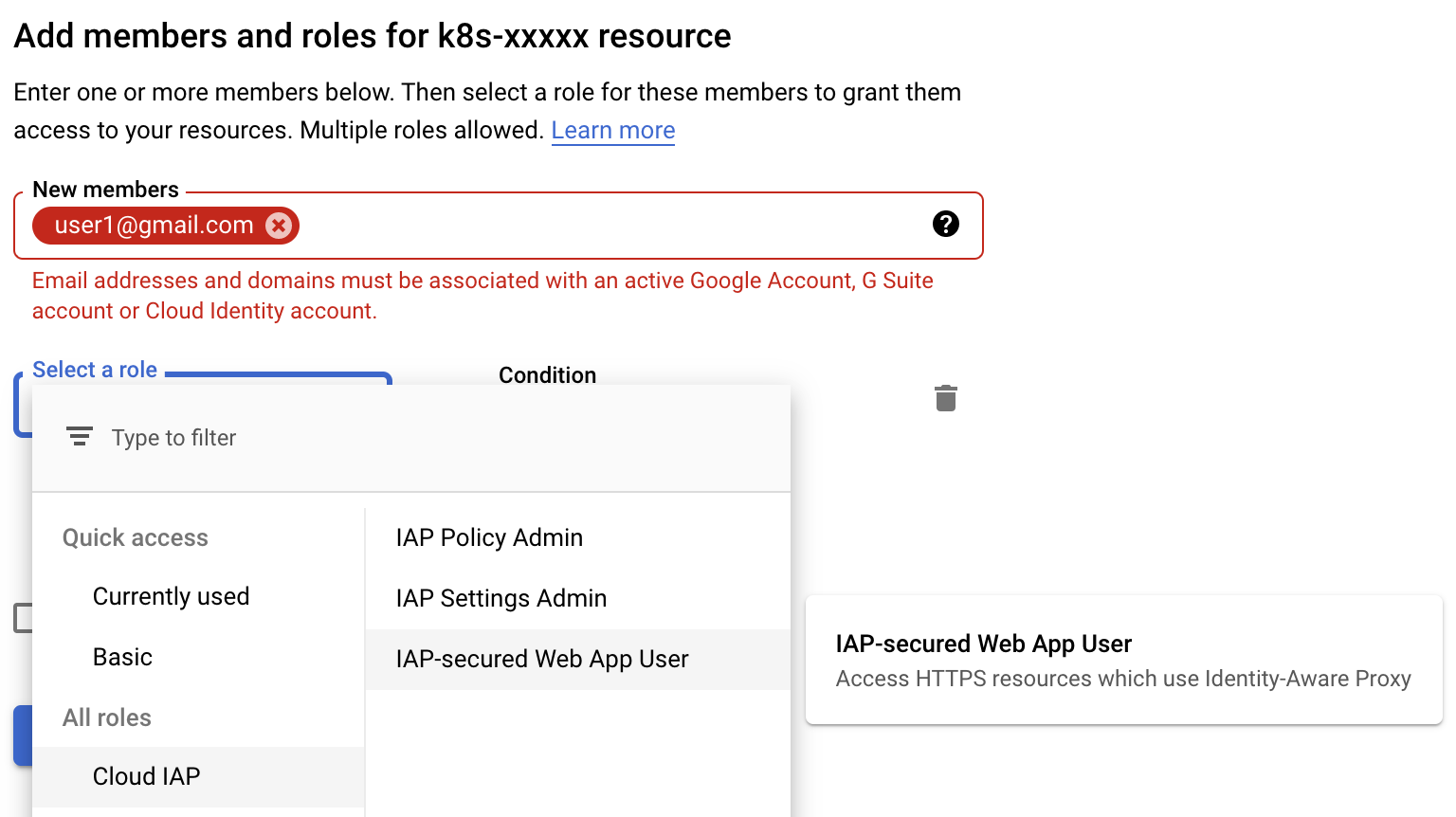
今回のGKEクラスタのKubernetesリソースへのアクセス順はざっくり、Ingress(SSL, LoadBalancing) → Service(IAP) → Node(MLflow Container)ですが、そのKubernetes Service(IAP) に紐付けるために予め作成しておいたOAuth用のclient.jsonをkubernetes backend configに登録しておきます。04_deployment.tfや05_network.tfでは resource “kubernetes_deployment” や resource “kubernetes_ingress” などのTerraform builtinのresourceを用いて定義しましたが、backend configはTerraform由来のresourceが用意されていないため、kubernetes従来のyamlによる定義を行います。これは有志によるkubectlのTerraform Providerを利用していて、Terraformはこのように必要に応じてPluggableにProviderをUserが実装できるのも魅力です。
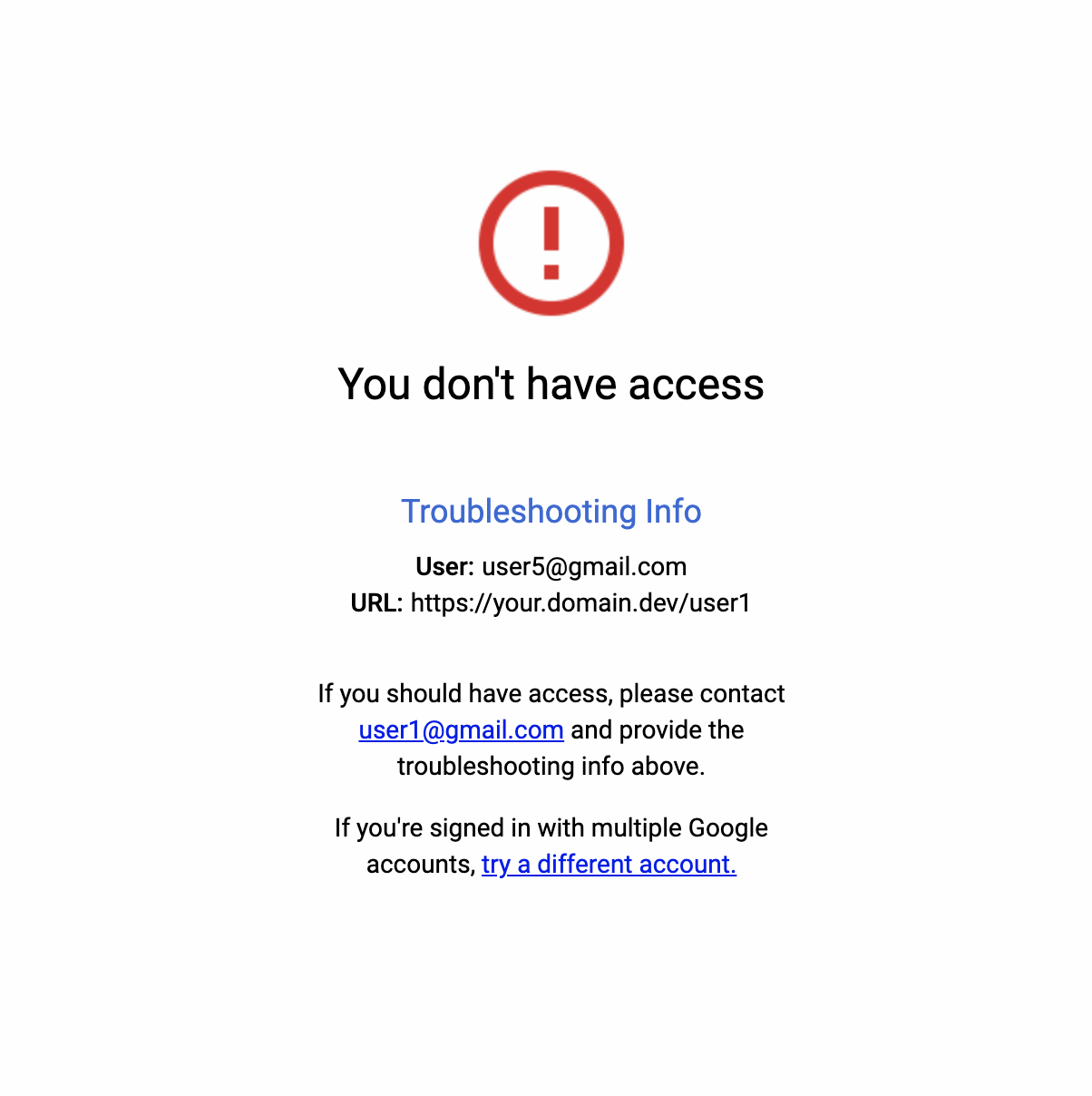
以上でtfファイルの説明は終わりです。さて、そろそろ terraform apply も終わりMLflowクラスタが構築されたか確認してこの記事を締めます。まずは 指定したdomainを含めたURLである $MLFLOW_DOMAIN/user1 にブラウザからアクセスし、MLflowのTop画面が表示されるかを確認しましょう。MLflowの画面ではなく、以下のようなBlocking画面が出たらIAPが働いている証拠なので心配無用です。
https://console.cloud.google.com/security/iap からBackend Services → service-user1 をクリックし、右に現れるメンバー編集UIから今自身がアクセスしているGoogle AccountをIAP-secured Web App Userとしてメンバー追加しましょう。追加できたら反映されるまで一息待ってから再度元のURLにアクセスし、以下のようなMLflowの画面が現れたら成功です。
![]()
実験結果を共有する側のメンバーはGoogle Groupsのメーリスなりでまとめておいて、そのメーリスのアドレスをIAP-secured Web App Userに指定すると、グループに対してアクセス権を付与できるので便利です。共有設定はこれでOKで、ログの飛ばし方を説明します。ブラウザ表示とは別のアクセスルートを辿るため、IAPを許可する情報も新たに設定します。
アクセス用Service Accountの設定
先程TerraformからGCPを操作するためのService Accountを設定しましたが、今度はMLflow ClientからServerにアクセスするためのService Accountを作ります。まずは同じようにIAM -> Service Accounts -> Create service accountと進み、mlflow-k8s という名前で作成します。roleは、ArtifactのUploadのためにStorage Object Creator を付与します。更に、Cloud IAPの設定ページから default/service-user1 に対し、該当のService AccountにIAP-secured Web App User を付与しましょう。
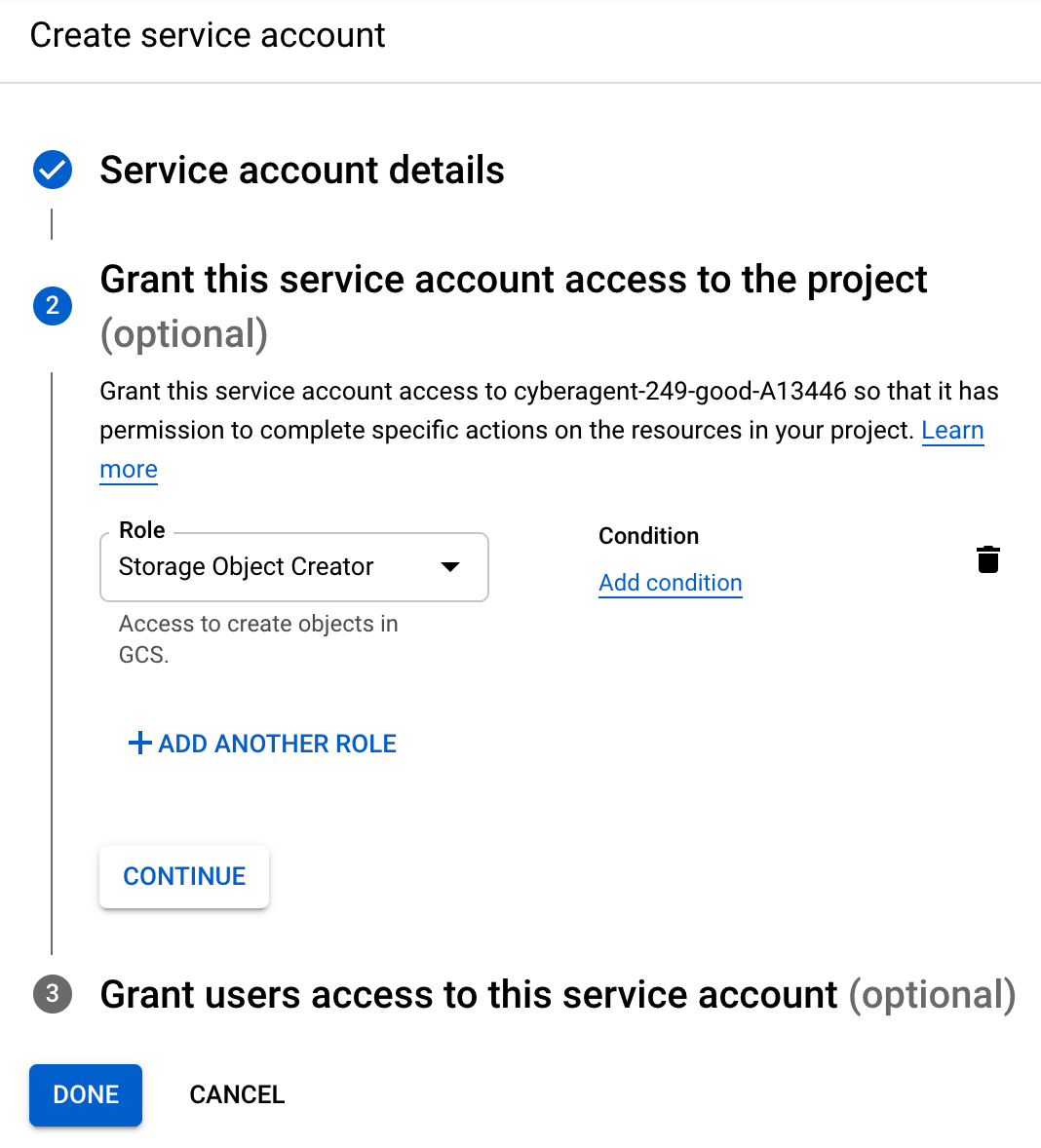
そして同じようにService Account 一覧の︙からManage keys → Add key → Create new keyからJSON形式のPrivate keyをDownloadし、その絶対パスをメモしておきます。
実験ログのトラッキング
ここまでできたらmlflow-k8sのscriptsフォルダに移動します。
|
1 |
cd scripts |
必要情報が3つあるので.env.exampleを参考に、.envに環境変数を追加します。mlflow-k8s rootの.envとは別物なので注意しましょう。
|
1 2 3 4 5 6 7 8 |
cp .env.example .env vi .env ================= MLFLOW_CLIENT_ID=YOUR_MLFLOW_CLIENT.apps.googleusercontent.com MLFLOW_TRACKING_URI=https://${YOUR_MLFLOW_DOMAIN}/user1/ GOOGLE_APPLICATION_CREDENTIALS=YOUR_LOCAL_CREDENTIAL_PATH |
MLFLOW_CLIENT_IDには、terraform設定時にセットしたinfra/secrets/oauth_client_secret.json内のweb.client_idをコピペしましょう。MLFLOW_TRACKING_URIは、今回DeployしたMLflowのURL/user1/に、GOOGLE_APPLICATION_CREDENTIALSは先程メモしておいたToken key.jsonの絶対パスを使います。.envが設定できたら、依存をインストールし、tracking_sample.pyを実行してみます。
|
1 2 3 |
direnv allow . poetry install poetry run python tracking_sample.py |
エラーなく実行されたら[4]、MLflowの画面に戻って、clientからlogが飛ばせているか確認して、この記事を締めたいと思います。tracking_sample.pyを動かす前と比べ、送ったログが表示されていることがわかります。
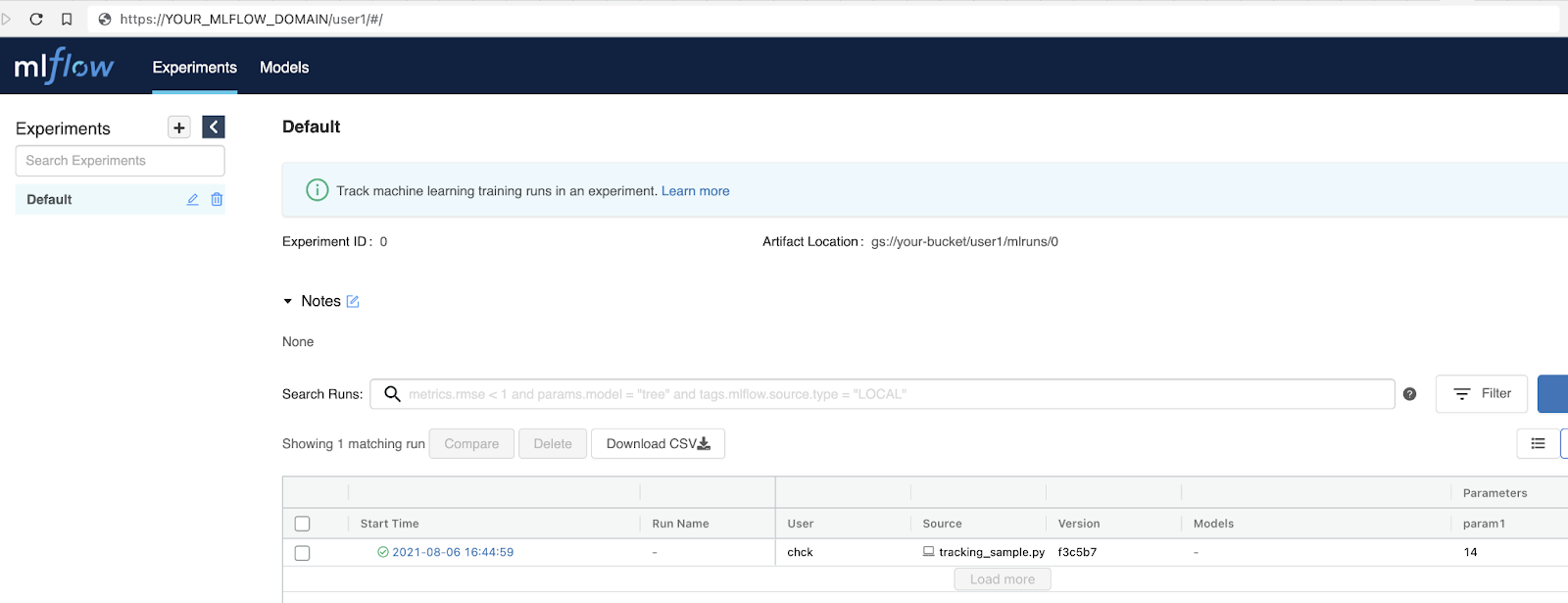
終わりに
今回対象にした実験管理は、ML Lifecycleにおけるほんの一部分です。データやモデル、パイプライン自体の共通管理については次回にご期待ください。この設計は一例なので、各々のライフスタイルに合わせてカスタマイズし、快適な実験生活を送りましょう。なお、ハンズオンをここまでお試し頂いた方はありがとうございました。大体理解できたのでインフラを一旦消したい、という場合は terraform destroyでapplyしたリソースをまとめて削除できます。PyData.Tokyoを通じてAI LabのMLOps事例として本件も解説している、CyberAgent AI Labを支えるCloud実験環境もぜひご覧ください:)
- 前回の記事で少しだけ紹介しました ↩
- 今回はpreemptible nodeで安く長くをテーマにしていますが今年出たばかりのGKE Autopilotも気になります ↩
- この方針だとコネクションがPod数だけ増えて気になる場合は、Service経由で接続するように変更しても良いでしょう(参考: https://unching-star.hatenablog.jp/entry/2019/02/22/000154) ↩
- 権限周りのエラーが出た場合は、GOOGLE_APPLICATION_CREDENTIALSで指定しているService Accountのroleを見直してみてください ↩
Author